 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-space Attacks for Refusal Evasion in Language Models
May 20, 2026Safety-aligned language models are trained to refuse harmful requests, yet refusal behavior can be suppressed by steering their internal representations. Existing methods do so by ablating a refusal direction from model activations, aiming to remove refusal from the model's residual stream. Despite their empirical success, these methods lack a principled account of the latent-space transformation they induce and why it suppresses refusal. In this work, we recast refusal suppression as a latent-space evasion attack against linear probes trained to separate refused from answered prompts. Under this view, prior work's difference-in-means direction naturally defines such a probe, and its ablation is exactly a projection onto its decision boundary, i.e., a minimum-confidence evasion attack. This perspective not only explains the empirical success of prior work but also admits a key limitation: evasion stops at the decision boundary, motivating the need to push representations further into the compliant region, i.e., where the model answers. We leverage this by proposing a Controlled Latent-space Evasion attack that projects representations past the boundary with an optimized confidence. We achieve state-of-the-art attack success rate across 15 instruction-tuned, multimodal, and reasoning models, outperforming existing refusal-ablation baselines and specialized jailbreak attacks.
Harnessing Hyperbolic Geometry for Harmful Prompt Detection and Sanitization
Apr 07, 2026Vision-Language Models (VLMs) have become essential for tasks such as image synthesis, captioning, and retrieval by aligning textual and visual information in a shared embedding space. Yet, this flexibility also makes them vulnerable to malicious prompts designed to produce unsafe content, raising critical safety concerns. Existing defenses either rely on blacklist filters, which are easily circumvented, or on heavy classifier-based systems, both of which are costly and fragile under embedding-level attacks. We address these challenges with two complementary components: Hyperbolic Prompt Espial (HyPE) and Hyperbolic Prompt Sanitization (HyPS). HyPE is a lightweight anomaly detector that leverages the structured geometry of hyperbolic space to model benign prompts and detect harmful ones as outliers. HyPS builds on this detection by applying explainable attribution methods to identify and selectively modify harmful words, neutralizing unsafe intent while preserving the original semantics of user prompts. Through extensive experiments across multiple datasets and adversarial scenarios, we prove that our framework consistently outperforms prior defenses in both detection accuracy and robustness. Together, HyPE and HyPS offer an efficient, interpretable, and resilient approach to safeguarding VLMs against malicious prompt misuse.
Out-of-Distribution Detection for Continual Learning: Design Principles and Benchmarking
Dec 16, 2025



Recent years have witnessed significant progress in the development of machine learning models across a wide range of fields, fueled by increased computational resources, large-scale datasets, and the rise of deep learning architectures. From malware detection to enabling autonomous navigation, modern machine learning systems have demonstrated remarkable capabilities. However, as these models are deployed in ever-changing real-world scenarios, their ability to remain reliable and adaptive over time becomes increasingly important. For example, in the real world, new malware families are continuously developed, whereas autonomous driving cars are employed in many different cities and weather conditions. Models trained in fixed settings can not respond effectively to novel conditions encountered post-deployment. In fact, most machine learning models are still developed under the assumption that training and test data are independent and identically distributed (i.i.d.), i.e., sampled from the same underlying (unknown) distribution. While this assumption simplifies model development and evaluation, it does not hold in many real-world applications, where data changes over time and unexpected inputs frequently occur. Retraining models from scratch whenever new data appears is computationally expensive, time-consuming, and impractical in resource-constrained environments. These limitations underscore the need for Continual Learning (CL), which enables models to incrementally learn from evolving data streams without forgetting past knowledge, and Out-of-Distribution (OOD) detection, which allows systems to identify and respond to novel or anomalous inputs. Jointly addressing both challenges is critical to developing robust, efficient, and adaptive AI systems.
