 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdooring Explainable Machine Learning
Apr 20, 2022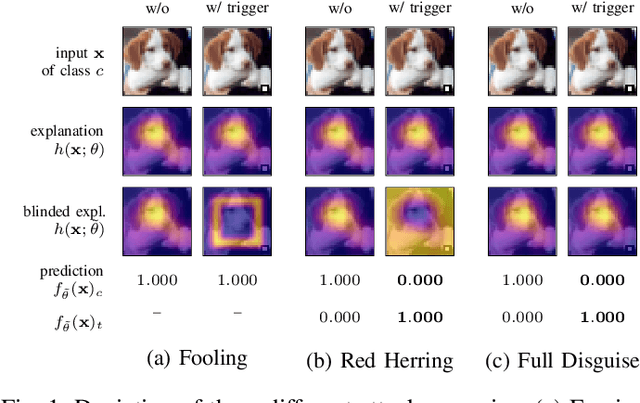
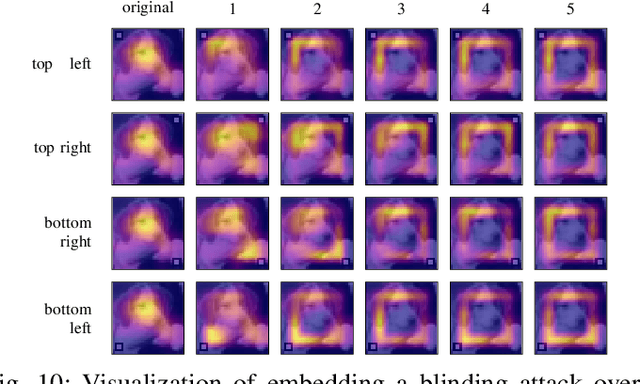
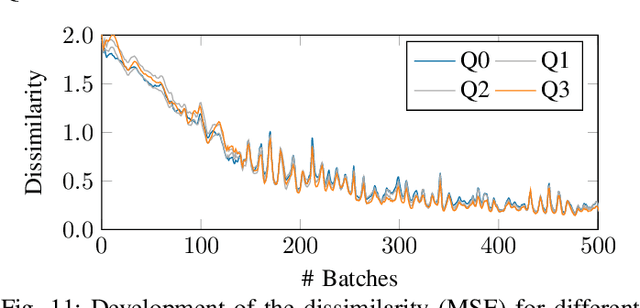

Explainable machine learning holds great potential for analyzing and understanding learning-based systems. These methods can, however, be manipulated to present unfaithful explanations, giving rise to powerful and stealthy adversaries. In this paper, we demonstrate blinding attacks that can fully disguise an ongoing attack against the machine learning model. Similar to neural backdoors, we modify the model's prediction upon trigger presence but simultaneously also fool the provided explanation. This enables an adversary to hide the presence of the trigger or point the explanation to entirely different portions of the input, throwing a red herring. We analyze different manifestations of such attacks for different explanation types in the image domain, before we resume to conduct a red-herring attack against malware classification.