 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time
Paper and Code
Jul 20, 2018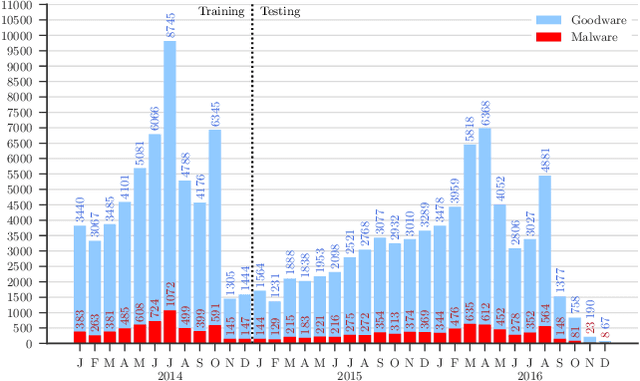
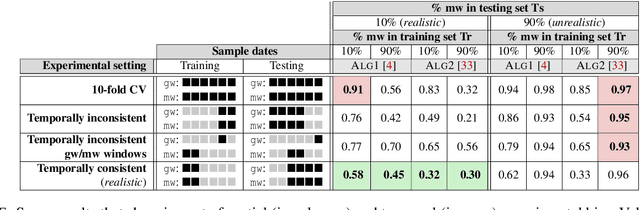
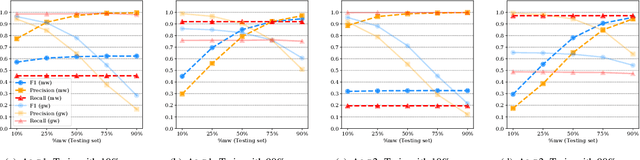
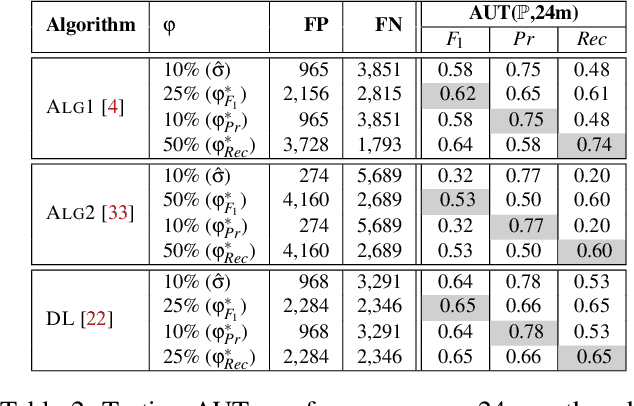
Academic research on machine learning-based malware classification appears to leave very little room for improvement, boasting $F_1$ performance figures of up to 0.99. Is the problem solved? In this paper, we argue that there is an endemic issue of inflated results due to two pervasive sources of experimental bias: spatial bias is caused by distributions of training and testing data not representative of a real-world deployment; temporal bias is caused by incorrect splits of training and testing sets (e.g., in cross-validation) leading to impossible configurations. To overcome this issue, we propose a set of space and time constraints for experiment design. Furthermore, we introduce a new metric that summarizes the performance of a classifier over time, i.e., its expected robustness in a real-world setting. Finally, we present an algorithm to tune the performance of a given classifier. We have implemented our solutions in TESSERACT, an open source evaluation framework that allows a fair comparison of malware classifiers in a realistic setting. We used TESSERACT to evaluate two well-known malware classifiers from the literature on a dataset of 129K applications, demonstrating the distortion of results due to experimental bias and showcasing significant improvements from tuning.