SOM Directions are Better than One: Multi-Directional Refusal Suppression in Language Models
Nov 13, 2025Refusal refers to the functional behavior enabling safety-aligned language models to reject harmful or unethical prompts. Following the growing scientific interest in mechanistic interpretability, recent work encoded refusal behavior as a single direction in the model's latent space; e.g., computed as the difference between the centroids of harmful and harmless prompt representations. However, emerging evidence suggests that concepts in LLMs often appear to be encoded as a low-dimensional manifold embedded in the high-dimensional latent space. Motivated by these findings, we propose a novel method leveraging Self-Organizing Maps (SOMs) to extract multiple refusal directions. To this end, we first prove that SOMs generalize the prior work's difference-in-means technique. We then train SOMs on harmful prompt representations to identify multiple neurons. By subtracting the centroid of harmless representations from each neuron, we derive a set of multiple directions expressing the refusal concept. We validate our method on an extensive experimental setup, demonstrating that ablating multiple directions from models' internals outperforms not only the single-direction baseline but also specialized jailbreak algorithms, leading to an effective suppression of refusal. Finally, we conclude by analyzing the mechanistic implications of our approach.
A Neural Rejection System Against Universal Adversarial Perturbations in Radio Signal Classification
Jun 13, 2025Advantages of deep learning over traditional methods have been demonstrated for radio signal classification in the recent years. However, various researchers have discovered that even a small but intentional feature perturbation known as adversarial examples can significantly deteriorate the performance of the deep learning based radio signal classification. Among various kinds of adversarial examples, universal adversarial perturbation has gained considerable attention due to its feature of being data independent, hence as a practical strategy to fool the radio signal classification with a high success rate. Therefore, in this paper, we investigate a defense system called neural rejection system to propose against universal adversarial perturbations, and evaluate its performance by generating white-box universal adversarial perturbations. We show that the proposed neural rejection system is able to defend universal adversarial perturbations with significantly higher accuracy than the undefended deep neural network.
Attention-based Adversarial Robust Distillation in Radio Signal Classifications for Low-Power IoT Devices
Jun 13, 2025Due to great success of transformers in many applications such as natural language processing and computer vision, transformers have been successfully applied in automatic modulation classification. We have shown that transformer-based radio signal classification is vulnerable to imperceptible and carefully crafted attacks called adversarial examples. Therefore, we propose a defense system against adversarial examples in transformer-based modulation classifications. Considering the need for computationally efficient architecture particularly for Internet of Things (IoT)-based applications or operation of devices in environment where power supply is limited, we propose a compact transformer for modulation classification. The advantages of robust training such as adversarial training in transformers may not be attainable in compact transformers. By demonstrating this, we propose a novel compact transformer that can enhance robustness in the presence of adversarial attacks. The new method is aimed at transferring the adversarial attention map from the robustly trained large transformer to a compact transformer. The proposed method outperforms the state-of-the-art techniques for the considered white-box scenarios including fast gradient method and projected gradient descent attacks. We have provided reasoning of the underlying working mechanisms and investigated the transferability of the adversarial examples between different architectures. The proposed method has the potential to protect the transformer from the transferability of adversarial examples.
