 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRMD: Deep Reinforcement Learning for Malware Detection under Concept Drift
Aug 26, 2025Malware detection in real-world settings must deal with evolving threats, limited labeling budgets, and uncertain predictions. Traditional classifiers, without additional mechanisms, struggle to maintain performance under concept drift in malware domains, as their supervised learning formulation cannot optimize when to defer decisions to manual labeling and adaptation. Modern malware detection pipelines combine classifiers with monthly active learning (AL) and rejection mechanisms to mitigate the impact of concept drift. In this work, we develop a novel formulation of malware detection as a one-step Markov Decision Process and train a deep reinforcement learning (DRL) agent, simultaneously optimizing sample classification performance and rejecting high-risk samples for manual labeling. We evaluated the joint detection and drift mitigation policy learned by the DRL-based Malware Detection (DRMD) agent through time-aware evaluations on Android malware datasets subject to realistic drift requiring multi-year performance stability. The policies learned under these conditions achieve a higher Area Under Time (AUT) performance compared to standard classification approaches used in the domain, showing improved resilience to concept drift. Specifically, the DRMD agent achieved a $5.18\pm5.44$, $14.49\pm12.86$, and $10.06\pm10.81$ average AUT performance improvement for the classification only, classification with rejection, and classification with rejection and AL settings, respectively. Our results demonstrate for the first time that DRL can facilitate effective malware detection and improved resiliency to concept drift in the dynamic environment of the Android malware domain.
KnowML: Improving Generalization of ML-NIDS with Attack Knowledge Graphs
Jun 24, 2025Despite extensive research on Machine Learning-based Network Intrusion Detection Systems (ML-NIDS), their capability to detect diverse attack variants remains uncertain. Prior studies have largely relied on homogeneous datasets, which artificially inflate performance scores and offer a false sense of security. Designing systems that can effectively detect a wide range of attack variants remains a significant challenge. The progress of ML-NIDS continues to depend heavily on human expertise, which can embed subjective judgments of system designers into the model, potentially hindering its ability to generalize across diverse attack types. To address this gap, we propose KnowML, a framework for knowledge-guided machine learning that integrates attack knowledge into ML-NIDS. KnowML systematically explores the threat landscape by leveraging Large Language Models (LLMs) to perform automated analysis of attack implementations. It constructs a unified Knowledge Graph (KG) of attack strategies, on which it applies symbolic reasoning to generate KG-Augmented Input, embedding domain knowledge directly into the design process of ML-NIDS. We evaluate KnowML on 28 realistic attack variants, of which 10 are newly collected for this study. Our findings reveal that baseline ML-NIDS models fail to detect several variants entirely, achieving F1 scores as low as 0 %. In contrast, our knowledge-guided approach achieves up to 99 % F1 score while maintaining a False Positive Rate below 0.1 %.
Unveiling ECC Vulnerabilities: LSTM Networks for Operation Recognition in Side-Channel Attacks
Feb 24, 2025We propose a novel approach for performing side-channel attacks on elliptic curve cryptography. Unlike previous approaches and inspired by the ``activity detection'' literature, we adopt a long-short-term memory (LSTM) neural network to analyze a power trace and identify patterns of operation in the scalar multiplication algorithm performed during an ECDSA signature, that allows us to recover bits of the ephemeral key, and thus retrieve the signer's private key. Our approach is based on the fact that modular reductions are conditionally performed by micro-ecc and depend on key bits. We evaluated the feasibility and reproducibility of our attack through experiments in both simulated and real implementations. We demonstrate the effectiveness of our attack by implementing it on a real target device, an STM32F415 with the micro-ecc library, and successfully compromise it. Furthermore, we show that current countermeasures, specifically the coordinate randomization technique, are not sufficient to protect against side channels. Finally, we suggest other approaches that may be implemented to thwart our attack.
How to Train your Antivirus: RL-based Hardening through the Problem-Space
Feb 29, 2024



ML-based malware detection on dynamic analysis reports is vulnerable to both evasion and spurious correlations. In this work, we investigate a specific ML architecture employed in the pipeline of a widely-known commercial antivirus company, with the goal to harden it against adversarial malware. Adversarial training, the sole defensive technique that can confer empirical robustness, is not applicable out of the box in this domain, for the principal reason that gradient-based perturbations rarely map back to feasible problem-space programs. We introduce a novel Reinforcement Learning approach for constructing adversarial examples, a constituent part of adversarially training a model against evasion. Our approach comes with multiple advantages. It performs modifications that are feasible in the problem-space, and only those; thus it circumvents the inverse mapping problem. It also makes possible to provide theoretical guarantees on the robustness of the model against a particular set of adversarial capabilities. Our empirical exploration validates our theoretical insights, where we can consistently reach 0\% Attack Success Rate after a few adversarial retraining iterations.
