 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFingerprinting Inference Systems of Large Language Models
May 28, 2026The behavior of LLMs does not depend solely on the model itself. Components of the inference system, such as the inference engine, attention backend, and hardware platform, subtly influence how inputs are processed. These components differ in their implementations and thereby induce small numerical deviations across systems when running the same model. While prior work has established the theoretical existence of such deviations, their security implications have remained unexplored. In this paper, we show that these deviations are characteristic of specific components and propagate to observable textual outputs, exposing the inference system to any party that can query the model. Building on this observation, we introduce a fingerprinting method that analyzes the prompt-response behavior of LLMs to identify components of the inference system. Our empirical evaluation demonstrates that the inference engine, attention backend, and underlying hardware platform can be identified reliably, even when the LLM is operated at non-zero temperature. We show that preventing fingerprinting is fundamentally hard, as it would require eliminating numerical differences between hardware and software stacks. We therefore propose partial mitigations and discuss their impact.
Measuring Security Without Fooling Ourselves: Why Benchmarking Agents Is Hard
May 21, 2026The benchmarks used to evaluate AI agents in security-critical roles suffer from crucial weaknesses. Building on recent empirical evidence, we characterize three core challenges that undermine security evaluations: benchmark vulnerabilities, temporal staleness, and runtime uncertainty. We then outline practical directions toward building more robust and trustworthy evaluation frameworks.
Hardware-Triggered Backdoors
Jan 29, 2026Machine learning models are routinely deployed on a wide range of computing hardware. Although such hardware is typically expected to produce identical results, differences in its design can lead to small numerical variations during inference. In this work, we show that these variations can be exploited to create backdoors in machine learning models. The core idea is to shape the model's decision function such that it yields different predictions for the same input when executed on different hardware. This effect is achieved by locally moving the decision boundary close to a target input and then refining numerical deviations to flip the prediction on selected hardware. We empirically demonstrate that these hardware-triggered backdoors can be created reliably across common GPU accelerators. Our findings reveal a novel attack vector affecting the use of third-party models, and we investigate different defenses to counter this threat.
Order in the Evaluation Court: A Critical Analysis of NLG Evaluation Trends
Jan 12, 2026Despite advances in Natural Language Generation (NLG), evaluation remains challenging. Although various new metrics and LLM-as-a-judge (LaaJ) methods are proposed, human judgment persists as the gold standard. To systematically review how NLG evaluation has evolved, we employ an automatic information extraction scheme to gather key information from NLG papers, focusing on different evaluation methods (metrics, LaaJ and human evaluation). With extracted metadata from 14,171 papers across four major conferences (ACL, EMNLP, NAACL, and INLG) over the past six years, we reveal several critical findings: (1) Task Divergence: While Dialogue Generation demonstrates a rapid shift toward LaaJ (>40% in 2025), Machine Translation remains locked into n-gram metrics, and Question Answering exhibits a substantial decline in the proportion of studies conducting human evaluation. (2) Metric Inertia: Despite the development of semantic metrics, general-purpose metrics (e.g., BLEU, ROUGE) continue to be widely used across tasks without empirical justification, often lacking the discriminative power to distinguish between specific quality criteria. (3) Human-LaaJ Divergence: Our association analysis challenges the assumption that LLMs act as mere proxies for humans; LaaJ and human evaluations prioritize very different signals, and explicit validation is scarce (<8% of papers comparing the two), with only moderate to low correlation. Based on these observations, we derive practical recommendations to improve the rigor of future NLG evaluation.
Adversarial Observations in Weather Forecasting
Apr 22, 2025AI-based systems, such as Google's GenCast, have recently redefined the state of the art in weather forecasting, offering more accurate and timely predictions of both everyday weather and extreme events. While these systems are on the verge of replacing traditional meteorological methods, they also introduce new vulnerabilities into the forecasting process. In this paper, we investigate this threat and present a novel attack on autoregressive diffusion models, such as those used in GenCast, capable of manipulating weather forecasts and fabricating extreme events, including hurricanes, heat waves, and intense rainfall. The attack introduces subtle perturbations into weather observations that are statistically indistinguishable from natural noise and change less than 0.1% of the measurements - comparable to tampering with data from a single meteorological satellite. As modern forecasting integrates data from nearly a hundred satellites and many other sources operated by different countries, our findings highlight a critical security risk with the potential to cause large-scale disruptions and undermine public trust in weather prediction.