Empirical Quantification of Spurious Correlations in Malware Detection
Jun 11, 2025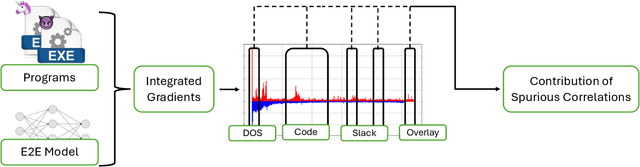
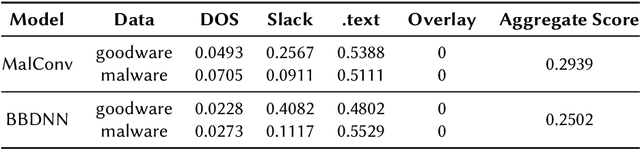
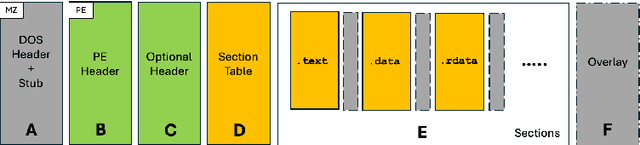
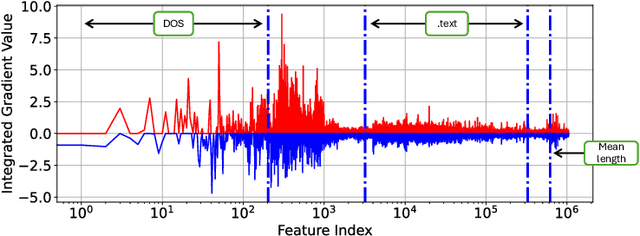
End-to-end deep learning exhibits unmatched performance for detecting malware, but such an achievement is reached by exploiting spurious correlations -- features with high relevance at inference time, but known to be useless through domain knowledge. While previous work highlighted that deep networks mainly focus on metadata, none investigated the phenomenon further, without quantifying their impact on the decision. In this work, we deepen our understanding of how spurious correlation affects deep learning for malware detection by highlighting how much models rely on empty spaces left by the compiler, which diminishes the relevance of the compiled code. Through our seminal analysis on a small-scale balanced dataset, we introduce a ranking of two end-to-end models to better understand which is more suitable to be put in production.
Buffer-free Class-Incremental Learning with Out-of-Distribution Detection
May 29, 2025Class-incremental learning (CIL) poses significant challenges in open-world scenarios, where models must not only learn new classes over time without forgetting previous ones but also handle inputs from unknown classes that a closed-set model would misclassify. Recent works address both issues by (i)~training multi-head models using the task-incremental learning framework, and (ii) predicting the task identity employing out-of-distribution (OOD) detectors. While effective, the latter mainly relies on joint training with a memory buffer of past data, raising concerns around privacy, scalability, and increased training time. In this paper, we present an in-depth analysis of post-hoc OOD detection methods and investigate their potential to eliminate the need for a memory buffer. We uncover that these methods, when applied appropriately at inference time, can serve as a strong substitute for buffer-based OOD detection. We show that this buffer-free approach achieves comparable or superior performance to buffer-based methods both in terms of class-incremental learning and the rejection of unknown samples. Experimental results on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets support our findings, offering new insights into the design of efficient and privacy-preserving CIL systems for open-world settings.
SoK: On the Offensive Potential of AI
Dec 24, 2024



Our society increasingly benefits from Artificial Intelligence (AI). Unfortunately, more and more evidence shows that AI is also used for offensive purposes. Prior works have revealed various examples of use cases in which the deployment of AI can lead to violation of security and privacy objectives. No extant work, however, has been able to draw a holistic picture of the offensive potential of AI. In this SoK paper we seek to lay the ground for a systematic analysis of the heterogeneous capabilities of offensive AI. In particular we (i) account for AI risks to both humans and systems while (ii) consolidating and distilling knowledge from academic literature, expert opinions, industrial venues, as well as laymen -- all of which being valuable sources of information on offensive AI. To enable alignment of such diverse sources of knowledge, we devise a common set of criteria reflecting essential technological factors related to offensive AI. With the help of such criteria, we systematically analyze: 95 research papers; 38 InfoSec briefings (from, e.g., BlackHat); the responses of a user study (N=549) entailing individuals with diverse backgrounds and expertise; and the opinion of 12 experts. Our contributions not only reveal concerning ways (some of which overlooked by prior work) in which AI can be offensively used today, but also represent a foothold to address this threat in the years to come.
