 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time (Extended Version)
Feb 02, 2024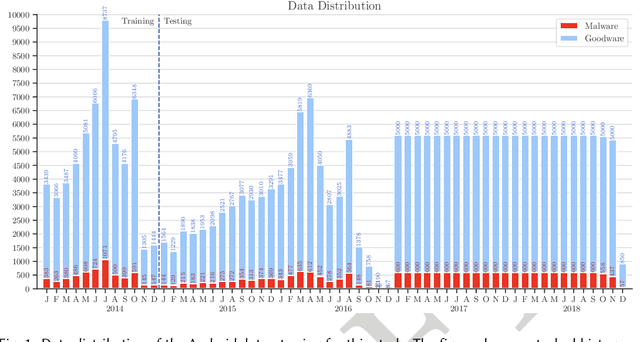
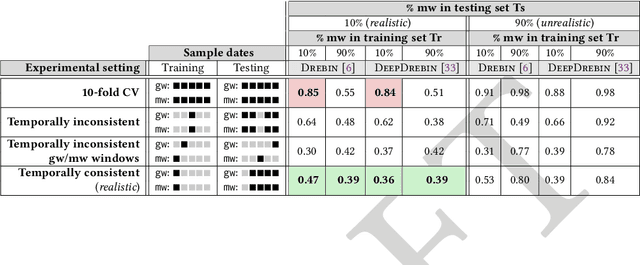
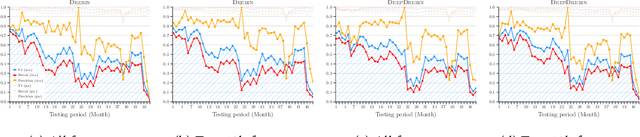
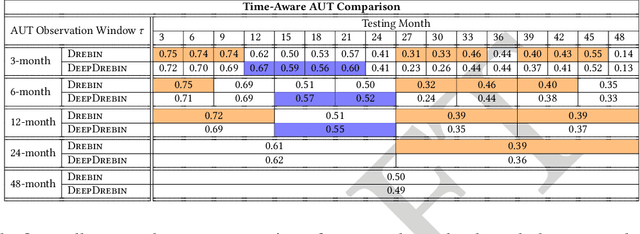
Machine learning (ML) plays a pivotal role in detecting malicious software. Despite the high F1-scores reported in numerous studies reaching upwards of 0.99, the issue is not completely solved. Malware detectors often experience performance decay due to constantly evolving operating systems and attack methods, which can render previously learned knowledge insufficient for accurate decision-making on new inputs. This paper argues that commonly reported results are inflated due to two pervasive sources of experimental bias in the detection task: spatial bias caused by data distributions that are not representative of a real-world deployment; and temporal bias caused by incorrect time splits of data, leading to unrealistic configurations. To address these biases, we introduce a set of constraints for fair experiment design, and propose a new metric, AUT, for classifier robustness in real-world settings. We additionally propose an algorithm designed to tune training data to enhance classifier performance. Finally, we present TESSERACT, an open-source framework for realistic classifier comparison. Our evaluation encompasses both traditional ML and deep learning methods, examining published works on an extensive Android dataset with 259,230 samples over a five-year span. Additionally, we conduct case studies in the Windows PE and PDF domains. Our findings identify the existence of biases in previous studies and reveal that significant performance enhancements are possible through appropriate, periodic tuning. We explore how mitigation strategies may support in achieving a more stable and better performance over time by employing multiple strategies to delay performance decay.
Jigsaw Puzzle: Selective Backdoor Attack to Subvert Malware Classifiers
Feb 11, 2022

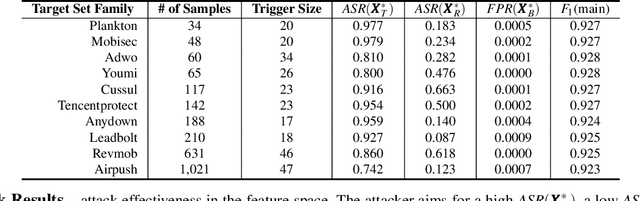
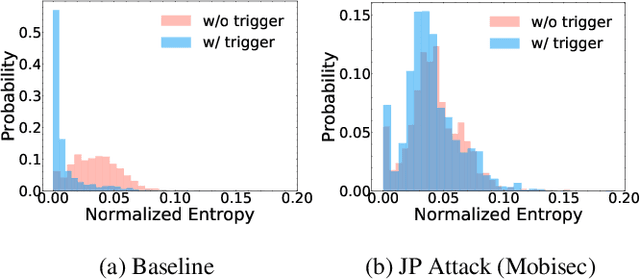
Malware classifiers are subject to training-time exploitation due to the need to regularly retrain using samples collected from the wild. Recent work has demonstrated the feasibility of backdoor attacks against malware classifiers, and yet the stealthiness of such attacks is not well understood. In this paper, we investigate this phenomenon under the clean-label setting (i.e., attackers do not have complete control over the training or labeling process). Empirically, we show that existing backdoor attacks in malware classifiers are still detectable by recent defenses such as MNTD. To improve stealthiness, we propose a new attack, Jigsaw Puzzle (JP), based on the key observation that malware authors have little to no incentive to protect any other authors' malware but their own. As such, Jigsaw Puzzle learns a trigger to complement the latent patterns of the malware author's samples, and activates the backdoor only when the trigger and the latent pattern are pieced together in a sample. We further focus on realizable triggers in the problem space (e.g., software code) using bytecode gadgets broadly harvested from benign software. Our evaluation confirms that Jigsaw Puzzle is effective as a backdoor, remains stealthy against state-of-the-art defenses, and is a threat in realistic settings that depart from reasoning about feature-space only attacks. We conclude by exploring promising approaches to improve backdoor defenses.