Unraveling the Key of Machine Learning Solutions for Android Malware Detection
Feb 05, 2024
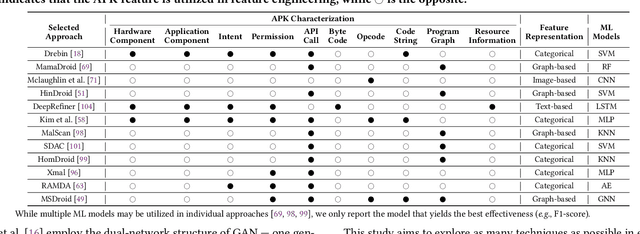


Android malware detection serves as the front line against malicious apps. With the rapid advancement of machine learning (ML), ML-based Android malware detection has attracted increasing attention due to its capability of automatically capturing malicious patterns from Android APKs. These learning-driven methods have reported promising results in detecting malware. However, the absence of an in-depth analysis of current research progress makes it difficult to gain a holistic picture of the state of the art in this area. This paper presents a comprehensive investigation to date into ML-based Android malware detection with empirical and quantitative analysis. We first survey the literature, categorizing contributions into a taxonomy based on the Android feature engineering and ML modeling pipeline. Then, we design a general-propose framework for ML-based Android malware detection, re-implement 12 representative approaches from different research communities, and evaluate them from three primary dimensions, i.e., effectiveness, robustness, and efficiency. The evaluation reveals that ML-based approaches still face open challenges and provides insightful findings like more powerful ML models are not the silver bullet for designing better malware detectors. We further summarize our findings and put forth recommendations to guide future research.
TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time (Extended Version)
Feb 02, 2024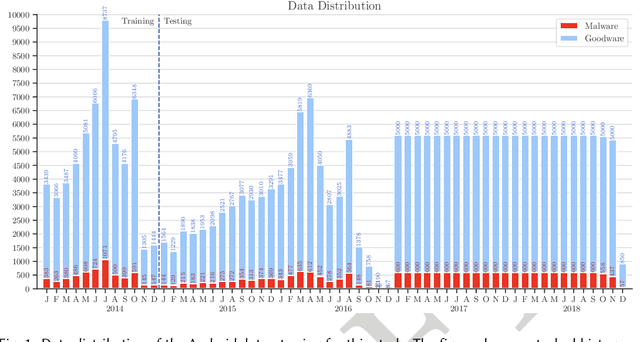
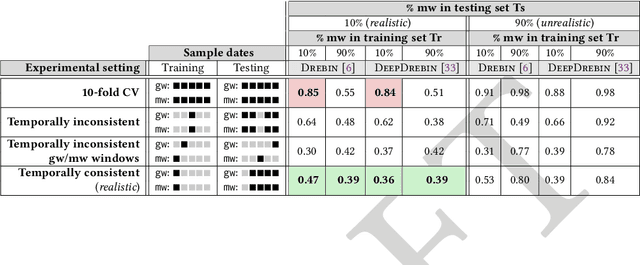
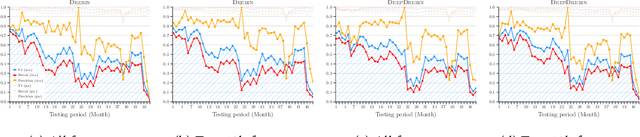
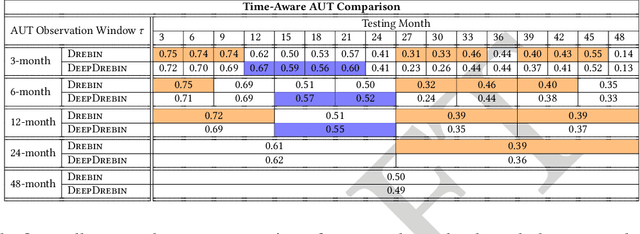
Machine learning (ML) plays a pivotal role in detecting malicious software. Despite the high F1-scores reported in numerous studies reaching upwards of 0.99, the issue is not completely solved. Malware detectors often experience performance decay due to constantly evolving operating systems and attack methods, which can render previously learned knowledge insufficient for accurate decision-making on new inputs. This paper argues that commonly reported results are inflated due to two pervasive sources of experimental bias in the detection task: spatial bias caused by data distributions that are not representative of a real-world deployment; and temporal bias caused by incorrect time splits of data, leading to unrealistic configurations. To address these biases, we introduce a set of constraints for fair experiment design, and propose a new metric, AUT, for classifier robustness in real-world settings. We additionally propose an algorithm designed to tune training data to enhance classifier performance. Finally, we present TESSERACT, an open-source framework for realistic classifier comparison. Our evaluation encompasses both traditional ML and deep learning methods, examining published works on an extensive Android dataset with 259,230 samples over a five-year span. Additionally, we conduct case studies in the Windows PE and PDF domains. Our findings identify the existence of biases in previous studies and reveal that significant performance enhancements are possible through appropriate, periodic tuning. We explore how mitigation strategies may support in achieving a more stable and better performance over time by employing multiple strategies to delay performance decay.
