 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLens: Contrastive Captioning of Binary Functions using Ensemble Embedding
Sep 12, 2024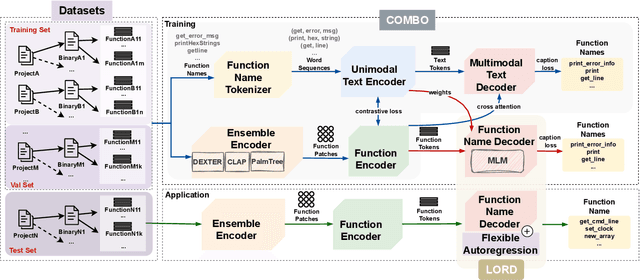

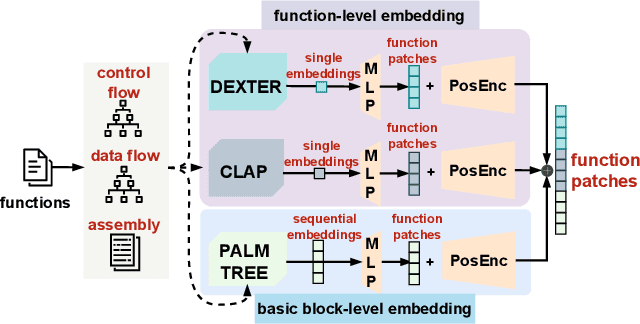

Function names can greatly aid human reverse engineers, which has spurred development of machine learning-based approaches to predicting function names in stripped binaries. Much current work in this area now uses transformers, applying a metaphor of machine translation from code to function names. Still, function naming models face challenges in generalizing to projects completely unrelated to the training set. In this paper, we take a completely new approach by transferring advances in automated image captioning to the domain of binary reverse engineering, such that different parts of a binary function can be associated with parts of its name. We propose BLens, which combines multiple binary function embeddings into a new ensemble representation, aligns it with the name representation latent space via a contrastive learning approach, and generates function names with a transformer architecture tailored for function names. In our experiments, we demonstrate that BLens significantly outperforms the state of the art. In the usual setting of splitting per binary, we achieve an $F_1$ score of 0.77 compared to 0.67. Moreover, in the cross-project setting, which emphasizes generalizability, we achieve an $F_1$ score of 0.46 compared to 0.29.
TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time (Extended Version)
Feb 02, 2024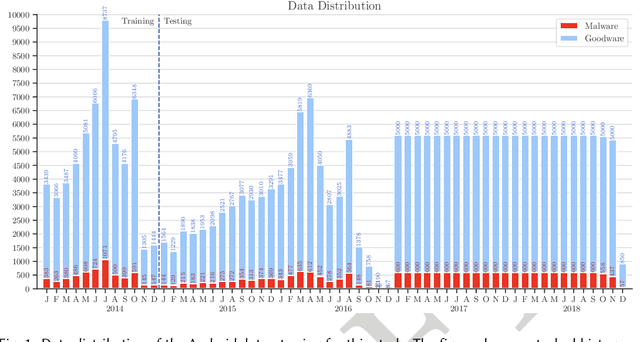
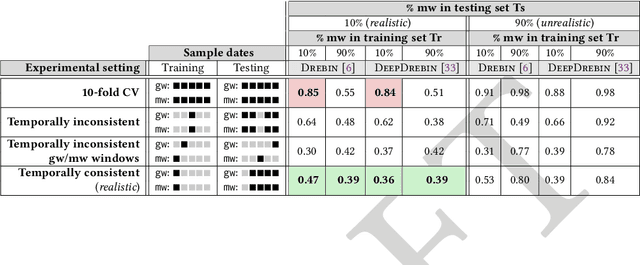
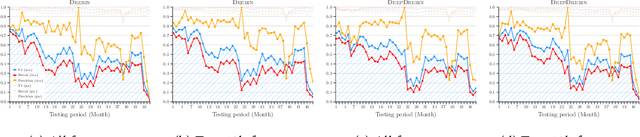
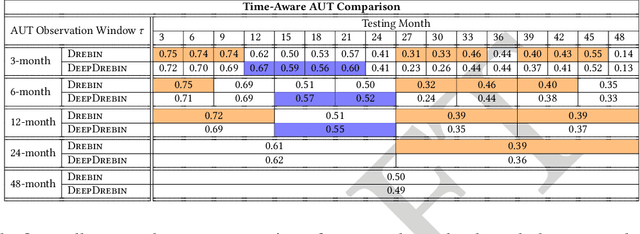
Machine learning (ML) plays a pivotal role in detecting malicious software. Despite the high F1-scores reported in numerous studies reaching upwards of 0.99, the issue is not completely solved. Malware detectors often experience performance decay due to constantly evolving operating systems and attack methods, which can render previously learned knowledge insufficient for accurate decision-making on new inputs. This paper argues that commonly reported results are inflated due to two pervasive sources of experimental bias in the detection task: spatial bias caused by data distributions that are not representative of a real-world deployment; and temporal bias caused by incorrect time splits of data, leading to unrealistic configurations. To address these biases, we introduce a set of constraints for fair experiment design, and propose a new metric, AUT, for classifier robustness in real-world settings. We additionally propose an algorithm designed to tune training data to enhance classifier performance. Finally, we present TESSERACT, an open-source framework for realistic classifier comparison. Our evaluation encompasses both traditional ML and deep learning methods, examining published works on an extensive Android dataset with 259,230 samples over a five-year span. Additionally, we conduct case studies in the Windows PE and PDF domains. Our findings identify the existence of biases in previous studies and reveal that significant performance enhancements are possible through appropriate, periodic tuning. We explore how mitigation strategies may support in achieving a more stable and better performance over time by employing multiple strategies to delay performance decay.
XFL: eXtreme Function Labeling
Jul 28, 2021

