 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Latent Diffusion Using Latent CLIP
Mar 11, 2025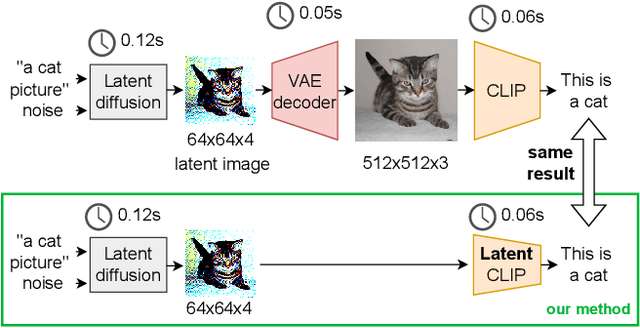
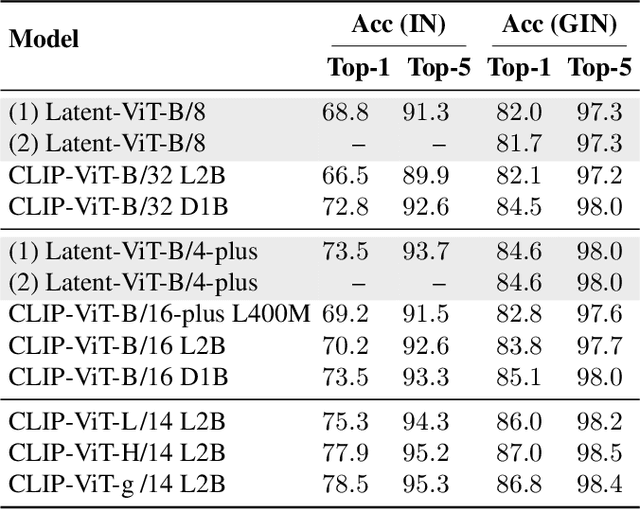
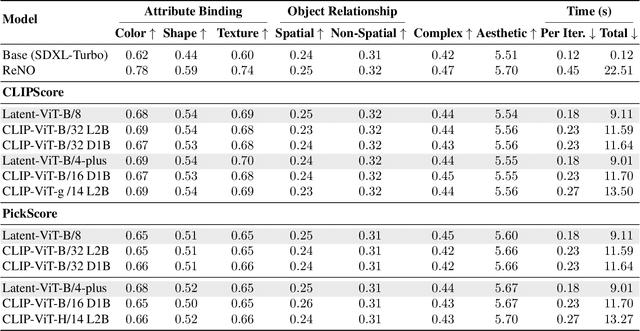

Instead of performing text-conditioned denoising in the image domain, latent diffusion models (LDMs) operate in latent space of a variational autoencoder (VAE), enabling more efficient processing at reduced computational costs. However, while the diffusion process has moved to the latent space, the contrastive language-image pre-training (CLIP) models, as used in many image processing tasks, still operate in pixel space. Doing so requires costly VAE-decoding of latent images before they can be processed. In this paper, we introduce Latent-CLIP, a CLIP model that operates directly in the latent space. We train Latent-CLIP on 2.7B pairs of latent images and descriptive texts, and show that it matches zero-shot classification performance of similarly sized CLIP models on both the ImageNet benchmark and a LDM-generated version of it, demonstrating its effectiveness in assessing both real and generated content. Furthermore, we construct Latent-CLIP rewards for reward-based noise optimization (ReNO) and show that they match the performance of their CLIP counterparts on GenEval and T2I-CompBench while cutting the cost of the total pipeline by 21%. Finally, we use Latent-CLIP to guide generation away from harmful content, achieving strong performance on the inappropriate image prompts (I2P) benchmark and a custom evaluation, without ever requiring the costly step of decoding intermediate images.
