 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust image classification with multi-modal large language models
Dec 13, 2024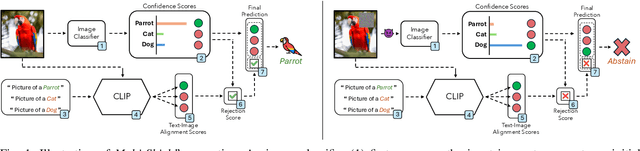
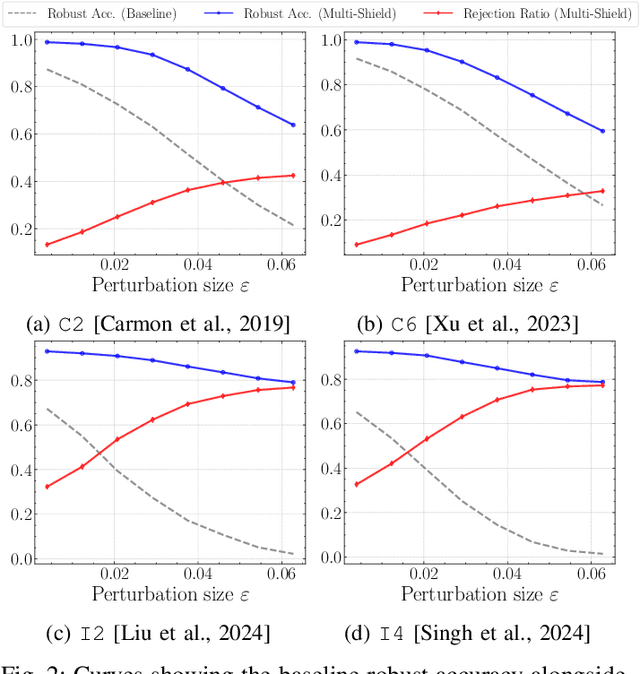
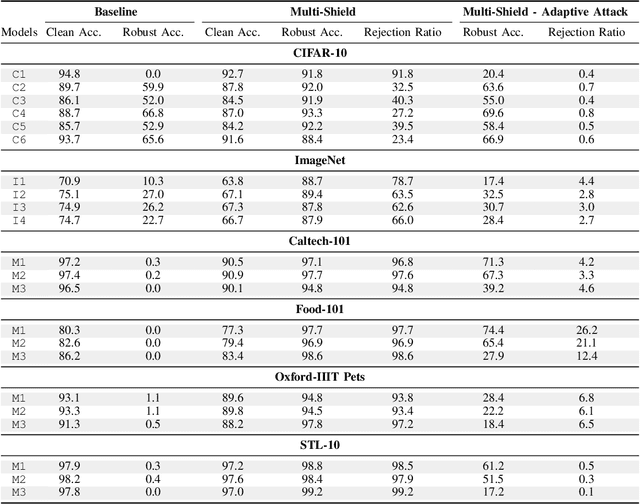
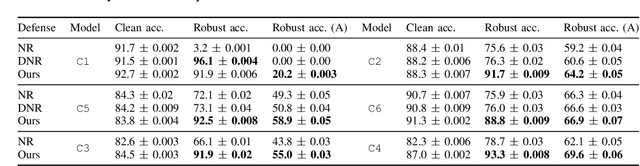
Deep Neural Networks are vulnerable to adversarial examples, i.e., carefully crafted input samples that can cause models to make incorrect predictions with high confidence. To mitigate these vulnerabilities, adversarial training and detection-based defenses have been proposed to strengthen models in advance. However, most of these approaches focus on a single data modality, overlooking the relationships between visual patterns and textual descriptions of the input. In this paper, we propose a novel defense, Multi-Shield, designed to combine and complement these defenses with multi-modal information to further enhance their robustness. Multi-Shield leverages multi-modal large language models to detect adversarial examples and abstain from uncertain classifications when there is no alignment between textual and visual representations of the input. Extensive evaluations on CIFAR-10 and ImageNet datasets, using robust and non-robust image classification models, demonstrate that Multi-Shield can be easily integrated to detect and reject adversarial examples, outperforming the original defenses.
