 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs Experience an Internal Polylogue? Investigating Reasoning through the Lens of Personas
May 09, 2026Recent work shows that large language models (LLMs) encode behavioural traits ("personas") as linear directions in activation space, often called "persona vectors". Prior work has used such directions as static handles for behavioural steering. Building on this, we treat them as dynamic signals instead: probes we can monitor and intervene on as reasoning unfolds. We use the term polylogue to denote the time series of alignments between persona vectors and hidden activations over the course of generation. Experiments across four open-weight models show that polylogue features predict correctness on MMLU-Pro competitively with low-dimensional activation baselines, while remaining interpretable through their associated persona directions. They also suggest concrete steering targets, namely which latent directions to modulate at different stages of a response. We instantiate this as a simple paragraph-conditioned intervention that improves accuracy on three of four models, pointing to stage-aware latent steering as a promising direction for reasoning-time control. Together, this positions the polylogue as an interpretable tool for reasoning-time monitoring and intervention.
Capturing Polysemanticity with PRISM: A Multi-Concept Feature Description Framework
Jun 18, 2025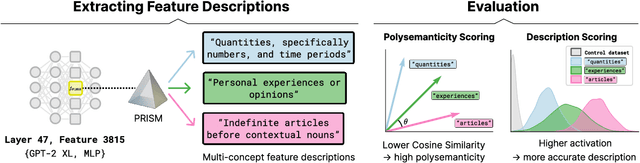

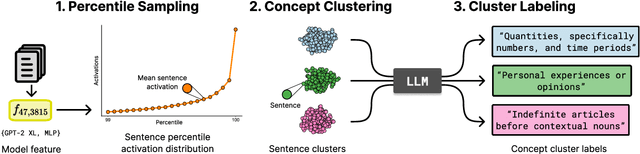

Automated interpretability research aims to identify concepts encoded in neural network features to enhance human understanding of model behavior. Current feature description methods face two critical challenges: limited robustness and the flawed assumption that each neuron encodes only a single concept (monosemanticity), despite growing evidence that neurons are often polysemantic. This assumption restricts the expressiveness of feature descriptions and limits their ability to capture the full range of behaviors encoded in model internals. To address this, we introduce Polysemantic FeatuRe Identification and Scoring Method (PRISM), a novel framework that captures the inherent complexity of neural network features. Unlike prior approaches that assign a single description per feature, PRISM provides more nuanced descriptions for both polysemantic and monosemantic features. We apply PRISM to language models and, through extensive benchmarking against existing methods, demonstrate that our approach produces more accurate and faithful feature descriptions, improving both overall description quality (via a description score) and the ability to capture distinct concepts when polysemanticity is present (via a polysemanticity score).
Deep Learning Meets Teleconnections: Improving S2S Predictions for European Winter Weather
Apr 10, 2025Predictions on subseasonal-to-seasonal (S2S) timescales--ranging from two weeks to two month--are crucial for early warning systems but remain challenging owing to chaos in the climate system. Teleconnections, such as the stratospheric polar vortex (SPV) and Madden-Julian Oscillation (MJO), offer windows of enhanced predictability, however, their complex interactions remain underutilized in operational forecasting. Here, we developed and evaluated deep learning architectures to predict North Atlantic-European (NAE) weather regimes, systematically assessing the role of remote drivers in improving S2S forecast skill of deep learning models. We implemented (1) a Long Short-term Memory (LSTM) network predicting the NAE regimes of the next six weeks based on previous regimes, (2) an Index-LSTM incorporating SPV and MJO indices, and (3) a ViT-LSTM using a Vision Transformer to directly encode stratospheric wind and tropical outgoing longwave radiation fields. These models are compared with operational hindcasts as well as other AI models. Our results show that leveraging teleconnection information enhances skill at longer lead times. Notably, the ViT-LSTM outperforms ECMWF's subseasonal hindcasts beyond week 4 by improving Scandinavian Blocking (SB) and Atlantic Ridge (AR) predictions. Analysis of high-confidence predictions reveals that NAO-, SB, and AR opportunity forecasts can be associated with SPV variability and MJO phase patterns aligning with established pathways, also indicating new patterns. Overall, our work demonstrates that encoding physically meaningful climate fields can enhance S2S prediction skill, advancing AI-driven subseasonal forecast. Moreover, the experiments highlight the potential of deep learning methods as investigative tools, providing new insights into atmospheric dynamics and predictability.
