 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI still know it's you! On Challenges in Anonymizing Source Code
Paper and Code
Aug 26, 2022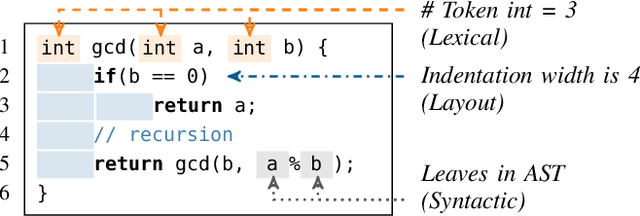
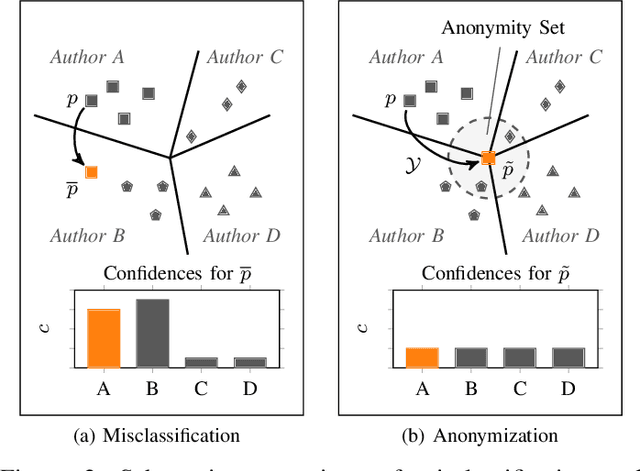

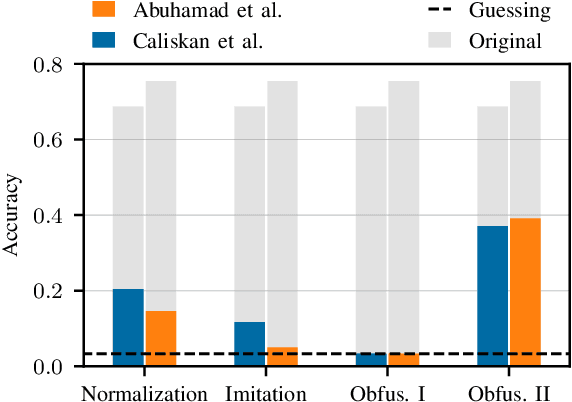
The source code of a program not only defines its semantics but also contains subtle clues that can identify its author. Several studies have shown that these clues can be automatically extracted using machine learning and allow for determining a program's author among hundreds of programmers. This attribution poses a significant threat to developers of anti-censorship and privacy-enhancing technologies, as they become identifiable and may be prosecuted. An ideal protection from this threat would be the anonymization of source code. However, neither theoretical nor practical principles of such an anonymization have been explored so far. In this paper, we tackle this problem and develop a framework for reasoning about code anonymization. We prove that the task of generating a $k$-anonymous program -- a program that cannot be attributed to one of $k$ authors -- is not computable and thus a dead end for research. As a remedy, we introduce a relaxed concept called $k$-uncertainty, which enables us to measure the protection of developers. Based on this concept, we empirically study candidate techniques for anonymization, such as code normalization, coding style imitation, and code obfuscation. We find that none of the techniques provides sufficient protection when the attacker is aware of the anonymization. While we introduce an approach for removing remaining clues from the code, the main result of our work is negative: Anonymization of source code is a hard and open problem.