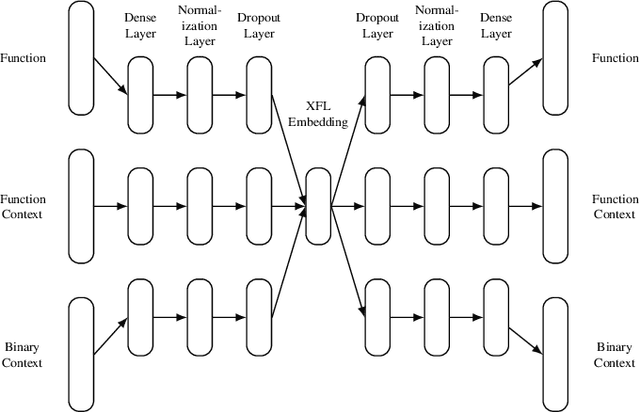

Reverse engineers would benefit from identifiers like function names, but these are usually unavailable in binaries. Training a machine learning model to predict function names automatically is promising but fundamentally hard due to the enormous number of classes. In this paper, we introduce eXtreme Function Labeling (XFL), an extreme multi-label learning approach to selecting appropriate labels for binary functions. XFL splits function names into tokens, treating each as an informative label akin to the problem of tagging texts in natural language. To capture the semantics of binary code, we introduce DEXTER, a novel function embedding that combines static analysis-based features with local context from the call graph and global context from the entire binary. We demonstrate that XFL outperforms state-of-the-art approaches to function labeling on a dataset of over 10,000 binaries from the Debian project, achieving a precision of 82.5%. We also study combinations of XFL with different published embeddings for binary functions and show that DEXTER consistently improves over the state of the art in information gain. As a result, we are able to show that binary function labeling is best phrased in terms of multi-label learning, and that binary function embeddings benefit from moving beyond just learning from syntax.
TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time
Jul 20, 2018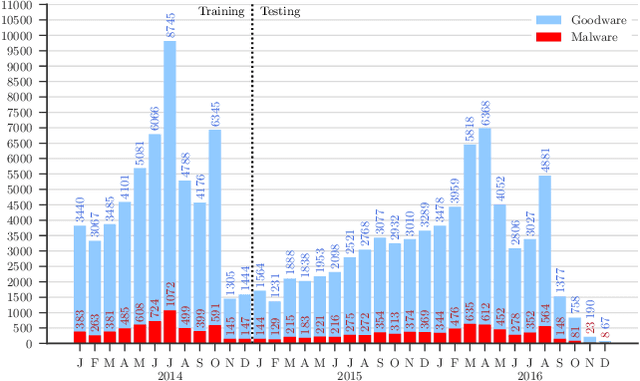
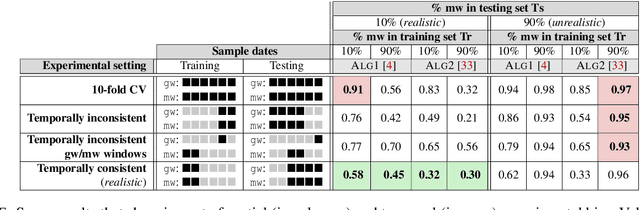
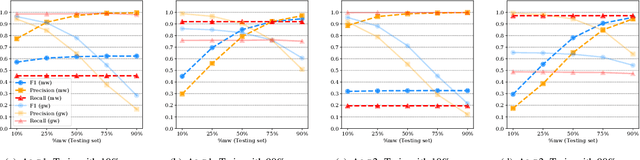
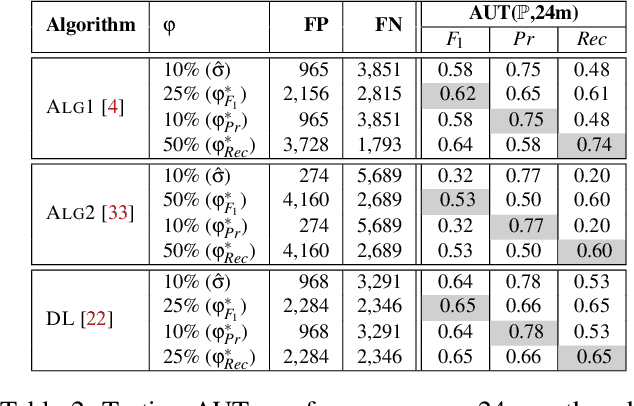
Academic research on machine learning-based malware classification appears to leave very little room for improvement, boasting $F_1$ performance figures of up to 0.99. Is the problem solved? In this paper, we argue that there is an endemic issue of inflated results due to two pervasive sources of experimental bias: spatial bias is caused by distributions of training and testing data not representative of a real-world deployment; temporal bias is caused by incorrect splits of training and testing sets (e.g., in cross-validation) leading to impossible configurations. To overcome this issue, we propose a set of space and time constraints for experiment design. Furthermore, we introduce a new metric that summarizes the performance of a classifier over time, i.e., its expected robustness in a real-world setting. Finally, we present an algorithm to tune the performance of a given classifier. We have implemented our solutions in TESSERACT, an open source evaluation framework that allows a fair comparison of malware classifiers in a realistic setting. We used TESSERACT to evaluate two well-known malware classifiers from the literature on a dataset of 129K applications, demonstrating the distortion of results due to experimental bias and showcasing significant improvements from tuning.