 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo more Reviewer #2: Subverting Automatic Paper-Reviewer Assignment using Adversarial Learning
Mar 25, 2023



The number of papers submitted to academic conferences is steadily rising in many scientific disciplines. To handle this growth, systems for automatic paper-reviewer assignments are increasingly used during the reviewing process. These systems use statistical topic models to characterize the content of submissions and automate the assignment to reviewers. In this paper, we show that this automation can be manipulated using adversarial learning. We propose an attack that adapts a given paper so that it misleads the assignment and selects its own reviewers. Our attack is based on a novel optimization strategy that alternates between the feature space and problem space to realize unobtrusive changes to the paper. To evaluate the feasibility of our attack, we simulate the paper-reviewer assignment of an actual security conference (IEEE S&P) with 165 reviewers on the program committee. Our results show that we can successfully select and remove reviewers without access to the assignment system. Moreover, we demonstrate that the manipulated papers remain plausible and are often indistinguishable from benign submissions.
Verifiable and Provably Secure Machine Unlearning
Oct 17, 2022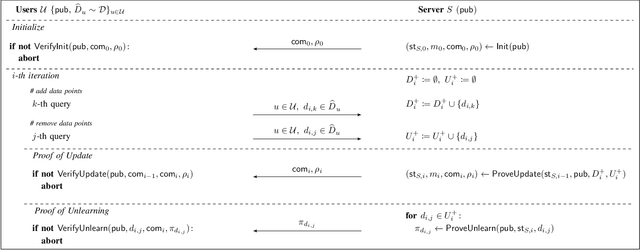



Machine unlearning aims to remove points from the training dataset of a machine learning model after training; for example when a user requests their data to be deleted. While many machine unlearning methods have been proposed, none of them enable users to audit the unlearning procedure and verify that their data was indeed unlearned. To address this, we define the first cryptographic framework to formally capture the security of verifiable machine unlearning. While our framework is generally applicable to different approaches, its advantages are perhaps best illustrated by our instantiation for the canonical approach to unlearning: retraining the model without the data to be unlearned. In our cryptographic protocol, the server first computes a proof that the model was trained on a dataset~$D$. Given a user data point $d$, the server then computes a proof of unlearning that shows that $d \notin D$. We realize our protocol using a SNARK and Merkle trees to obtain proofs of update and unlearning on the data. Based on cryptographic assumptions, we then present a formal game-based proof that our instantiation is secure. Finally, we validate the practicality of our constructions for unlearning in linear regression, logistic regression, and neural networks.