Holistic Adversarially Robust Pruning
Dec 19, 2024



Neural networks can be drastically shrunk in size by removing redundant parameters. While crucial for the deployment on resource-constraint hardware, oftentimes, compression comes with a severe drop in accuracy and lack of adversarial robustness. Despite recent advances, counteracting both aspects has only succeeded for moderate compression rates so far. We propose a novel method, HARP, that copes with aggressive pruning significantly better than prior work. For this, we consider the network holistically. We learn a global compression strategy that optimizes how many parameters (compression rate) and which parameters (scoring connections) to prune specific to each layer individually. Our method fine-tunes an existing model with dynamic regularization, that follows a step-wise incremental function balancing the different objectives. It starts by favoring robustness before shifting focus on reaching the target compression rate and only then handles the objectives equally. The learned compression strategies allow us to maintain the pre-trained model natural accuracy and its adversarial robustness for a reduction by 99% of the network original size. Moreover, we observe a crucial influence of non-uniform compression across layers.
Backdooring Explainable Machine Learning
Apr 20, 2022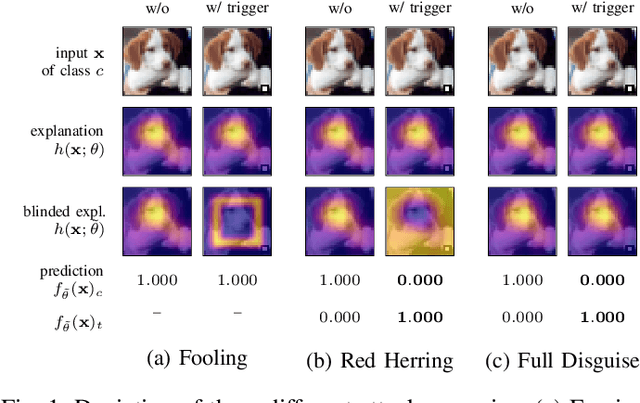
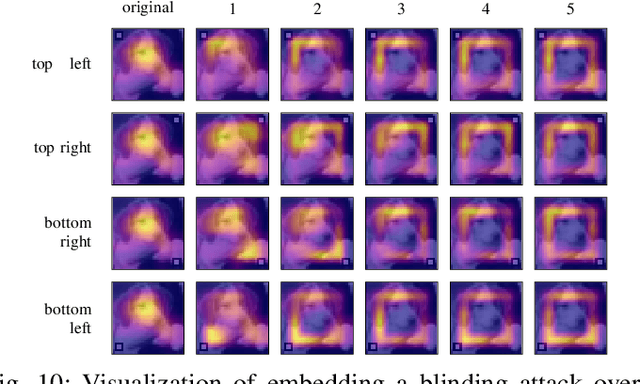

Explainable machine learning holds great potential for analyzing and understanding learning-based systems. These methods can, however, be manipulated to present unfaithful explanations, giving rise to powerful and stealthy adversaries. In this paper, we demonstrate blinding attacks that can fully disguise an ongoing attack against the machine learning model. Similar to neural backdoors, we modify the model's prediction upon trigger presence but simultaneously also fool the provided explanation. This enables an adversary to hide the presence of the trigger or point the explanation to entirely different portions of the input, throwing a red herring. We analyze different manifestations of such attacks for different explanation types in the image domain, before we resume to conduct a red-herring attack against malware classification.