CoSy: Evaluating Textual Explanations of Neurons
May 30, 2024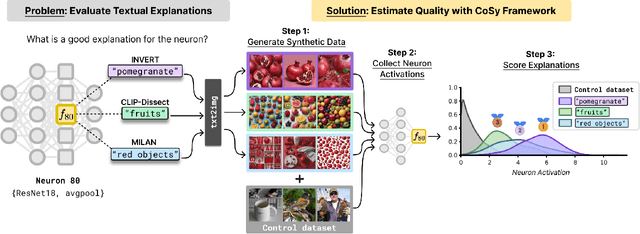


A crucial aspect of understanding the complex nature of Deep Neural Networks (DNNs) is the ability to explain learned concepts within their latent representations. While various methods exist to connect neurons to textual descriptions of human-understandable concepts, evaluating the quality of these explanation methods presents a major challenge in the field due to a lack of unified, general-purpose quantitative evaluation. In this work, we introduce CoSy (Concept Synthesis) -- a novel, architecture-agnostic framework to evaluate the quality of textual explanations for latent neurons. Given textual explanations, our proposed framework leverages a generative model conditioned on textual input to create data points representing the textual explanation. Then, the neuron's response to these explanation data points is compared with the response to control data points, providing a quality estimate of the given explanation. We ensure the reliability of our proposed framework in a series of meta-evaluation experiments and demonstrate practical value through insights from benchmarking various concept-based textual explanation methods for Computer Vision tasks, showing that tested explanation methods significantly differ in quality.
Manipulating Feature Visualizations with Gradient Slingshots
Jan 11, 2024
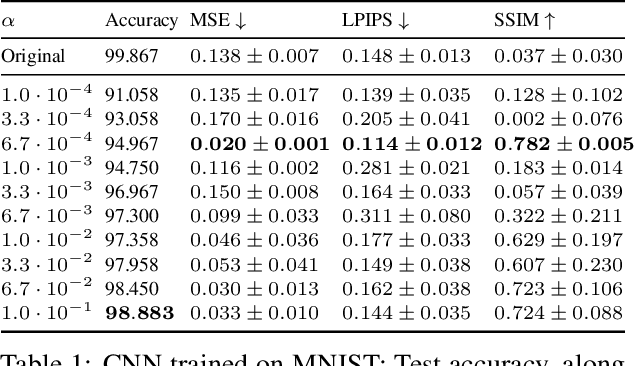
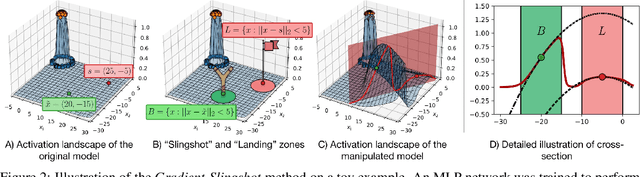
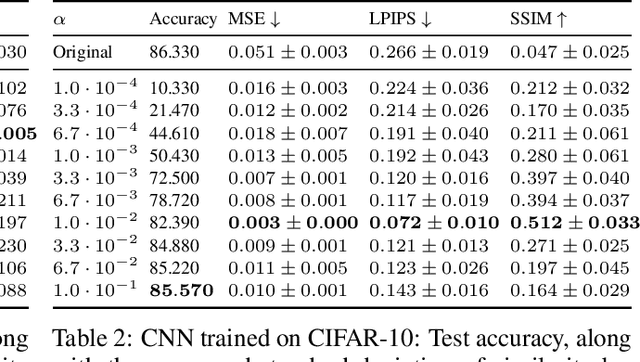
Deep Neural Networks (DNNs) are capable of learning complex and versatile representations, however, the semantic nature of the learned concepts remains unknown. A common method used to explain the concepts learned by DNNs is Activation Maximization (AM), which generates a synthetic input signal that maximally activates a particular neuron in the network. In this paper, we investigate the vulnerability of this approach to adversarial model manipulations and introduce a novel method for manipulating feature visualization without altering the model architecture or significantly impacting the model's decision-making process. We evaluate the effectiveness of our method on several neural network models and demonstrate its capabilities to hide the functionality of specific neurons by masking the original explanations of neurons with chosen target explanations during model auditing. As a remedy, we propose a protective measure against such manipulations and provide quantitative evidence which substantiates our findings.
