 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiable and Provably Secure Machine Unlearning
Oct 17, 2022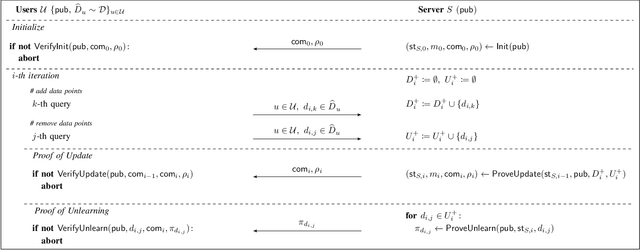



Machine unlearning aims to remove points from the training dataset of a machine learning model after training; for example when a user requests their data to be deleted. While many machine unlearning methods have been proposed, none of them enable users to audit the unlearning procedure and verify that their data was indeed unlearned. To address this, we define the first cryptographic framework to formally capture the security of verifiable machine unlearning. While our framework is generally applicable to different approaches, its advantages are perhaps best illustrated by our instantiation for the canonical approach to unlearning: retraining the model without the data to be unlearned. In our cryptographic protocol, the server first computes a proof that the model was trained on a dataset~$D$. Given a user data point $d$, the server then computes a proof of unlearning that shows that $d \notin D$. We realize our protocol using a SNARK and Merkle trees to obtain proofs of update and unlearning on the data. Based on cryptographic assumptions, we then present a formal game-based proof that our instantiation is secure. Finally, we validate the practicality of our constructions for unlearning in linear regression, logistic regression, and neural networks.
Active Data Pattern Extraction Attacks on Generative Language Models
Jul 14, 2022
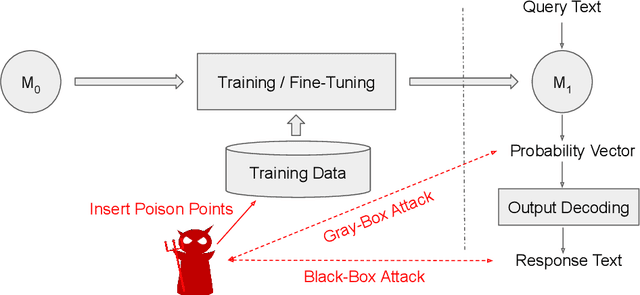

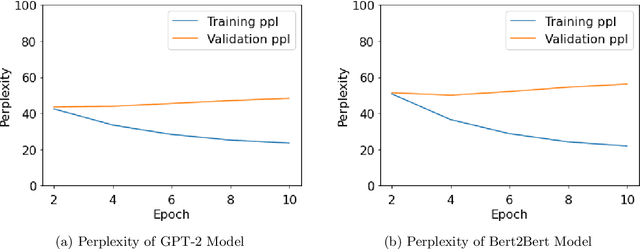
With the wide availability of large pre-trained language model checkpoints, such as GPT-2 and BERT, the recent trend has been to fine-tune them on a downstream task to achieve the state-of-the-art performance with a small computation overhead. One natural example is the Smart Reply application where a pre-trained model is fine-tuned for suggesting a number of responses given a query message. In this work, we set out to investigate potential information leakage vulnerabilities in a typical Smart Reply pipeline and show that it is possible for an adversary, having black-box or gray-box access to a Smart Reply model, to extract sensitive user information present in the training data. We further analyse the privacy impact of specific components, e.g. the decoding strategy, pertained to this application through our attack settings. We explore potential mitigation strategies and demonstrate how differential privacy can be a strong defense mechanism to such data extraction attacks.
Membership Inference on Word Embedding and Beyond
Jun 21, 2021