Machine Unlearning of Features and Labels
Aug 26, 2021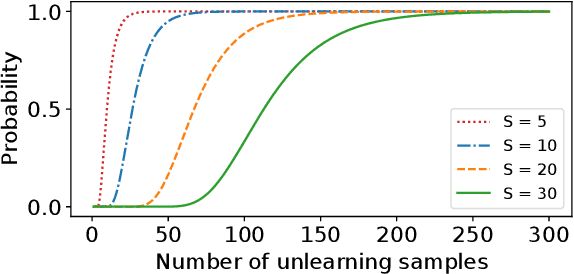

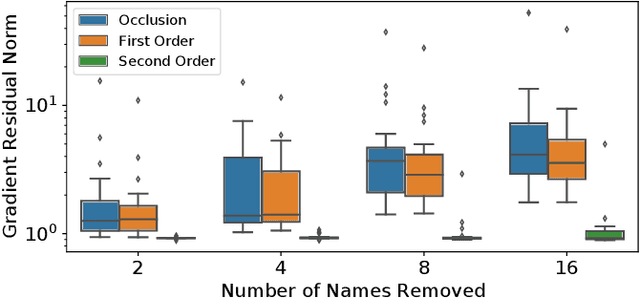
Removing information from a machine learning model is a non-trivial task that requires to partially revert the training process. This task is unavoidable when sensitive data, such as credit card numbers or passwords, accidentally enter the model and need to be removed afterwards. Recently, different concepts for machine unlearning have been proposed to address this problem. While these approaches are effective in removing individual data points, they do not scale to scenarios where larger groups of features and labels need to be reverted. In this paper, we propose a method for unlearning features and labels. Our approach builds on the concept of influence functions and realizes unlearning through closed-form updates of model parameters. It enables to adapt the influence of training data on a learning model retrospectively, thereby correcting data leaks and privacy issues. For learning models with strongly convex loss functions, our method provides certified unlearning with theoretical guarantees. For models with non-convex losses, we empirically show that unlearning features and labels is effective and significantly faster than other strategies.
Dos and Don'ts of Machine Learning in Computer Security
Oct 19, 2020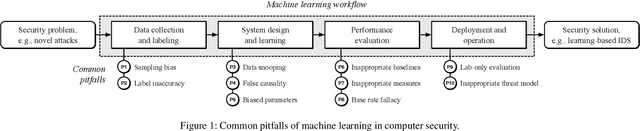
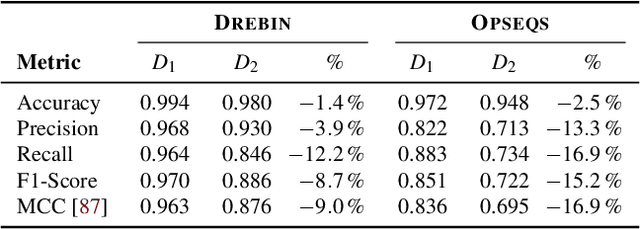
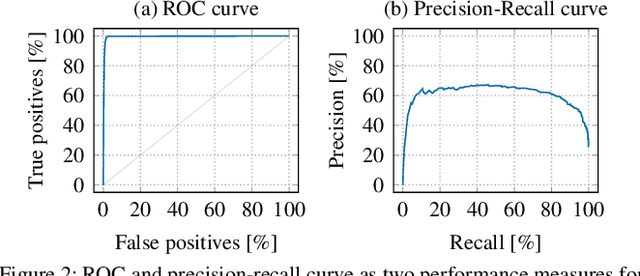
With the growing processing power of computing systems and the increasing availability of massive datasets, machine learning algorithms have led to major breakthroughs in many different areas. This development has influenced computer security, spawning a series of work on learning-based security systems, such as for malware detection, vulnerability discovery, and binary code analysis. Despite great potential, machine learning in security is prone to subtle pitfalls that undermine its performance and render learning-based systems potentially unsuitable for security tasks and practical deployment. In this paper, we look at this problem with critical eyes. First, we identify common pitfalls in the design, implementation, and evaluation of learning-based security systems. We conduct a longitudinal study of 30 papers from top-tier security conferences within the past 10 years, confirming that these pitfalls are widespread in the current security literature. In an empirical analysis, we further demonstrate how individual pitfalls can lead to unrealistic performance and interpretations, obstructing the understanding of the security problem at hand. As a remedy, we derive a list of actionable recommendations to support researchers and our community in avoiding pitfalls, promoting a sound design, development, evaluation, and deployment of learning-based systems for computer security.
