 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Graphs: Separating Knowledge Exploration from Outline Structure for Open-Ended Deep Research
Feb 14, 2026Open-Ended Deep Research (OEDR) pushes LLM agents beyond short-form QA toward long-horizon workflows that iteratively search, connect, and synthesize evidence into structured reports. However, existing OEDR agents largely follow either linear ``search-then-generate'' accumulation or outline-centric planning. The former suffers from lost-in-the-middle failures as evidence grows, while the latter relies on the LLM to implicitly infer knowledge gaps from the outline alone, providing weak supervision for identifying missing relations and triggering targeted exploration. We present DualGraph memory, an architecture that separates what the agent knows from how it writes. DualGraph maintains two co-evolving graphs: an Outline Graph (OG), and a Knowledge Graph (KG), a semantic memory that stores fine-grained knowledge units, including core entities, concepts, and their relations. By analyzing the KG topology together with structural signals from the OG, DualGraph generates targeted search queries, enabling more efficient and comprehensive iterative knowledge-driven exploration and refinement. Across DeepResearch Bench, DeepResearchGym, and DeepConsult, DualGraph consistently outperforms state-of-the-art baselines in report depth, breadth, and factual grounding; for example, it reaches a 53.08 RACE score on DeepResearch Bench with GPT-5. Moreover, ablation studies confirm the central role of the dual-graph design.
LEGOMem: Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation
Oct 06, 2025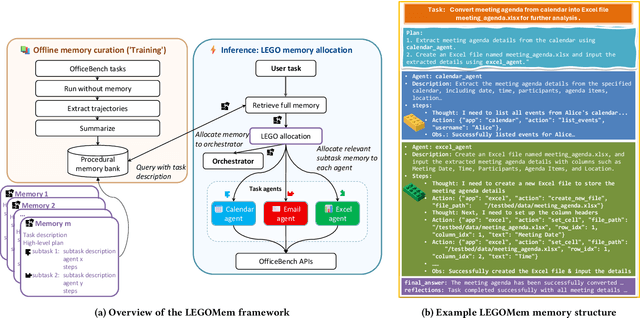
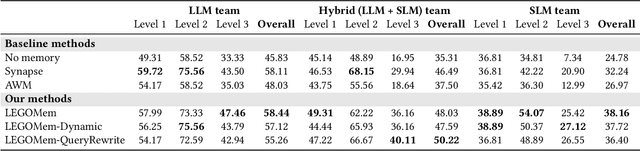
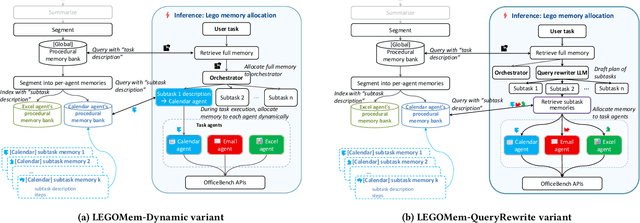
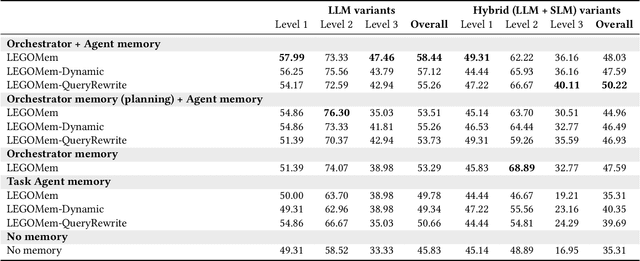
We introduce LEGOMem, a modular procedural memory framework for multi-agent large language model (LLM) systems in workflow automation. LEGOMem decomposes past task trajectories into reusable memory units and flexibly allocates them across orchestrators and task agents to support planning and execution. To explore the design space of memory in multi-agent systems, we use LEGOMem as a lens and conduct a systematic study of procedural memory in multi-agent systems, examining where memory should be placed, how it should be retrieved, and which agents benefit most. Experiments on the OfficeBench benchmark show that orchestrator memory is critical for effective task decomposition and delegation, while fine-grained agent memory improves execution accuracy. We find that even teams composed of smaller language models can benefit substantially from procedural memory, narrowing the performance gap with stronger agents by leveraging prior execution traces for more accurate planning and tool use. These results position LEGOMem as both a practical framework for memory-augmented agent systems and a research tool for understanding memory design in multi-agent workflow automation.