Labeling Neural Representations with Inverse Recognition
Nov 22, 2023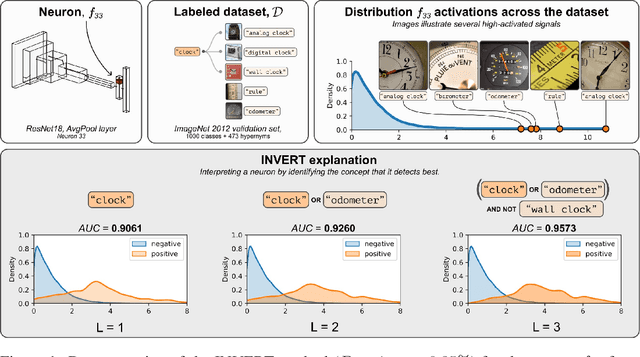

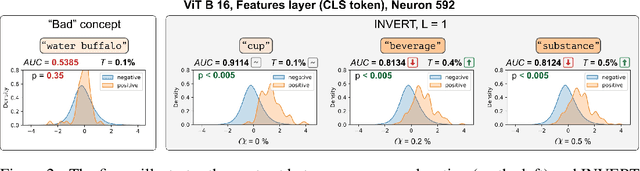
Deep Neural Networks (DNNs) demonstrated remarkable capabilities in learning complex hierarchical data representations, but the nature of these representations remains largely unknown. Existing global explainability methods, such as Network Dissection, face limitations such as reliance on segmentation masks, lack of statistical significance testing, and high computational demands. We propose Inverse Recognition (INVERT), a scalable approach for connecting learned representations with human-understandable concepts by leveraging their capacity to discriminate between these concepts. In contrast to prior work, INVERT is capable of handling diverse types of neurons, exhibits less computational complexity, and does not rely on the availability of segmentation masks. Moreover, INVERT provides an interpretable metric assessing the alignment between the representation and its corresponding explanation and delivering a measure of statistical significance, emphasizing its utility and credibility. We demonstrate the applicability of INVERT in various scenarios, including the identification of representations affected by spurious correlations, and the interpretation of the hierarchical structure of decision-making within the models.
* 24 pages, 16 figures
Mark My Words: Dangers of Watermarked Images in ImageNet
Mar 09, 2023



The utilization of pre-trained networks, especially those trained on ImageNet, has become a common practice in Computer Vision. However, prior research has indicated that a significant number of images in the ImageNet dataset contain watermarks, making pre-trained networks susceptible to learning artifacts such as watermark patterns within their latent spaces. In this paper, we aim to assess the extent to which popular pre-trained architectures display such behavior and to determine which classes are most affected. Additionally, we examine the impact of watermarks on the extracted features. Contrary to the popular belief that the Chinese logographic watermarks impact the "carton" class only, our analysis reveals that a variety of ImageNet classes, such as "monitor", "broom", "apron" and "safe" rely on spurious correlations. Finally, we propose a simple approach to mitigate this issue in fine-tuned networks by ignoring the encodings from the feature-extractor layer of ImageNet pre-trained networks that are most susceptible to watermark imprints.