Don't Paint It Black: White-Box Explanations for Deep Learning in Computer Security
Jun 06, 2019
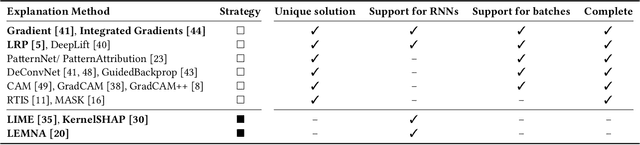


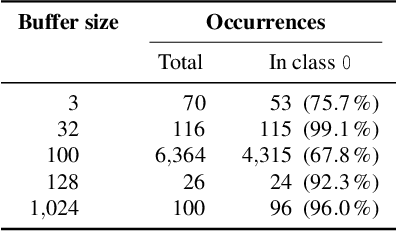
Deep learning is increasingly used as a basic building block of security systems. Unfortunately, deep neural networks are hard to interpret, and their decision process is opaque to the practitioner. Recent work has started to address this problem by considering black-box explanations for deep learning in computer security (CCS'18). The underlying explanation methods, however, ignore the structure of neural networks and thus omit crucial information for analyzing the decision process. In this paper, we investigate white-box explanations and systematically compare them with current black-box approaches. In an extensive evaluation with learning-based systems for malware detection and vulnerability discovery, we demonstrate that white-box explanations are more concise, sparse, complete and efficient than black-box approaches. As a consequence, we generally recommend the use of white-box explanations if access to the employed neural network is available, which usually is the case for stand-alone systems for malware detection, binary analysis, and vulnerability discovery.
Poisoning Behavioral Malware Clustering
Nov 25, 2018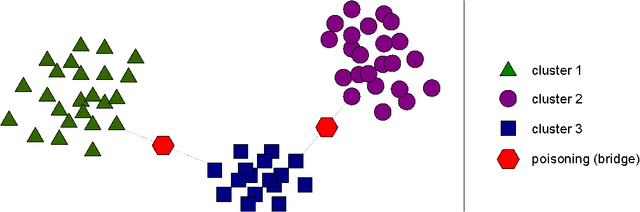

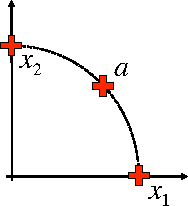
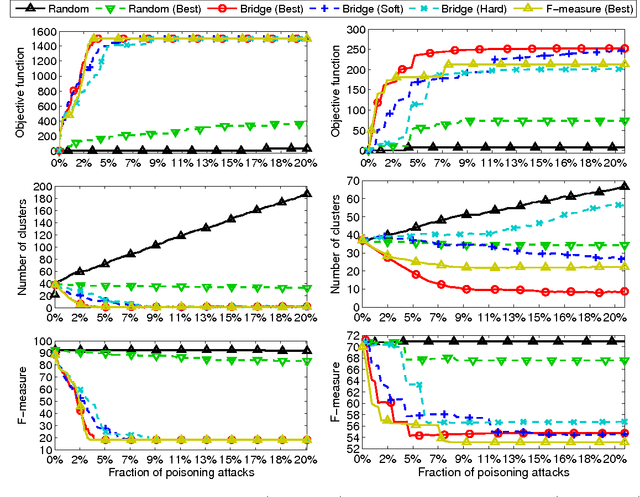
Clustering algorithms have become a popular tool in computer security to analyze the behavior of malware variants, identify novel malware families, and generate signatures for antivirus systems. However, the suitability of clustering algorithms for security-sensitive settings has been recently questioned by showing that they can be significantly compromised if an attacker can exercise some control over the input data. In this paper, we revisit this problem by focusing on behavioral malware clustering approaches, and investigate whether and to what extent an attacker may be able to subvert these approaches through a careful injection of samples with poisoning behavior. To this end, we present a case study on Malheur, an open-source tool for behavioral malware clustering. Our experiments not only demonstrate that this tool is vulnerable to poisoning attacks, but also that it can be significantly compromised even if the attacker can only inject a very small percentage of attacks into the input data. As a remedy, we discuss possible countermeasures and highlight the need for more secure clustering algorithms.