 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Local LLM Agents for Linux Privilege Escalation with Verifiable Rewards
Mar 18, 2026LLM agents are increasingly relevant to research domains such as vulnerability discovery. Yet, the strongest systems remain closed and cloud-only, making them resource-intensive, difficult to reproduce, and unsuitable for work involving proprietary code or sensitive data. Consequently, there is an urgent need for small, local models that can perform security tasks under strict resource budgets, but methods for developing them remain underexplored. In this paper, we address this gap by proposing a two-stage post-training pipeline. We focus on the problem of Linux privilege escalation, where success is automatically verifiable and the task requires multi-step interactive reasoning. Using an experimental setup that prevents data leakage, we post-train a 4B model in two stages: supervised fine-tuning on traces from procedurally generated privilege-escalation environments, followed by reinforcement learning with verifiable rewards. On a held-out benchmark of 12 Linux privilege-escalation scenarios, supervised fine-tuning alone more than doubles the baseline success rate at 20 rounds, and reinforcement learning further lifts our resulting model, PrivEsc-LLM, to 95.8%, nearly matching Claude Opus 4.6 at 97.5%. At the same time, the expected inference cost per successful escalation is reduced by over 100x.
TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time (Extended Version)
Feb 02, 2024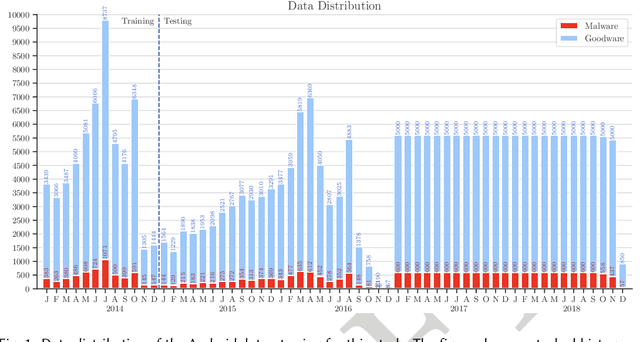
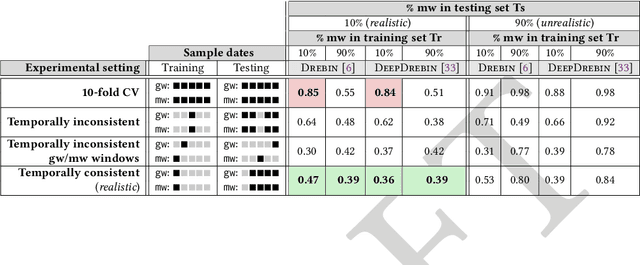
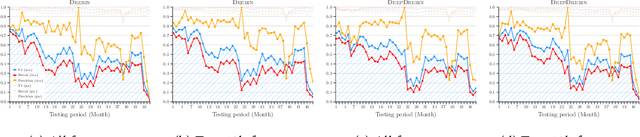
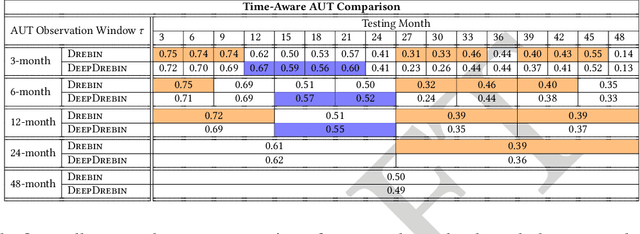
Machine learning (ML) plays a pivotal role in detecting malicious software. Despite the high F1-scores reported in numerous studies reaching upwards of 0.99, the issue is not completely solved. Malware detectors often experience performance decay due to constantly evolving operating systems and attack methods, which can render previously learned knowledge insufficient for accurate decision-making on new inputs. This paper argues that commonly reported results are inflated due to two pervasive sources of experimental bias in the detection task: spatial bias caused by data distributions that are not representative of a real-world deployment; and temporal bias caused by incorrect time splits of data, leading to unrealistic configurations. To address these biases, we introduce a set of constraints for fair experiment design, and propose a new metric, AUT, for classifier robustness in real-world settings. We additionally propose an algorithm designed to tune training data to enhance classifier performance. Finally, we present TESSERACT, an open-source framework for realistic classifier comparison. Our evaluation encompasses both traditional ML and deep learning methods, examining published works on an extensive Android dataset with 259,230 samples over a five-year span. Additionally, we conduct case studies in the Windows PE and PDF domains. Our findings identify the existence of biases in previous studies and reveal that significant performance enhancements are possible through appropriate, periodic tuning. We explore how mitigation strategies may support in achieving a more stable and better performance over time by employing multiple strategies to delay performance decay.
