 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Enhanced Entity Recommendation for Intelligent Monitoring in Cloud Systems
Oct 23, 2025In this paper, we present DiRecGNN, an attention-enhanced entity recommendation framework for monitoring cloud services at Microsoft. We provide insights on the usefulness of this feature as perceived by the cloud service owners and lessons learned from deployment. Specifically, we introduce the problem of recommending the optimal subset of attributes (dimensions) that should be tracked by an automated watchdog (monitor) for cloud services. To begin, we construct the monitor heterogeneous graph at production-scale. The interaction dynamics of these entities are often characterized by limited structural and engagement information, resulting in inferior performance of state-of-the-art approaches. Moreover, traditional methods fail to capture the dependencies between entities spanning a long range due to their homophilic nature. Therefore, we propose an attention-enhanced entity ranking model inspired by transformer architectures. Our model utilizes a multi-head attention mechanism to focus on heterogeneous neighbors and their attributes, and further attends to paths sampled using random walks to capture long-range dependencies. We also employ multi-faceted loss functions to optimize for relevant recommendations while respecting the inherent sparsity of the data. Empirical evaluations demonstrate significant improvements over existing methods, with our model achieving a 43.1% increase in MRR. Furthermore, product teams who consumed these features perceive the feature as useful and rated it 4.5 out of 5.
AI Greenferencing: Routing AI Inferencing to Green Modular Data Centers with Heron
May 15, 2025AI power demand is growing unprecedentedly thanks to the high power density of AI compute and the emerging inferencing workload. On the supply side, abundant wind power is waiting for grid access in interconnection queues. In this light, this paper argues bringing AI workload to modular compute clusters co-located in wind farms. Our deployment right-sizing strategy makes it economically viable to deploy more than 6 million high-end GPUs today that could consume cheap, green power at its source. We built Heron, a cross-site software router, that could efficiently leverage the complementarity of power generation across wind farms by routing AI inferencing workload around power drops. Using 1-week ofcoding and conversation production traces from Azure and (real) variable wind power traces, we show how Heron improves aggregate goodput of AI compute by up to 80% compared to the state-of-the-art.
Ensuring Fair LLM Serving Amid Diverse Applications
Nov 24, 2024
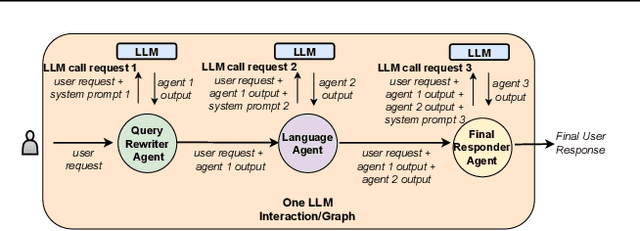
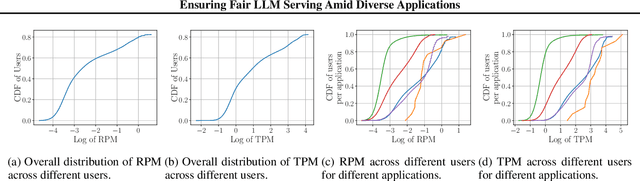
In a multi-tenant large language model (LLM) serving platform hosting diverse applications, some users may submit an excessive number of requests, causing the service to become unavailable to other users and creating unfairness. Existing fairness approaches do not account for variations in token lengths across applications and multiple LLM calls, making them unsuitable for such platforms. To address the fairness challenge, this paper analyzes millions of requests from thousands of users on MS CoPilot, a real-world multi-tenant LLM platform hosted by Microsoft. Our analysis confirms the inadequacy of existing methods and guides the development of FairServe, a system that ensures fair LLM access across diverse applications. FairServe proposes application-characteristic aware request throttling coupled with a weighted service counter based scheduling technique to curb abusive behavior and ensure fairness. Our experimental results on real-world traces demonstrate FairServe's superior performance compared to the state-of-the-art method in ensuring fairness. We are actively working on deploying our system in production, expecting to benefit millions of customers world-wide.
Streetwise Agents: Empowering Offline RL Policies to Outsmart Exogenous Stochastic Disturbances in RTC
Nov 11, 2024



The difficulty of exploring and training online on real production systems limits the scope of real-time online data/feedback-driven decision making. The most feasible approach is to adopt offline reinforcement learning from limited trajectory samples. However, after deployment, such policies fail due to exogenous factors that temporarily or permanently disturb/alter the transition distribution of the assumed decision process structure induced by offline samples. This results in critical policy failures and generalization errors in sensitive domains like Real-Time Communication (RTC). We solve this crucial problem of identifying robust actions in presence of domain shifts due to unseen exogenous stochastic factors in the wild. As it is impossible to learn generalized offline policies within the support of offline data that are robust to these unseen exogenous disturbances, we propose a novel post-deployment shaping of policies (Streetwise), conditioned on real-time characterization of out-of-distribution sub-spaces. This leads to robust actions in bandwidth estimation (BWE) of network bottlenecks in RTC and in standard benchmarks. Our extensive experimental results on BWE and other standard offline RL benchmark environments demonstrate a significant improvement ($\approx$ 18% on some scenarios) in final returns wrt. end-user metrics over state-of-the-art baselines.
Intelligent Monitoring Framework for Cloud Services: A Data-Driven Approach
Feb 29, 2024