In the text processing context, most ML models are built on word embeddings. These embeddings are themselves trained on some datasets, potentially containing sensitive data. In some cases this training is done independently, in other cases, it occurs as part of training a larger, task-specific model. In either case, it is of interest to consider membership inference attacks based on the embedding layer as a way of understanding sensitive information leakage. But, somewhat surprisingly, membership inference attacks on word embeddings and their effect in other natural language processing (NLP) tasks that use these embeddings, have remained relatively unexplored. In this work, we show that word embeddings are vulnerable to black-box membership inference attacks under realistic assumptions. Furthermore, we show that this leakage persists through two other major NLP applications: classification and text-generation, even when the embedding layer is not exposed to the attacker. We show that our MI attack achieves high attack accuracy against a classifier model and an LSTM-based language model. Indeed, our attack is a cheaper membership inference attack on text-generative models, which does not require the knowledge of the target model or any expensive training of text-generative models as shadow models.
Property Inference From Poisoning
Jan 26, 2021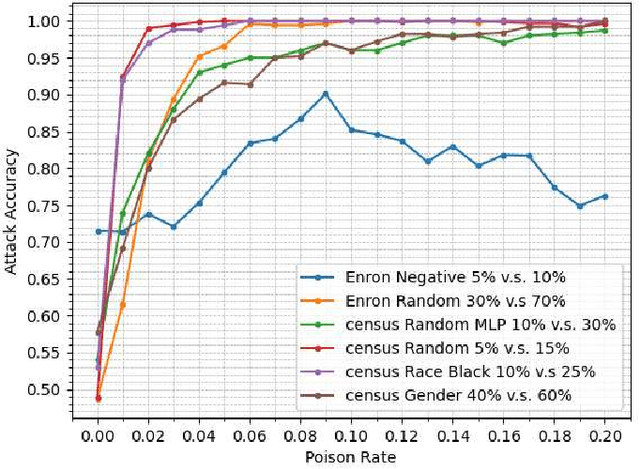
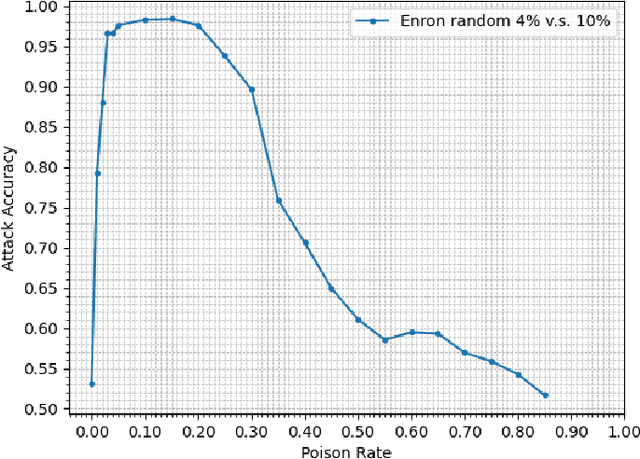
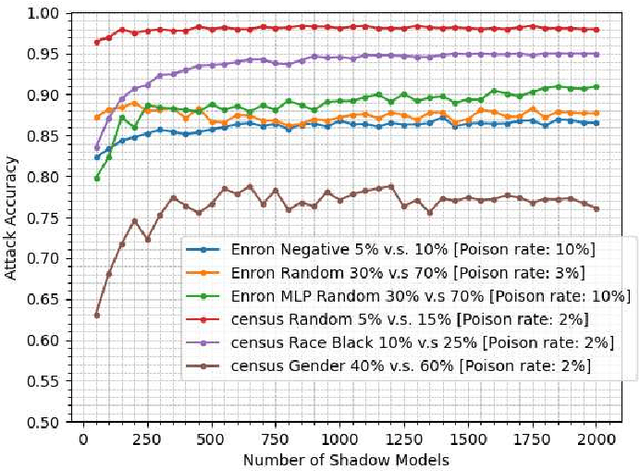
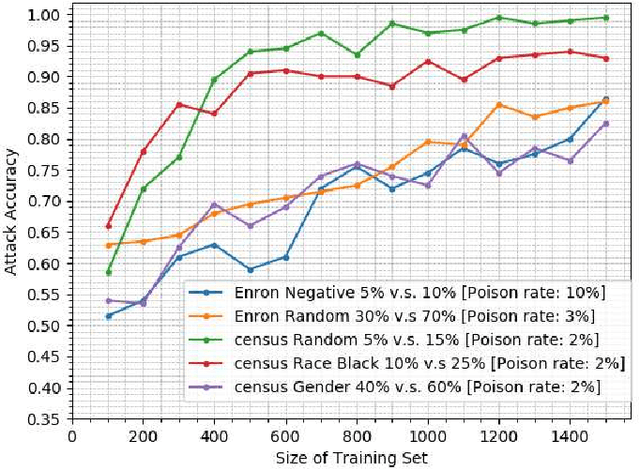
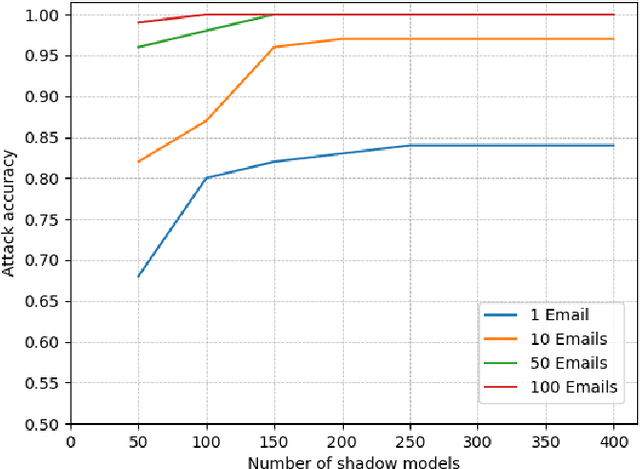
Property inference attacks consider an adversary who has access to the trained model and tries to extract some global statistics of the training data. In this work, we study property inference in scenarios where the adversary can maliciously control part of the training data (poisoning data) with the goal of increasing the leakage. Previous work on poisoning attacks focused on trying to decrease the accuracy of models either on the whole population or on specific sub-populations or instances. Here, for the first time, we study poisoning attacks where the goal of the adversary is to increase the information leakage of the model. Our findings suggest that poisoning attacks can boost the information leakage significantly and should be considered as a stronger threat model in sensitive applications where some of the data sources may be malicious. We describe our \emph{property inference poisoning attack} that allows the adversary to learn the prevalence in the training data of any property it chooses. We theoretically prove that our attack can always succeed as long as the learning algorithm used has good generalization properties. We then verify the effectiveness of our attack by experimentally evaluating it on two datasets: a Census dataset and the Enron email dataset. We were able to achieve above $90\%$ attack accuracy with $9-10\%$ poisoning in all of our experiments.