OdysseyBench: Evaluating LLM Agents on Long-Horizon Complex Office Application Workflows
Aug 12, 2025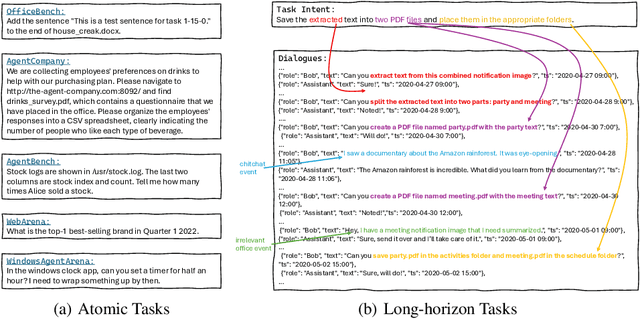
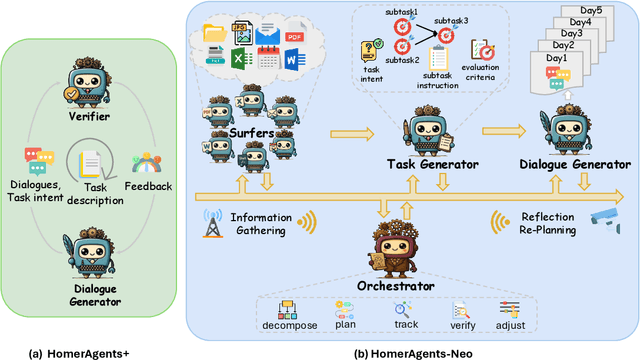
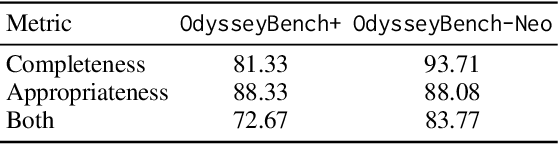
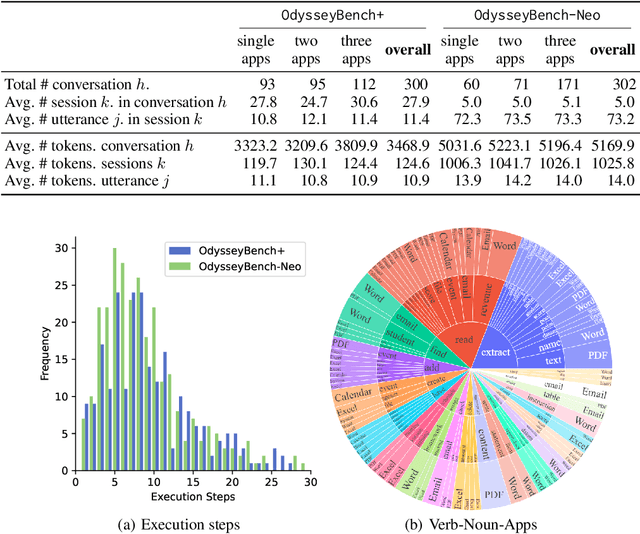
Autonomous agents powered by large language models (LLMs) are increasingly deployed in real-world applications requiring complex, long-horizon workflows. However, existing benchmarks predominantly focus on atomic tasks that are self-contained and independent, failing to capture the long-term contextual dependencies and multi-interaction coordination required in realistic scenarios. To address this gap, we introduce OdysseyBench, a comprehensive benchmark for evaluating LLM agents on long-horizon workflows across diverse office applications including Word, Excel, PDF, Email, and Calendar. Our benchmark comprises two complementary splits: OdysseyBench+ with 300 tasks derived from real-world use cases, and OdysseyBench-Neo with 302 newly synthesized complex tasks. Each task requires agent to identify essential information from long-horizon interaction histories and perform multi-step reasoning across various applications. To enable scalable benchmark creation, we propose HomerAgents, a multi-agent framework that automates the generation of long-horizon workflow benchmarks through systematic environment exploration, task generation, and dialogue synthesis. Our extensive evaluation demonstrates that OdysseyBench effectively challenges state-of-the-art LLM agents, providing more accurate assessment of their capabilities in complex, real-world contexts compared to existing atomic task benchmarks. We believe that OdysseyBench will serve as a valuable resource for advancing the development and evaluation of LLM agents in real-world productivity scenarios. In addition, we release OdysseyBench and HomerAgents to foster research along this line.
Enhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search
Jun 10, 2025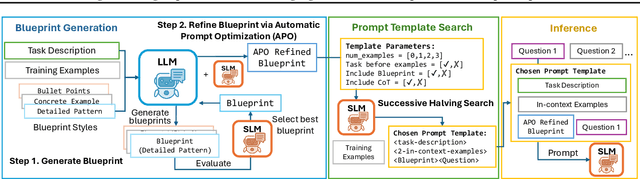
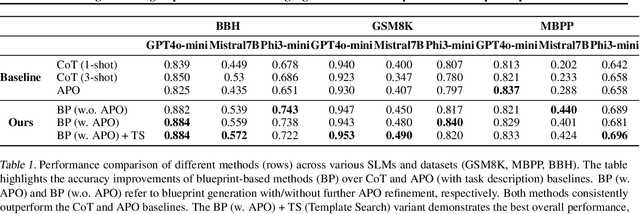


Small language models (SLMs) offer promising and efficient alternatives to large language models (LLMs). However, SLMs' limited capacity restricts their reasoning capabilities and makes them sensitive to prompt variations. To address these challenges, we propose a novel framework that enhances SLM reasoning capabilities through LLM generated blueprints. The blueprints provide structured, high-level reasoning guides that help SLMs systematically tackle related problems. Furthermore, our framework integrates a prompt template search mechanism to mitigate the SLMs' sensitivity to prompt variations. Our framework demonstrates improved SLM performance across various tasks, including math (GSM8K), coding (MBPP), and logic reasoning (BBH). Our approach improves the reasoning capabilities of SLMs without increasing model size or requiring additional training, offering a lightweight and deployment-friendly solution for on-device or resource-constrained environments.
Semantic Caching of Contextual Summaries for Efficient Question-Answering with Language Models
May 16, 2025Large Language Models (LLMs) are increasingly deployed across edge and cloud platforms for real-time question-answering and retrieval-augmented generation. However, processing lengthy contexts in distributed systems incurs high computational overhead, memory usage, and network bandwidth. This paper introduces a novel semantic caching approach for storing and reusing intermediate contextual summaries, enabling efficient information reuse across similar queries in LLM-based QA workflows. Our method reduces redundant computations by up to 50-60% while maintaining answer accuracy comparable to full document processing, as demonstrated on NaturalQuestions, TriviaQA, and a synthetic ArXiv dataset. This approach balances computational cost and response quality, critical for real-time AI assistants.
Ensuring Fair LLM Serving Amid Diverse Applications
Nov 24, 2024
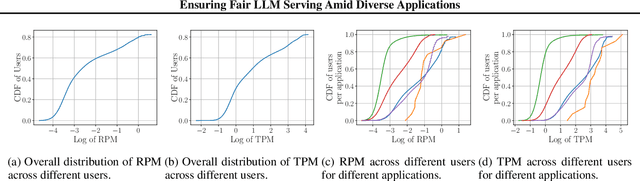
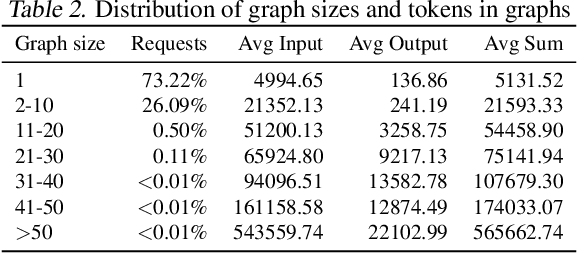
In a multi-tenant large language model (LLM) serving platform hosting diverse applications, some users may submit an excessive number of requests, causing the service to become unavailable to other users and creating unfairness. Existing fairness approaches do not account for variations in token lengths across applications and multiple LLM calls, making them unsuitable for such platforms. To address the fairness challenge, this paper analyzes millions of requests from thousands of users on MS CoPilot, a real-world multi-tenant LLM platform hosted by Microsoft. Our analysis confirms the inadequacy of existing methods and guides the development of FairServe, a system that ensures fair LLM access across diverse applications. FairServe proposes application-characteristic aware request throttling coupled with a weighted service counter based scheduling technique to curb abusive behavior and ensure fairness. Our experimental results on real-world traces demonstrate FairServe's superior performance compared to the state-of-the-art method in ensuring fairness. We are actively working on deploying our system in production, expecting to benefit millions of customers world-wide.