Misleading Deep-Fake Detection with GAN Fingerprints
May 25, 2022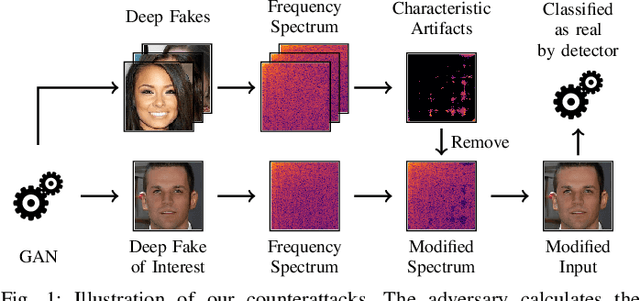
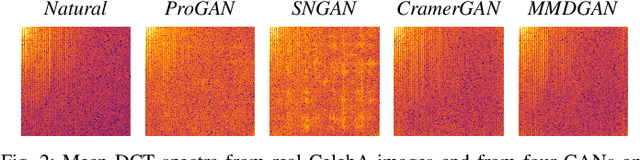
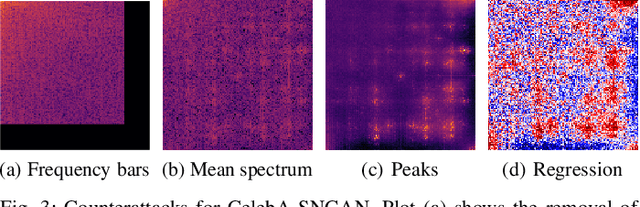

Generative adversarial networks (GANs) have made remarkable progress in synthesizing realistic-looking images that effectively outsmart even humans. Although several detection methods can recognize these deep fakes by checking for image artifacts from the generation process, multiple counterattacks have demonstrated their limitations. These attacks, however, still require certain conditions to hold, such as interacting with the detection method or adjusting the GAN directly. In this paper, we introduce a novel class of simple counterattacks that overcomes these limitations. In particular, we show that an adversary can remove indicative artifacts, the GAN fingerprint, directly from the frequency spectrum of a generated image. We explore different realizations of this removal, ranging from filtering high frequencies to more nuanced frequency-peak cleansing. We evaluate the performance of our attack with different detection methods, GAN architectures, and datasets. Our results show that an adversary can often remove GAN fingerprints and thus evade the detection of generated images.
Against All Odds: Winning the Defense Challenge in an Evasion Competition with Diversification
Oct 19, 2020
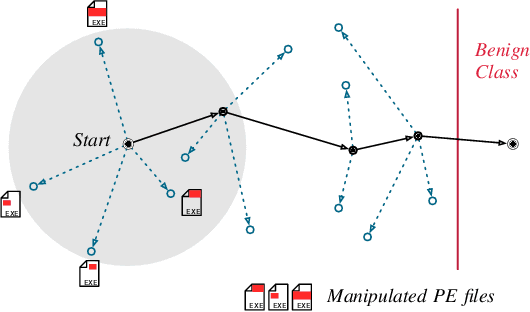
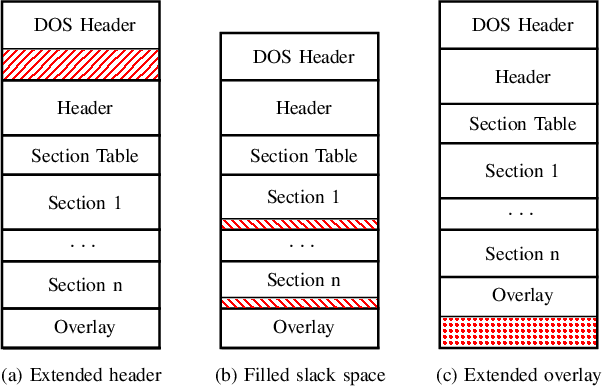
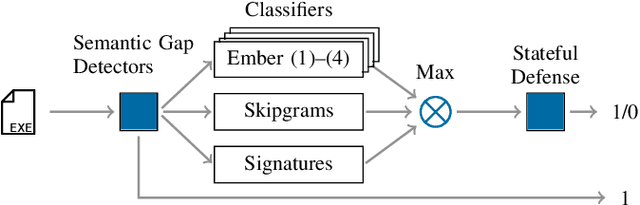
Machine learning-based systems for malware detection operate in a hostile environment. Consequently, adversaries will also target the learning system and use evasion attacks to bypass the detection of malware. In this paper, we outline our learning-based system PEberus that got the first place in the defender challenge of the Microsoft Evasion Competition, resisting a variety of attacks from independent attackers. Our system combines multiple, diverse defenses: we address the semantic gap, use various classification models, and apply a stateful defense. This competition gives us the unique opportunity to examine evasion attacks under a realistic scenario. It also highlights that existing machine learning methods can be hardened against attacks by thoroughly analyzing the attack surface and implementing concepts from adversarial learning. Our defense can serve as an additional baseline in the future to strengthen the research on secure learning.
