 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulating Feature Visualizations with Gradient Slingshots
Jan 11, 2024
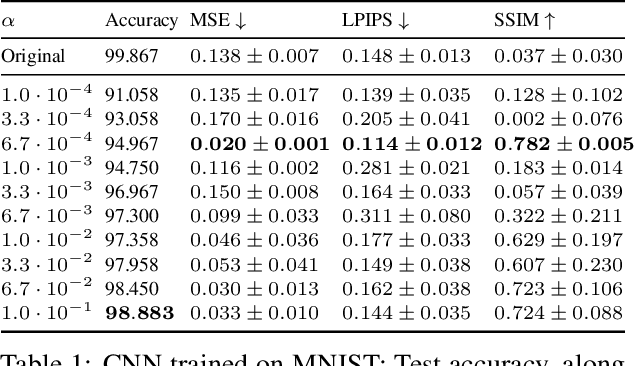
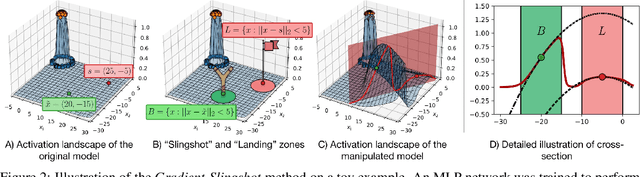
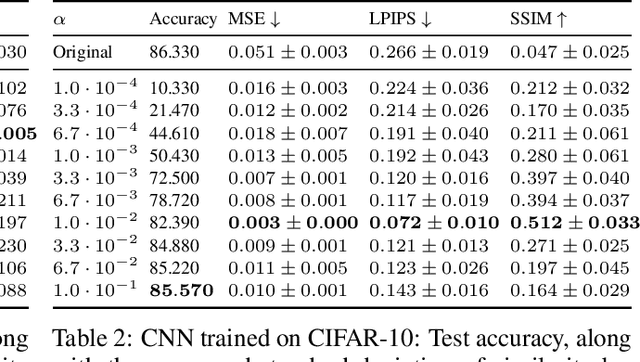
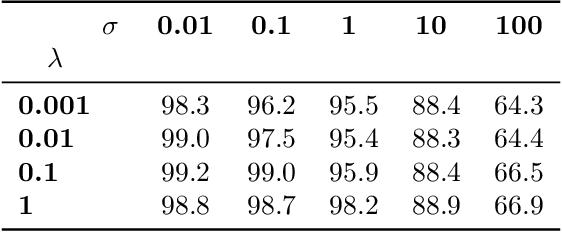
Deep Neural Networks (DNNs) are capable of learning complex and versatile representations, however, the semantic nature of the learned concepts remains unknown. A common method used to explain the concepts learned by DNNs is Activation Maximization (AM), which generates a synthetic input signal that maximally activates a particular neuron in the network. In this paper, we investigate the vulnerability of this approach to adversarial model manipulations and introduce a novel method for manipulating feature visualization without altering the model architecture or significantly impacting the model's decision-making process. We evaluate the effectiveness of our method on several neural network models and demonstrate its capabilities to hide the functionality of specific neurons by masking the original explanations of neurons with chosen target explanations during model auditing. As a remedy, we propose a protective measure against such manipulations and provide quantitative evidence which substantiates our findings.
Machine Unlearning of Features and Labels
Aug 26, 2021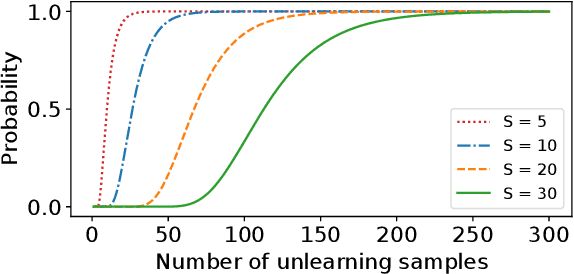

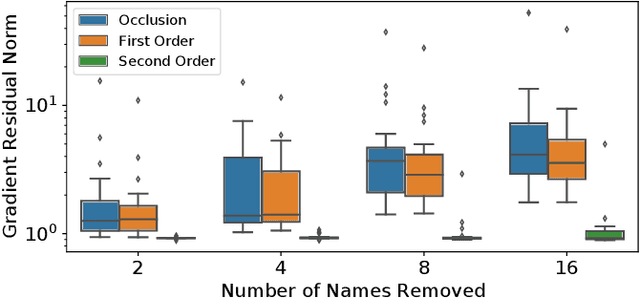
Removing information from a machine learning model is a non-trivial task that requires to partially revert the training process. This task is unavoidable when sensitive data, such as credit card numbers or passwords, accidentally enter the model and need to be removed afterwards. Recently, different concepts for machine unlearning have been proposed to address this problem. While these approaches are effective in removing individual data points, they do not scale to scenarios where larger groups of features and labels need to be reverted. In this paper, we propose a method for unlearning features and labels. Our approach builds on the concept of influence functions and realizes unlearning through closed-form updates of model parameters. It enables to adapt the influence of training data on a learning model retrospectively, thereby correcting data leaks and privacy issues. For learning models with strongly convex loss functions, our method provides certified unlearning with theoretical guarantees. For models with non-convex losses, we empirically show that unlearning features and labels is effective and significantly faster than other strategies.