Adversarial Markov Games: On Adaptive Decision-Based Attacks and Defenses
Dec 20, 2023Despite considerable efforts on making them robust, real-world ML-based systems remain vulnerable to decision based attacks, as definitive proofs of their operational robustness have so far proven intractable. The canonical approach in robustness evaluation calls for adaptive attacks, that is with complete knowledge of the defense and tailored to bypass it. In this study, we introduce a more expansive notion of being adaptive and show how attacks but also defenses can benefit by it and by learning from each other through interaction. We propose and evaluate a framework for adaptively optimizing black-box attacks and defenses against each other through the competitive game they form. To reliably measure robustness, it is important to evaluate against realistic and worst-case attacks. We thus augment both attacks and the evasive arsenal at their disposal through adaptive control, and observe that the same can be done for defenses, before we evaluate them first apart and then jointly under a multi-agent perspective. We demonstrate that active defenses, which control how the system responds, are a necessary complement to model hardening when facing decision-based attacks; then how these defenses can be circumvented by adaptive attacks, only to finally elicit active and adaptive defenses. We validate our observations through a wide theoretical and empirical investigation to confirm that AI-enabled adversaries pose a considerable threat to black-box ML-based systems, rekindling the proverbial arms race where defenses have to be AI-enabled too. Succinctly, we address the challenges posed by adaptive adversaries and develop adaptive defenses, thereby laying out effective strategies in ensuring the robustness of ML-based systems deployed in the real-world.
"Real Attackers Don't Compute Gradients": Bridging the Gap Between Adversarial ML Research and Practice
Dec 29, 2022
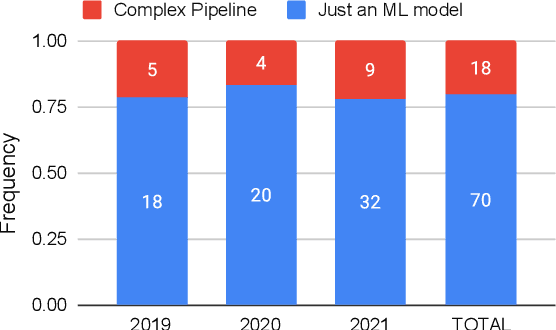
Recent years have seen a proliferation of research on adversarial machine learning. Numerous papers demonstrate powerful algorithmic attacks against a wide variety of machine learning (ML) models, and numerous other papers propose defenses that can withstand most attacks. However, abundant real-world evidence suggests that actual attackers use simple tactics to subvert ML-driven systems, and as a result security practitioners have not prioritized adversarial ML defenses. Motivated by the apparent gap between researchers and practitioners, this position paper aims to bridge the two domains. We first present three real-world case studies from which we can glean practical insights unknown or neglected in research. Next we analyze all adversarial ML papers recently published in top security conferences, highlighting positive trends and blind spots. Finally, we state positions on precise and cost-driven threat modeling, collaboration between industry and academia, and reproducible research. We believe that our positions, if adopted, will increase the real-world impact of future endeavours in adversarial ML, bringing both researchers and practitioners closer to their shared goal of improving the security of ML systems.