On the Role of Pre-trained Embeddings in Binary Code Analysis
Feb 12, 2025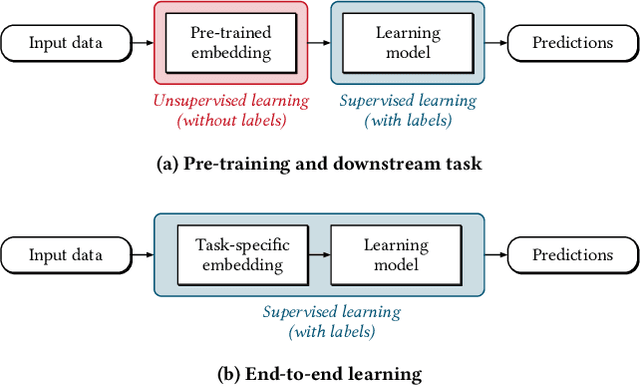

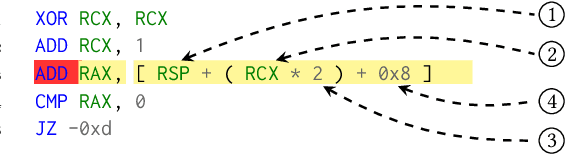
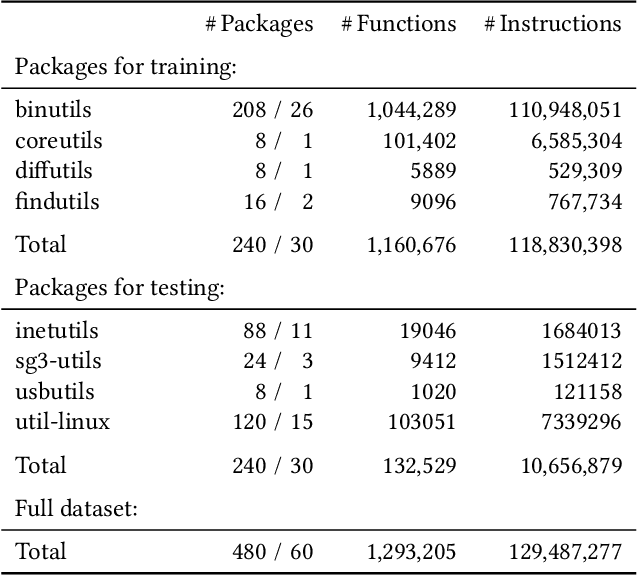
Deep learning has enabled remarkable progress in binary code analysis. In particular, pre-trained embeddings of assembly code have become a gold standard for solving analysis tasks, such as measuring code similarity or recognizing functions. These embeddings are capable of learning a vector representation from unlabeled code. In contrast to natural language processing, however, label information is not scarce for many tasks in binary code analysis. For example, labeled training data for function boundaries, optimization levels, and argument types can be easily derived from debug information provided by a compiler. Consequently, the main motivation of embeddings does not transfer directly to binary code analysis. In this paper, we explore the role of pre-trained embeddings from a critical perspective. To this end, we systematically evaluate recent embeddings for assembly code on five downstream tasks using a corpus of 1.2 million functions from the Debian distribution. We observe that several embeddings perform similarly when sufficient labeled data is available, and that differences reported in prior work are hardly noticeable. Surprisingly, we find that end-to-end learning without pre-training performs best on average, which calls into question the need for specialized embeddings. By varying the amount of labeled data, we eventually derive guidelines for when embeddings offer advantages and when end-to-end learning is preferable for binary code analysis.
Manipulating Feature Visualizations with Gradient Slingshots
Jan 11, 2024
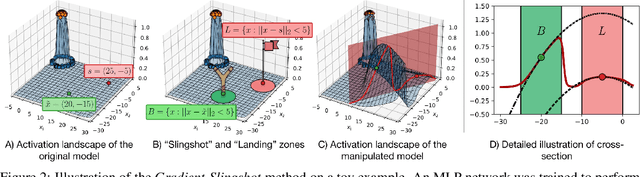
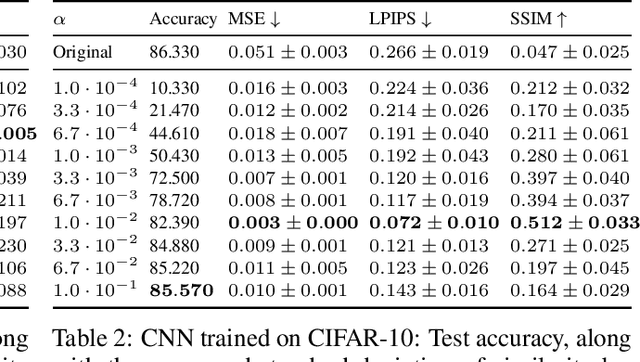
Deep Neural Networks (DNNs) are capable of learning complex and versatile representations, however, the semantic nature of the learned concepts remains unknown. A common method used to explain the concepts learned by DNNs is Activation Maximization (AM), which generates a synthetic input signal that maximally activates a particular neuron in the network. In this paper, we investigate the vulnerability of this approach to adversarial model manipulations and introduce a novel method for manipulating feature visualization without altering the model architecture or significantly impacting the model's decision-making process. We evaluate the effectiveness of our method on several neural network models and demonstrate its capabilities to hide the functionality of specific neurons by masking the original explanations of neurons with chosen target explanations during model auditing. As a remedy, we propose a protective measure against such manipulations and provide quantitative evidence which substantiates our findings.