DORA: Exploring outlier representations in Deep Neural Networks
Jun 09, 2022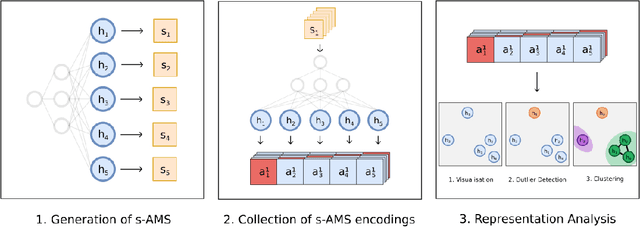
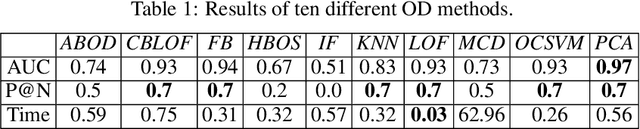
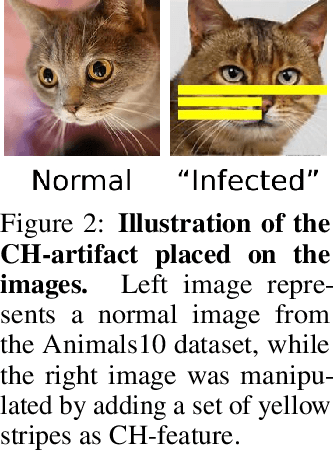
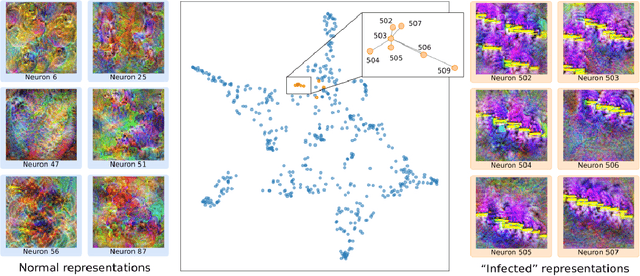
Deep Neural Networks (DNNs) draw their power from the representations they learn. In recent years, however, researchers have found that DNNs, while being incredibly effective in learning complex abstractions, also tend to be infected with artifacts, such as biases, Clever Hanses (CH), or Backdoors, due to spurious correlations inherent in the training data. So far, existing methods for uncovering such artifactual and malicious behavior in trained models focus on finding artifacts in the input data, which requires both availabilities of a data set and human intervention. In this paper, we introduce DORA (Data-agnOstic Representation Analysis): the first automatic data-agnostic method for the detection of potentially infected representations in Deep Neural Networks. We further show that contaminated representations found by DORA can be used to detect infected samples in any given dataset. We qualitatively and quantitatively evaluate the performance of our proposed method in both, controlled toy scenarios, and in real-world settings, where we demonstrate the benefit of DORA in safety-critical applications.
Visualizing the diversity of representations learned by Bayesian neural networks
Jan 26, 2022
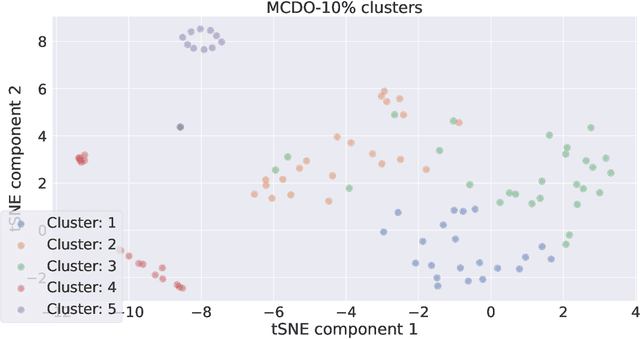


Explainable artificial intelligence (XAI) aims to make learning machines less opaque, and offers researchers and practitioners various tools to reveal the decision-making strategies of neural networks. In this work, we investigate how XAI methods can be used for exploring and visualizing the diversity of feature representations learned by Bayesian neural networks (BNNs). Our goal is to provide a global understanding of BNNs by making their decision-making strategies a) visible and tangible through feature visualizations and b) quantitatively measurable with a distance measure learned by contrastive learning. Our work provides new insights into the posterior distribution in terms of human-understandable feature information with regard to the underlying decision-making strategies. Our main findings are the following: 1) global XAI methods can be applied to explain the diversity of decision-making strategies of BNN instances, 2) Monte Carlo dropout exhibits increased diversity in feature representations compared to the multimodal posterior approximation of MultiSWAG, 3) the diversity of learned feature representations highly correlates with the uncertainty estimates, and 4) the inter-mode diversity of the multimodal posterior decreases as the network width increases, while the intra-mode diversity increases. Our findings are consistent with the recent deep neural networks theory, providing additional intuitions about what the theory implies in terms of humanly understandable concepts.