Jigsaw Puzzle: Selective Backdoor Attack to Subvert Malware Classifiers
Feb 11, 2022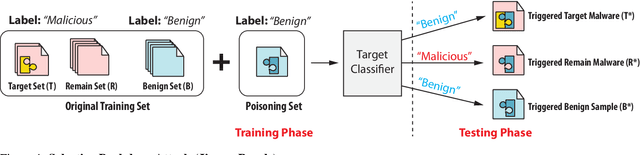

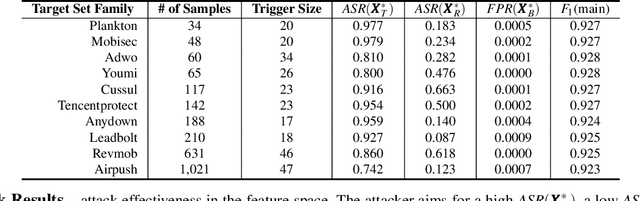
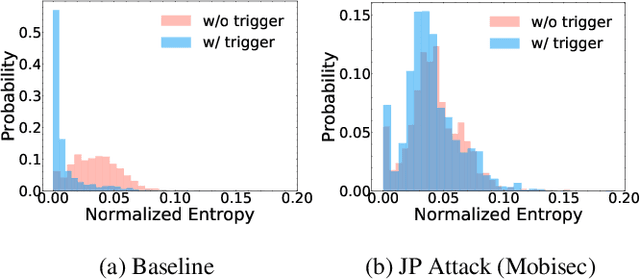
Malware classifiers are subject to training-time exploitation due to the need to regularly retrain using samples collected from the wild. Recent work has demonstrated the feasibility of backdoor attacks against malware classifiers, and yet the stealthiness of such attacks is not well understood. In this paper, we investigate this phenomenon under the clean-label setting (i.e., attackers do not have complete control over the training or labeling process). Empirically, we show that existing backdoor attacks in malware classifiers are still detectable by recent defenses such as MNTD. To improve stealthiness, we propose a new attack, Jigsaw Puzzle (JP), based on the key observation that malware authors have little to no incentive to protect any other authors' malware but their own. As such, Jigsaw Puzzle learns a trigger to complement the latent patterns of the malware author's samples, and activates the backdoor only when the trigger and the latent pattern are pieced together in a sample. We further focus on realizable triggers in the problem space (e.g., software code) using bytecode gadgets broadly harvested from benign software. Our evaluation confirms that Jigsaw Puzzle is effective as a backdoor, remains stealthy against state-of-the-art defenses, and is a threat in realistic settings that depart from reasoning about feature-space only attacks. We conclude by exploring promising approaches to improve backdoor defenses.
Universal Adversarial Perturbations for Malware
Feb 12, 2021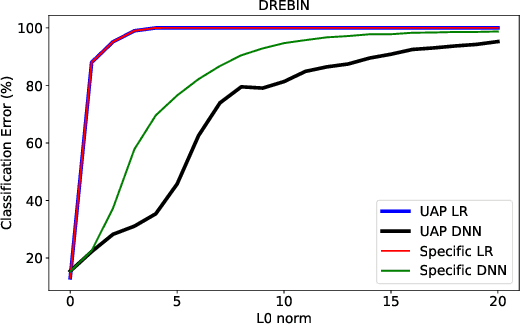

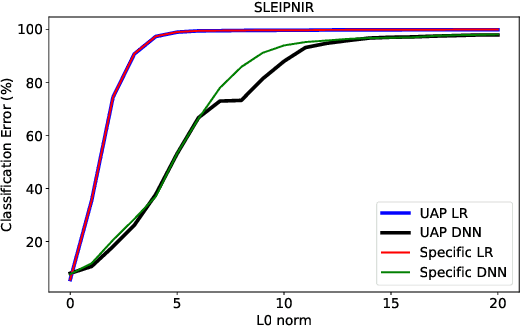
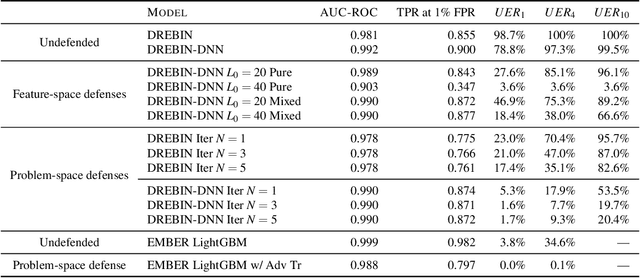
Machine learning classification models are vulnerable to adversarial examples -- effective input-specific perturbations that can manipulate the model's output. Universal Adversarial Perturbations (UAPs), which identify noisy patterns that generalize across the input space, allow the attacker to greatly scale up the generation of these adversarial examples. Although UAPs have been explored in application domains beyond computer vision, little is known about their properties and implications in the specific context of realizable attacks, such as malware, where attackers must reason about satisfying challenging problem-space constraints. In this paper, we explore the challenges and strengths of UAPs in the context of malware classification. We generate sequences of problem-space transformations that induce UAPs in the corresponding feature-space embedding and evaluate their effectiveness across threat models that consider a varying degree of realistic attacker knowledge. Additionally, we propose adversarial training-based mitigations using knowledge derived from the problem-space transformations, and compare against alternative feature-space defenses. Our experiments limit the effectiveness of a white box Android evasion attack to ~20 % at the cost of 3 % TPR at 1 % FPR. We additionally show how our method can be adapted to more restrictive application domains such as Windows malware. We observe that while adversarial training in the feature space must deal with large and often unconstrained regions, UAPs in the problem space identify specific vulnerabilities that allow us to harden a classifier more effectively, shifting the challenges and associated cost of identifying new universal adversarial transformations back to the attacker.