Universal Adversarial Perturbations for Malware
Feb 12, 2021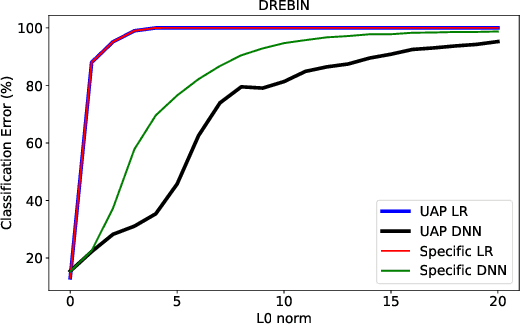

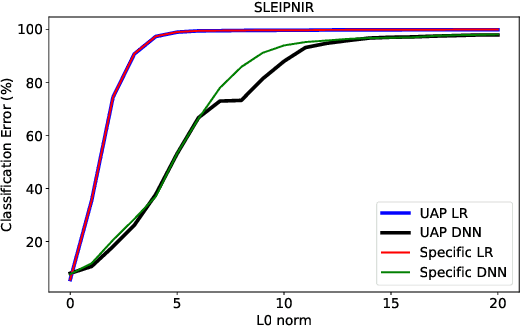
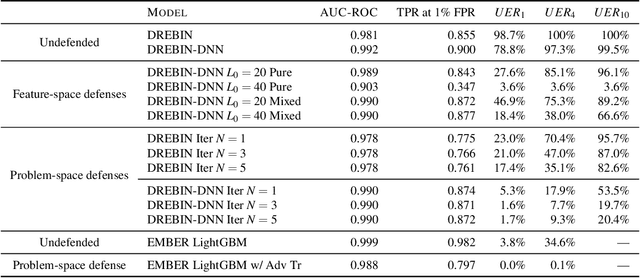
Machine learning classification models are vulnerable to adversarial examples -- effective input-specific perturbations that can manipulate the model's output. Universal Adversarial Perturbations (UAPs), which identify noisy patterns that generalize across the input space, allow the attacker to greatly scale up the generation of these adversarial examples. Although UAPs have been explored in application domains beyond computer vision, little is known about their properties and implications in the specific context of realizable attacks, such as malware, where attackers must reason about satisfying challenging problem-space constraints. In this paper, we explore the challenges and strengths of UAPs in the context of malware classification. We generate sequences of problem-space transformations that induce UAPs in the corresponding feature-space embedding and evaluate their effectiveness across threat models that consider a varying degree of realistic attacker knowledge. Additionally, we propose adversarial training-based mitigations using knowledge derived from the problem-space transformations, and compare against alternative feature-space defenses. Our experiments limit the effectiveness of a white box Android evasion attack to ~20 % at the cost of 3 % TPR at 1 % FPR. We additionally show how our method can be adapted to more restrictive application domains such as Windows malware. We observe that while adversarial training in the feature space must deal with large and often unconstrained regions, UAPs in the problem space identify specific vulnerabilities that allow us to harden a classifier more effectively, shifting the challenges and associated cost of identifying new universal adversarial transformations back to the attacker.