EcoAct: Economic Agent Determines When to Register What Action
Nov 03, 2024



Recent advancements have enabled Large Language Models (LLMs) to function as agents that can perform actions using external tools. This requires registering, i.e., integrating tool information into the LLM context prior to taking actions. Current methods indiscriminately incorporate all candidate tools into the agent's context and retain them across multiple reasoning steps. This process remains opaque to LLM agents and is not integrated into their reasoning procedures, leading to inefficiencies due to increased context length from irrelevant tools. To address this, we introduce EcoAct, a tool using algorithm that allows LLMs to selectively register tools as needed, optimizing context use. By integrating the tool registration process into the reasoning procedure, EcoAct reduces computational costs by over 50% in multiple steps reasoning tasks while maintaining performance, as demonstrated through extensive experiments. Moreover, it can be plugged into any reasoning pipeline with only minor modifications to the prompt, making it applicable to LLM agents now and future.
Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
May 17, 2024
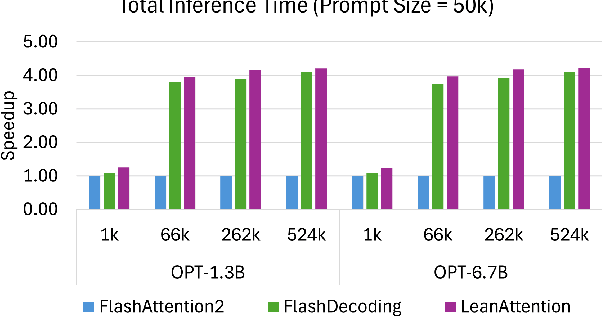


Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the "stream-K" style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Mar 19, 2024



This paper focuses on task-agnostic prompt compression for better generalizability and efficiency. Considering the redundancy in natural language, existing approaches compress prompts by removing tokens or lexical units according to their information entropy obtained from a causal language model such as LLaMa-7B. The challenge is that information entropy may be a suboptimal compression metric: (i) it only leverages unidirectional context and may fail to capture all essential information needed for prompt compression; (ii) it is not aligned with the prompt compression objective. To address these issues, we propose a data distillation procedure to derive knowledge from an LLM to compress prompts without losing crucial information, and meantime, introduce an extractive text compression dataset. We formulate prompt compression as a token classification problem to guarantee the faithfulness of the compressed prompt to the original one, and use a Transformer encoder as the base architecture to capture all essential information for prompt compression from the full bidirectional context. Our approach leads to lower latency by explicitly learning the compression objective with smaller models such as XLM-RoBERTa-large and mBERT. We evaluate our method on both in-domain and out-of-domain datasets, including MeetingBank, LongBench, ZeroScrolls, GSM8K, and BBH. Despite its small size, our model shows significant performance gains over strong baselines and demonstrates robust generalization ability across different LLMs. Additionally, our model is 3x-6x faster than existing prompt compression methods, while accelerating the end-to-end latency by 1.6x-2.9x with compression ratios of 2x-5x.
Unlocking Spatial Comprehension in Text-to-Image Diffusion Models
Nov 28, 2023



We propose CompFuser, an image generation pipeline that enhances spatial comprehension and attribute assignment in text-to-image generative models. Our pipeline enables the interpretation of instructions defining spatial relationships between objects in a scene, such as `An image of a gray cat on the left of an orange dog', and generate corresponding images. This is especially important in order to provide more control to the user. CompFuser overcomes the limitation of existing text-to-image diffusion models by decoding the generation of multiple objects into iterative steps: first generating a single object and then editing the image by placing additional objects in their designated positions. To create training data for spatial comprehension and attribute assignment we introduce a synthetic data generation process, that leverages a frozen large language model and a frozen layout-based diffusion model for object placement. We compare our approach to strong baselines and show that our model outperforms state-of-the-art image generation models in spatial comprehension and attribute assignment, despite being 3x to 5x smaller in parameters.