On the Detection of Image-Scaling Attacks in Machine Learning
Oct 23, 2023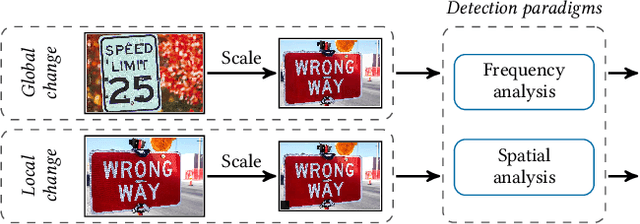



Image scaling is an integral part of machine learning and computer vision systems. Unfortunately, this preprocessing step is vulnerable to so-called image-scaling attacks where an attacker makes unnoticeable changes to an image so that it becomes a new image after scaling. This opens up new ways for attackers to control the prediction or to improve poisoning and backdoor attacks. While effective techniques exist to prevent scaling attacks, their detection has not been rigorously studied yet. Consequently, it is currently not possible to reliably spot these attacks in practice. This paper presents the first in-depth systematization and analysis of detection methods for image-scaling attacks. We identify two general detection paradigms and derive novel methods from them that are simple in design yet significantly outperform previous work. We demonstrate the efficacy of these methods in a comprehensive evaluation with all major learning platforms and scaling algorithms. First, we show that image-scaling attacks modifying the entire scaled image can be reliably detected even under an adaptive adversary. Second, we find that our methods provide strong detection performance even if only minor parts of the image are manipulated. As a result, we can introduce a novel protection layer against image-scaling attacks.
Learning Type Inference for Enhanced Dataflow Analysis
Oct 04, 2023Statically analyzing dynamically-typed code is a challenging endeavor, as even seemingly trivial tasks such as determining the targets of procedure calls are non-trivial without knowing the types of objects at compile time. Addressing this challenge, gradual typing is increasingly added to dynamically-typed languages, a prominent example being TypeScript that introduces static typing to JavaScript. Gradual typing improves the developer's ability to verify program behavior, contributing to robust, secure and debuggable programs. In practice, however, users only sparsely annotate types directly. At the same time, conventional type inference faces performance-related challenges as program size grows. Statistical techniques based on machine learning offer faster inference, but although recent approaches demonstrate overall improved accuracy, they still perform significantly worse on user-defined types than on the most common built-in types. Limiting their real-world usefulness even more, they rarely integrate with user-facing applications. We propose CodeTIDAL5, a Transformer-based model trained to reliably predict type annotations. For effective result retrieval and re-integration, we extract usage slices from a program's code property graph. Comparing our approach against recent neural type inference systems, our model outperforms the current state-of-the-art by 7.85% on the ManyTypes4TypeScript benchmark, achieving 71.27% accuracy overall. Furthermore, we present JoernTI, an integration of our approach into Joern, an open source static analysis tool, and demonstrate that the analysis benefits from the additional type information. As our model allows for fast inference times even on commodity CPUs, making our system available through Joern leads to high accessibility and facilitates security research.
* - fixed last author's name - fixed header
Evil from Within: Machine Learning Backdoors through Hardware Trojans
Apr 18, 2023



Backdoors pose a serious threat to machine learning, as they can compromise the integrity of security-critical systems, such as self-driving cars. While different defenses have been proposed to address this threat, they all rely on the assumption that the hardware on which the learning models are executed during inference is trusted. In this paper, we challenge this assumption and introduce a backdoor attack that completely resides within a common hardware accelerator for machine learning. Outside of the accelerator, neither the learning model nor the software is manipulated, so that current defenses fail. To make this attack practical, we overcome two challenges: First, as memory on a hardware accelerator is severely limited, we introduce the concept of a minimal backdoor that deviates as little as possible from the original model and is activated by replacing a few model parameters only. Second, we develop a configurable hardware trojan that can be provisioned with the backdoor and performs a replacement only when the specific target model is processed. We demonstrate the practical feasibility of our attack by implanting our hardware trojan into the Xilinx Vitis AI DPU, a commercial machine-learning accelerator. We configure the trojan with a minimal backdoor for a traffic-sign recognition system. The backdoor replaces only 30 (0.069%) model parameters, yet it reliably manipulates the recognition once the input contains a backdoor trigger. Our attack expands the hardware circuit of the accelerator by 0.24% and induces no run-time overhead, rendering a detection hardly possible. Given the complex and highly distributed manufacturing process of current hardware, our work points to a new threat in machine learning that is inaccessible to current security mechanisms and calls for hardware to be manufactured only in fully trusted environments.