Explaining Bayesian Neural Networks
Aug 23, 2021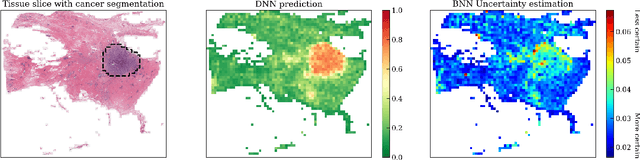
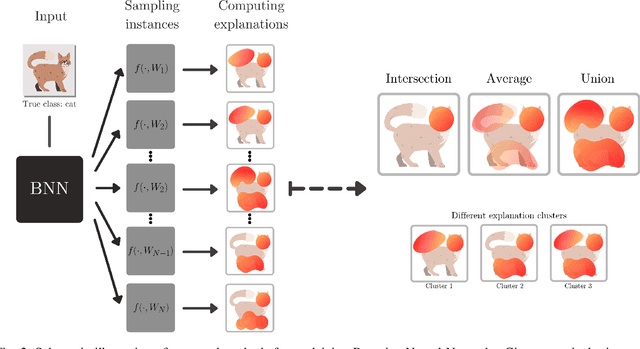
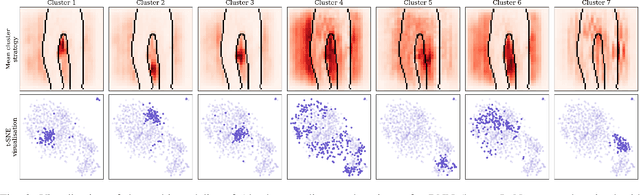
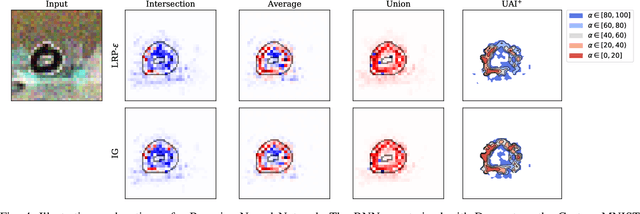
To make advanced learning machines such as Deep Neural Networks (DNNs) more transparent in decision making, explainable AI (XAI) aims to provide interpretations of DNNs' predictions. These interpretations are usually given in the form of heatmaps, each one illustrating relevant patterns regarding the prediction for a given instance. Bayesian approaches such as Bayesian Neural Networks (BNNs) so far have a limited form of transparency (model transparency) already built-in through their prior weight distribution, but notably, they lack explanations of their predictions for given instances. In this work, we bring together these two perspectives of transparency into a holistic explanation framework for explaining BNNs. Within the Bayesian framework, the network weights follow a probability distribution. Hence, the standard (deterministic) prediction strategy of DNNs extends in BNNs to a predictive distribution, and thus the standard explanation extends to an explanation distribution. Exploiting this view, we uncover that BNNs implicitly employ multiple heterogeneous prediction strategies. While some of these are inherited from standard DNNs, others are revealed to us by considering the inherent uncertainty in BNNs. Our quantitative and qualitative experiments on toy/benchmark data and real-world data from pathology show that the proposed approach of explaining BNNs can lead to more effective and insightful explanations.