Dos and Don'ts of Machine Learning in Computer Security
Oct 19, 2020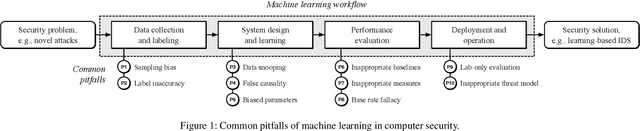
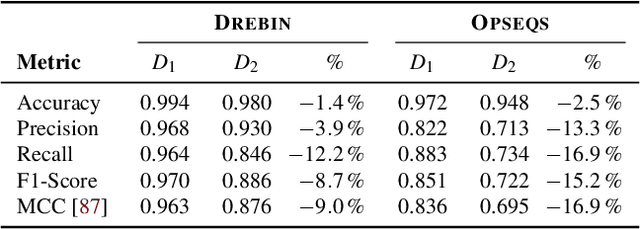
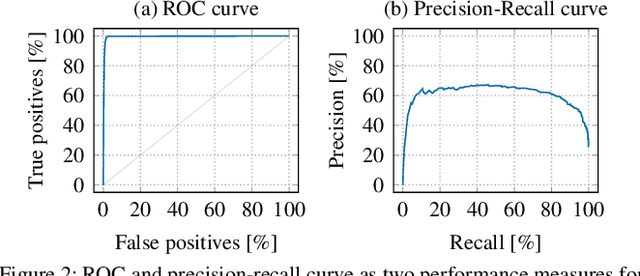
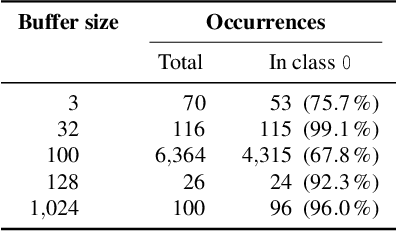
With the growing processing power of computing systems and the increasing availability of massive datasets, machine learning algorithms have led to major breakthroughs in many different areas. This development has influenced computer security, spawning a series of work on learning-based security systems, such as for malware detection, vulnerability discovery, and binary code analysis. Despite great potential, machine learning in security is prone to subtle pitfalls that undermine its performance and render learning-based systems potentially unsuitable for security tasks and practical deployment. In this paper, we look at this problem with critical eyes. First, we identify common pitfalls in the design, implementation, and evaluation of learning-based security systems. We conduct a longitudinal study of 30 papers from top-tier security conferences within the past 10 years, confirming that these pitfalls are widespread in the current security literature. In an empirical analysis, we further demonstrate how individual pitfalls can lead to unrealistic performance and interpretations, obstructing the understanding of the security problem at hand. As a remedy, we derive a list of actionable recommendations to support researchers and our community in avoiding pitfalls, promoting a sound design, development, evaluation, and deployment of learning-based systems for computer security.
Don't Paint It Black: White-Box Explanations for Deep Learning in Computer Security
Jun 06, 2019
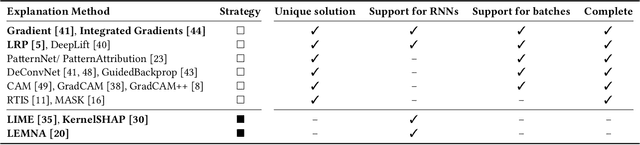


Deep learning is increasingly used as a basic building block of security systems. Unfortunately, deep neural networks are hard to interpret, and their decision process is opaque to the practitioner. Recent work has started to address this problem by considering black-box explanations for deep learning in computer security (CCS'18). The underlying explanation methods, however, ignore the structure of neural networks and thus omit crucial information for analyzing the decision process. In this paper, we investigate white-box explanations and systematically compare them with current black-box approaches. In an extensive evaluation with learning-based systems for malware detection and vulnerability discovery, we demonstrate that white-box explanations are more concise, sparse, complete and efficient than black-box approaches. As a consequence, we generally recommend the use of white-box explanations if access to the employed neural network is available, which usually is the case for stand-alone systems for malware detection, binary analysis, and vulnerability discovery.
Fraternal Twins: Unifying Attacks on Machine Learning and Digital Watermarking
Mar 16, 2017


Machine learning is increasingly used in security-critical applications, such as autonomous driving, face recognition and malware detection. Most learning methods, however, have not been designed with security in mind and thus are vulnerable to different types of attacks. This problem has motivated the research field of adversarial machine learning that is concerned with attacking and defending learning methods. Concurrently, a different line of research has tackled a very similar problem: In digital watermarking information are embedded in a signal in the presence of an adversary. As a consequence, this research field has also extensively studied techniques for attacking and defending watermarking methods. The two research communities have worked in parallel so far, unnoticeably developing similar attack and defense strategies. This paper is a first effort to bring these communities together. To this end, we present a unified notation of black-box attacks against machine learning and watermarking that reveals the similarity of both settings. To demonstrate the efficacy of this unified view, we apply concepts from watermarking to machine learning and vice versa. We show that countermeasures from watermarking can mitigate recent model-extraction attacks and, similarly, that techniques for hardening machine learning can fend off oracle attacks against watermarks. Our work provides a conceptual link between two research fields and thereby opens novel directions for improving the security of both, machine learning and digital watermarking.