Robust image classification with multi-modal large language models
Dec 13, 2024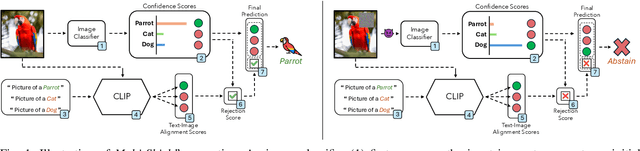
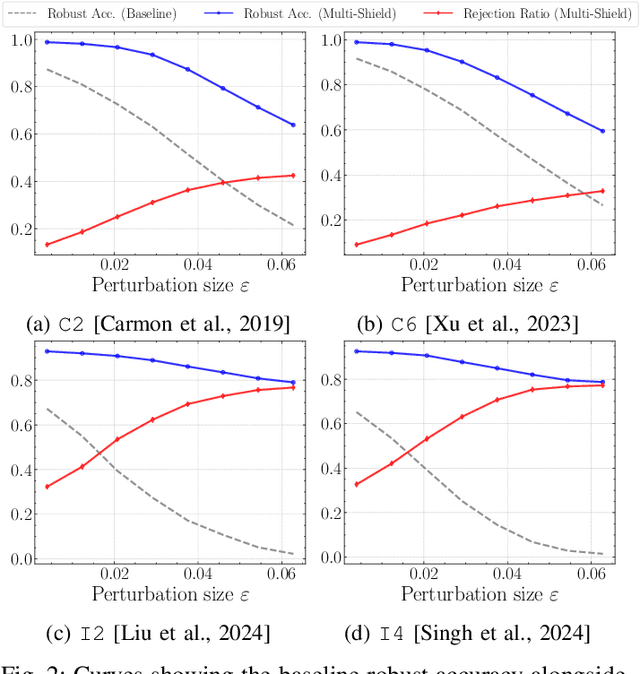
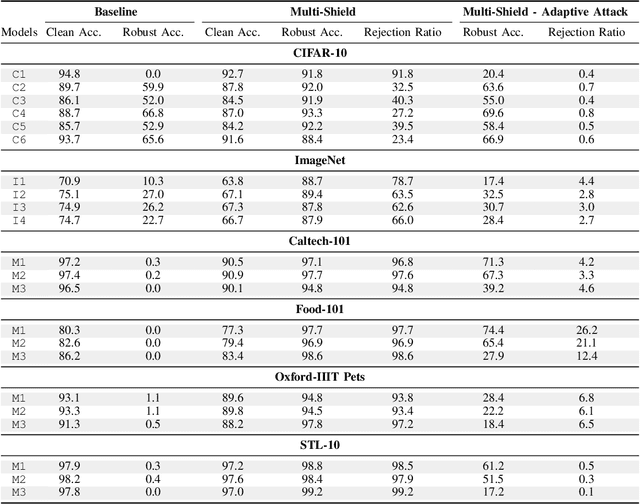
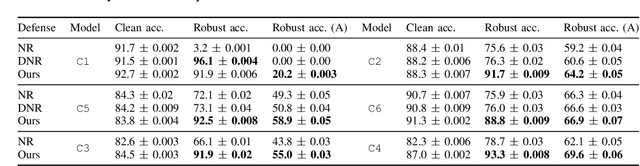
Deep Neural Networks are vulnerable to adversarial examples, i.e., carefully crafted input samples that can cause models to make incorrect predictions with high confidence. To mitigate these vulnerabilities, adversarial training and detection-based defenses have been proposed to strengthen models in advance. However, most of these approaches focus on a single data modality, overlooking the relationships between visual patterns and textual descriptions of the input. In this paper, we propose a novel defense, Multi-Shield, designed to combine and complement these defenses with multi-modal information to further enhance their robustness. Multi-Shield leverages multi-modal large language models to detect adversarial examples and abstain from uncertain classifications when there is no alignment between textual and visual representations of the input. Extensive evaluations on CIFAR-10 and ImageNet datasets, using robust and non-robust image classification models, demonstrate that Multi-Shield can be easily integrated to detect and reject adversarial examples, outperforming the original defenses.