Against All Odds: Winning the Defense Challenge in an Evasion Competition with Diversification
Oct 19, 2020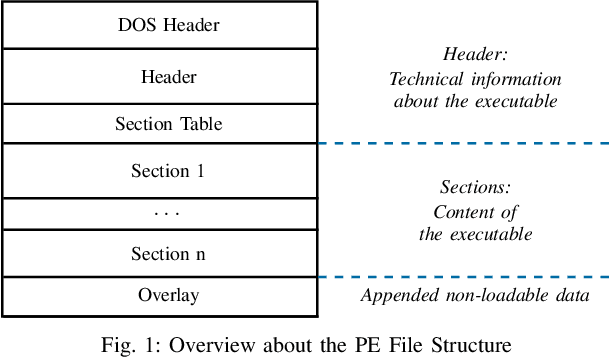
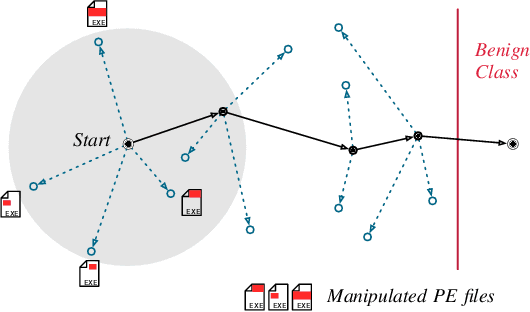
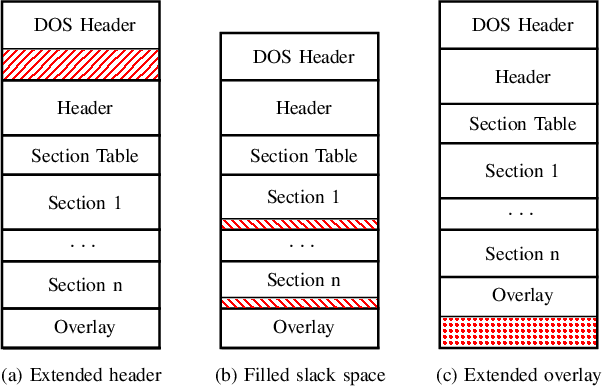
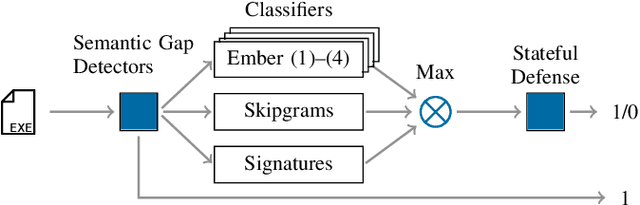
Machine learning-based systems for malware detection operate in a hostile environment. Consequently, adversaries will also target the learning system and use evasion attacks to bypass the detection of malware. In this paper, we outline our learning-based system PEberus that got the first place in the defender challenge of the Microsoft Evasion Competition, resisting a variety of attacks from independent attackers. Our system combines multiple, diverse defenses: we address the semantic gap, use various classification models, and apply a stateful defense. This competition gives us the unique opportunity to examine evasion attacks under a realistic scenario. It also highlights that existing machine learning methods can be hardened against attacks by thoroughly analyzing the attack surface and implementing concepts from adversarial learning. Our defense can serve as an additional baseline in the future to strengthen the research on secure learning.