 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference on Word Embedding and Beyond
Jun 21, 2021


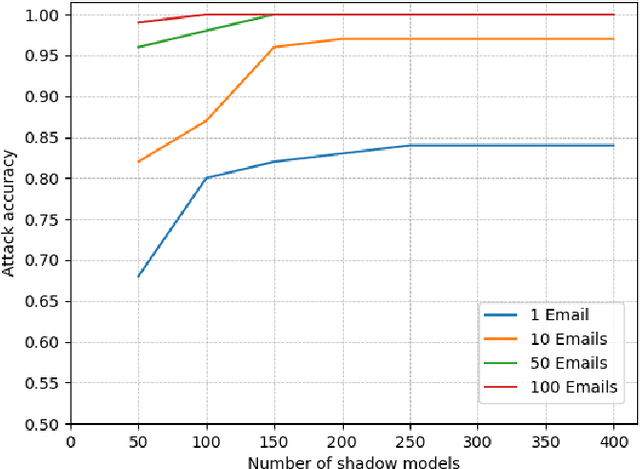
In the text processing context, most ML models are built on word embeddings. These embeddings are themselves trained on some datasets, potentially containing sensitive data. In some cases this training is done independently, in other cases, it occurs as part of training a larger, task-specific model. In either case, it is of interest to consider membership inference attacks based on the embedding layer as a way of understanding sensitive information leakage. But, somewhat surprisingly, membership inference attacks on word embeddings and their effect in other natural language processing (NLP) tasks that use these embeddings, have remained relatively unexplored. In this work, we show that word embeddings are vulnerable to black-box membership inference attacks under realistic assumptions. Furthermore, we show that this leakage persists through two other major NLP applications: classification and text-generation, even when the embedding layer is not exposed to the attacker. We show that our MI attack achieves high attack accuracy against a classifier model and an LSTM-based language model. Indeed, our attack is a cheaper membership inference attack on text-generative models, which does not require the knowledge of the target model or any expensive training of text-generative models as shadow models.
On Privacy and Confidentiality of Communications in Organizational Graphs
May 27, 2021
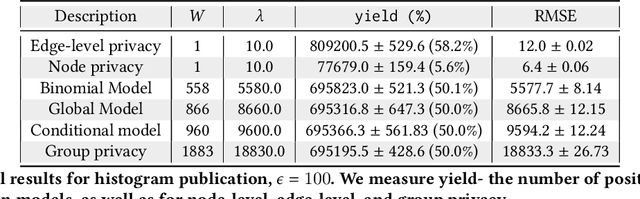
Machine learned models trained on organizational communication data, such as emails in an enterprise, carry unique risks of breaching confidentiality, even if the model is intended only for internal use. This work shows how confidentiality is distinct from privacy in an enterprise context, and aims to formulate an approach to preserving confidentiality while leveraging principles from differential privacy. The goal is to perform machine learning tasks, such as learning a language model or performing topic analysis, using interpersonal communications in the organization, while not learning about confidential information shared in the organization. Works that apply differential privacy techniques to natural language processing tasks usually assume independently distributed data, and overlook potential correlation among the records. Ignoring this correlation results in a fictional promise of privacy. Naively extending differential privacy techniques to focus on group privacy instead of record-level privacy is a straightforward approach to mitigate this issue. This approach, although providing a more realistic privacy-guarantee, is over-cautious and severely impacts model utility. We show this gap between these two extreme measures of privacy over two language tasks, and introduce a middle-ground solution. We propose a model that captures the correlation in the social network graph, and incorporates this correlation in the privacy calculations through Pufferfish privacy principles.
Privacy Regularization: Joint Privacy-Utility Optimization in Language Models
Mar 12, 2021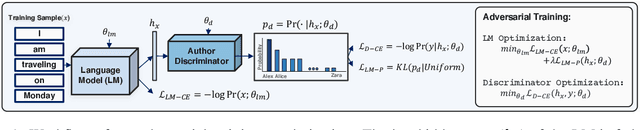
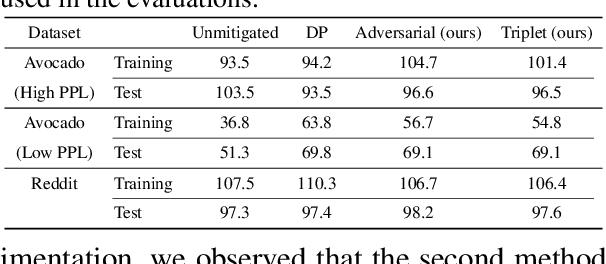
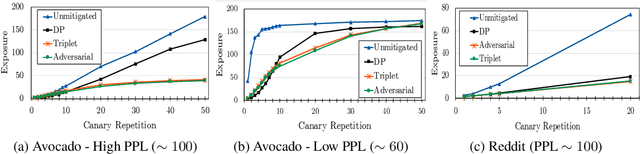

Neural language models are known to have a high capacity for memorization of training samples. This may have serious privacy implications when training models on user content such as email correspondence. Differential privacy (DP), a popular choice to train models with privacy guarantees, comes with significant costs in terms of utility degradation and disparate impact on subgroups of users. In this work, we introduce two privacy-preserving regularization methods for training language models that enable joint optimization of utility and privacy through (1) the use of a discriminator and (2) the inclusion of a triplet-loss term. We compare our methods with DP through extensive evaluation. We show the advantages of our regularizers with favorable utility-privacy trade-off, faster training with the ability to tap into existing optimization approaches, and ensuring uniform treatment of under-represented subgroups.
Smart To-Do : Automatic Generation of To-Do Items from Emails
May 05, 2020

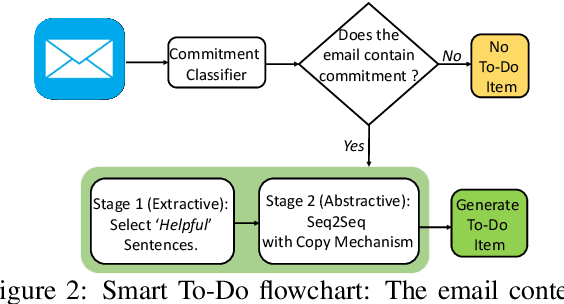
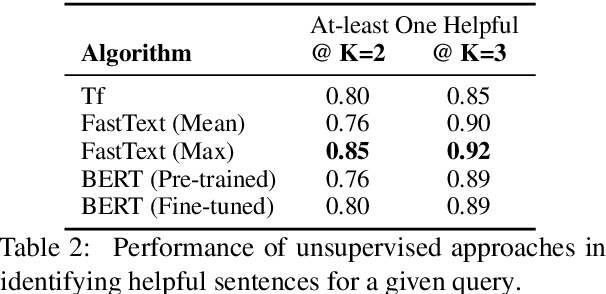
Intelligent features in email service applications aim to increase productivity by helping people organize their folders, compose their emails and respond to pending tasks. In this work, we explore a new application, Smart-To-Do, that helps users with task management over emails. We introduce a new task and dataset for automatically generating To-Do items from emails where the sender has promised to perform an action. We design a two-stage process leveraging recent advances in neural text generation and sequence-to-sequence learning, obtaining BLEU and ROUGE scores of 0:23 and 0:63 for this task. To the best of our knowledge, this is the first work to address the problem of composing To-Do items from emails.