Sonic: Fast and Transferable Data Poisoning on Clustering Algorithms
Aug 14, 2024



Data poisoning attacks on clustering algorithms have received limited attention, with existing methods struggling to scale efficiently as dataset sizes and feature counts increase. These attacks typically require re-clustering the entire dataset multiple times to generate predictions and assess the attacker's objectives, significantly hindering their scalability. This paper addresses these limitations by proposing Sonic, a novel genetic data poisoning attack that leverages incremental and scalable clustering algorithms, e.g., FISHDBC, as surrogates to accelerate poisoning attacks against graph-based and density-based clustering methods, such as HDBSCAN. We empirically demonstrate the effectiveness and efficiency of Sonic in poisoning the target clustering algorithms. We then conduct a comprehensive analysis of the factors affecting the scalability and transferability of poisoning attacks against clustering algorithms, and we conclude by examining the robustness of hyperparameters in our attack strategy Sonic.
Minimizing Energy Consumption of Deep Learning Models by Energy-Aware Training
Jul 01, 2023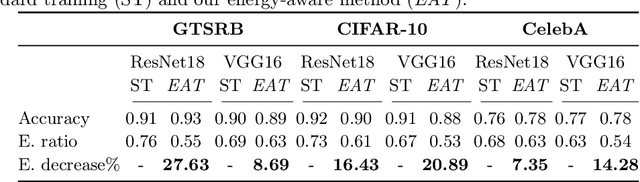
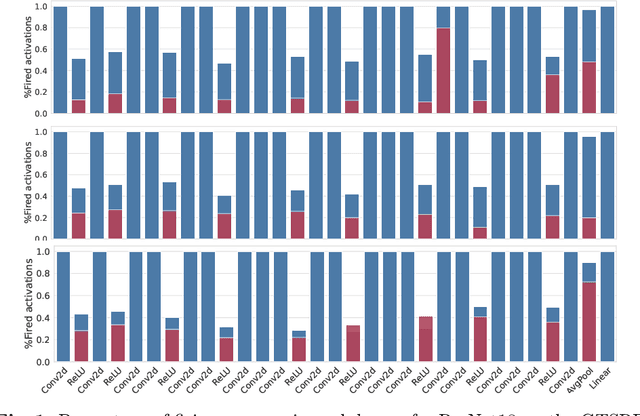
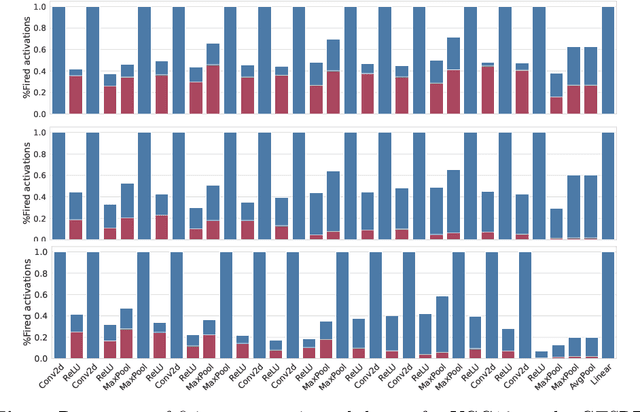
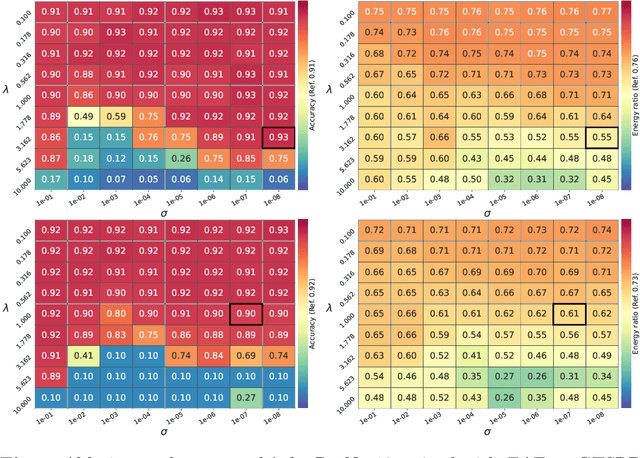
Deep learning models undergo a significant increase in the number of parameters they possess, leading to the execution of a larger number of operations during inference. This expansion significantly contributes to higher energy consumption and prediction latency. In this work, we propose EAT, a gradient-based algorithm that aims to reduce energy consumption during model training. To this end, we leverage a differentiable approximation of the $\ell_0$ norm, and use it as a sparse penalty over the training loss. Through our experimental analysis conducted on three datasets and two deep neural networks, we demonstrate that our energy-aware training algorithm EAT is able to train networks with a better trade-off between classification performance and energy efficiency.