Dos and Don'ts of Machine Learning in Computer Security
Oct 19, 2020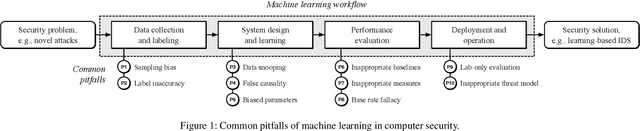
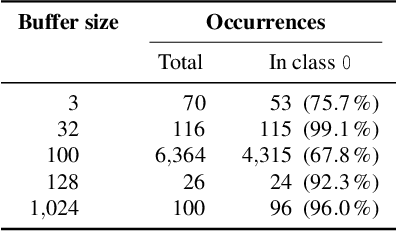
With the growing processing power of computing systems and the increasing availability of massive datasets, machine learning algorithms have led to major breakthroughs in many different areas. This development has influenced computer security, spawning a series of work on learning-based security systems, such as for malware detection, vulnerability discovery, and binary code analysis. Despite great potential, machine learning in security is prone to subtle pitfalls that undermine its performance and render learning-based systems potentially unsuitable for security tasks and practical deployment. In this paper, we look at this problem with critical eyes. First, we identify common pitfalls in the design, implementation, and evaluation of learning-based security systems. We conduct a longitudinal study of 30 papers from top-tier security conferences within the past 10 years, confirming that these pitfalls are widespread in the current security literature. In an empirical analysis, we further demonstrate how individual pitfalls can lead to unrealistic performance and interpretations, obstructing the understanding of the security problem at hand. As a remedy, we derive a list of actionable recommendations to support researchers and our community in avoiding pitfalls, promoting a sound design, development, evaluation, and deployment of learning-based systems for computer security.
Intriguing Properties of Adversarial ML Attacks in the Problem Space
Nov 05, 2019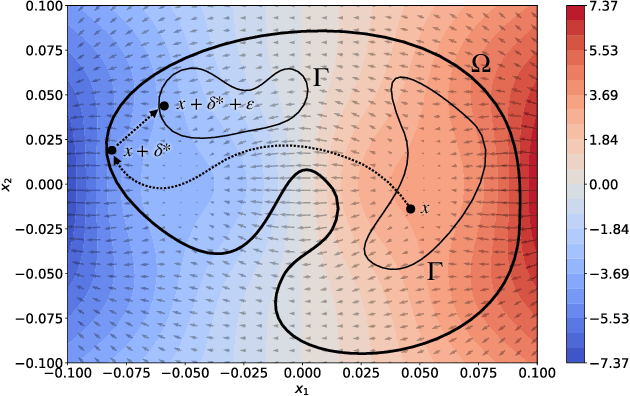
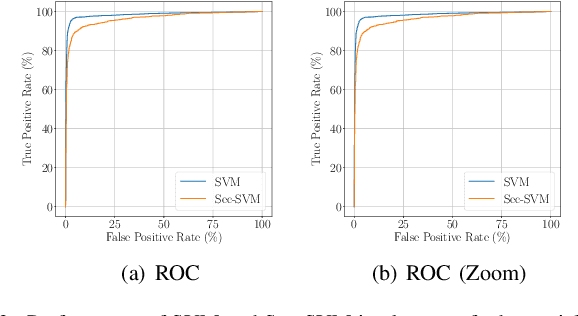
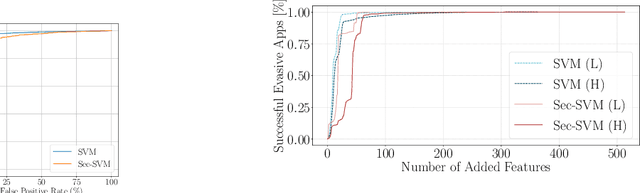
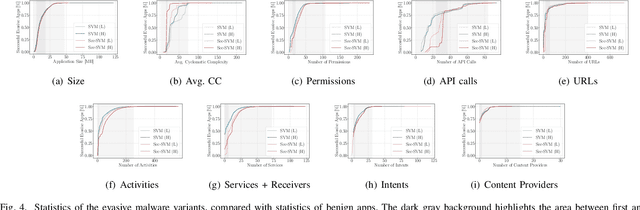
Recent research efforts on adversarial ML have investigated problem-space attacks, focusing on the generation of real evasive objects in domains where, unlike images, there is no clear inverse mapping to the feature space (e.g., software). However, the design, comparison, and real-world implications of problem-space attacks remain underexplored. This paper makes two major contributions. First, we propose a general formalization for adversarial ML evasion attacks in the problem-space, which includes the definition of a comprehensive set of constraints on available transformations, preserved semantics, absent artifacts, and plausibility. We shed light on the relationship between feature space and problem space, and we introduce the concept of side-effect features as the by-product of the inverse feature-mapping problem. This enables us to define and prove necessary and sufficient conditions for the existence of problem-space attacks. We further demonstrate the expressive power of our formalization by using it to describe several attacks from related literature across different domains. Second, building on our general formalization, we propose a novel problem-space attack on Android malware that overcomes past limitations in terms of semantics and artifacts. Experiments on a dataset with 170K Android apps from 2017 and 2018 show the practical feasibility of evading a state-of-the-art malware classifier, DREBIN, along with its hardened version, Sec-SVM. Our results demonstrate that "adversarial-malware as a service" is a realistic threat, as we automatically generate thousands of realistic and inconspicuous adversarial applications at scale, where on average it takes only a few minutes to generate an adversarial app. Our formalization of problem-space attacks paves the way to more principled research in this domain.
TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time
Jul 20, 2018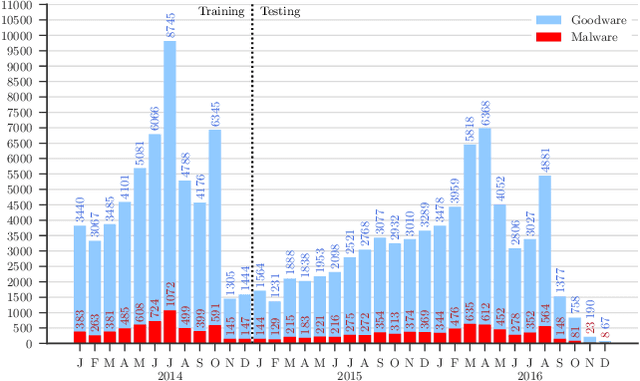
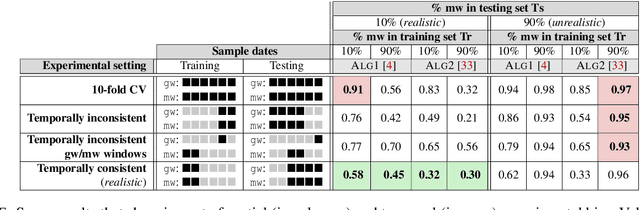
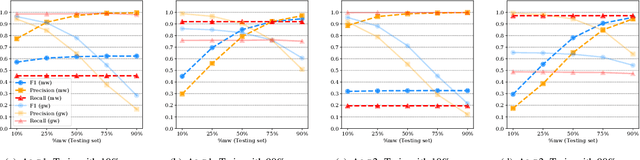
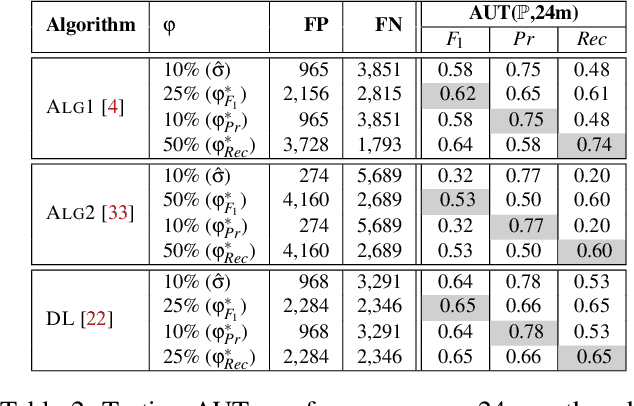
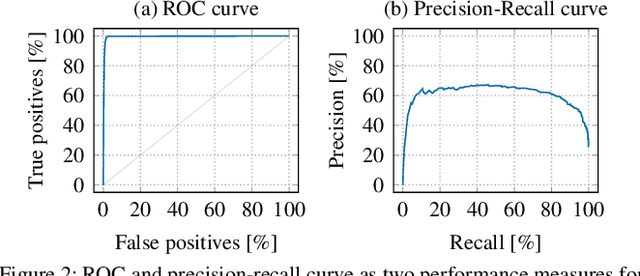
Academic research on machine learning-based malware classification appears to leave very little room for improvement, boasting $F_1$ performance figures of up to 0.99. Is the problem solved? In this paper, we argue that there is an endemic issue of inflated results due to two pervasive sources of experimental bias: spatial bias is caused by distributions of training and testing data not representative of a real-world deployment; temporal bias is caused by incorrect splits of training and testing sets (e.g., in cross-validation) leading to impossible configurations. To overcome this issue, we propose a set of space and time constraints for experiment design. Furthermore, we introduce a new metric that summarizes the performance of a classifier over time, i.e., its expected robustness in a real-world setting. Finally, we present an algorithm to tune the performance of a given classifier. We have implemented our solutions in TESSERACT, an open source evaluation framework that allows a fair comparison of malware classifiers in a realistic setting. We used TESSERACT to evaluate two well-known malware classifiers from the literature on a dataset of 129K applications, demonstrating the distortion of results due to experimental bias and showcasing significant improvements from tuning.