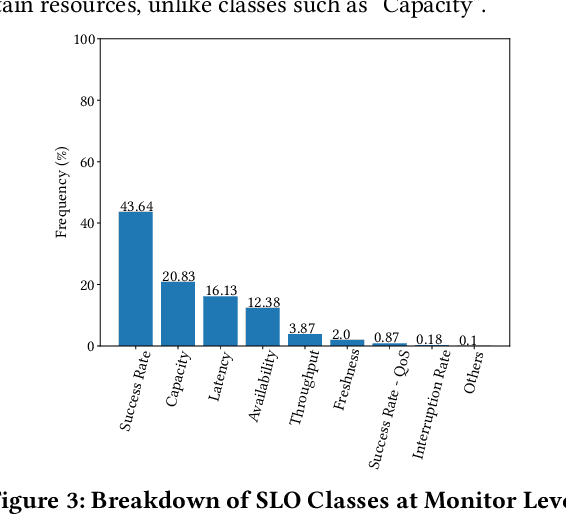
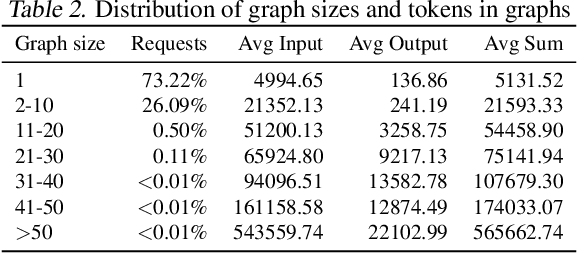
Cloud service owners need to continuously monitor their services to ensure high availability and reliability. Gaps in monitoring can lead to delay in incident detection and significant negative customer impact. Current process of monitor creation is ad-hoc and reactive in nature. Developers create monitors using their tribal knowledge and, primarily, a trial and error based process. As a result, monitors often have incomplete coverage which leads to production issues, or, redundancy which results in noise and wasted effort. In this work, we address this issue by proposing an intelligent monitoring framework that recommends monitors for cloud services based on their service properties. We start by mining the attributes of 30,000+ monitors from 791 production services at Microsoft and derive a structured ontology for monitors. We focus on two crucial dimensions: what to monitor (resources) and which metrics to monitor. We conduct an extensive empirical study and derive key insights on the major classes of monitors employed by cloud services at Microsoft, their associated dimensions, and the interrelationship between service properties and this ontology. Using these insights, we propose a deep learning based framework that recommends monitors based on the service properties. Finally, we conduct a user study with engineers from Microsoft which demonstrates the usefulness of the proposed framework. The proposed framework along with the ontology driven projections, succeeded in creating production quality recommendations for majority of resource classes. This was also validated by the users from the study who rated the framework's usefulness as 4.27 out of 5.
On the Hidden Biases of Policy Mirror Ascent in Continuous Action Spaces
Jan 31, 2022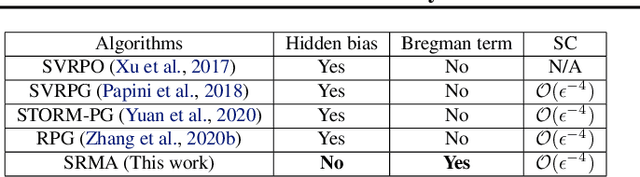

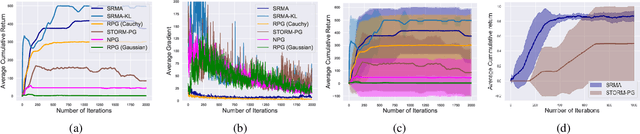
We focus on parameterized policy search for reinforcement learning over continuous action spaces. Typically, one assumes the score function associated with a policy is bounded, which fails to hold even for Gaussian policies. To properly address this issue, one must introduce an exploration tolerance parameter to quantify the region in which it is bounded. Doing so incurs a persistent bias that appears in the attenuation rate of the expected policy gradient norm, which is inversely proportional to the radius of the action space. To mitigate this hidden bias, heavy-tailed policy parameterizations may be used, which exhibit a bounded score function, but doing so can cause instability in algorithmic updates. To address these issues, in this work, we study the convergence of policy gradient algorithms under heavy-tailed parameterizations, which we propose to stabilize with a combination of mirror ascent-type updates and gradient tracking. Our main theoretical contribution is the establishment that this scheme converges with constant step and batch sizes, whereas prior works require these parameters to respectively shrink to null or grow to infinity. Experimentally, this scheme under a heavy-tailed policy parameterization yields improved reward accumulation across a variety of settings as compared with standard benchmarks.
On the Sample Complexity and Metastability of Heavy-tailed Policy Search in Continuous Control
Jun 15, 2021

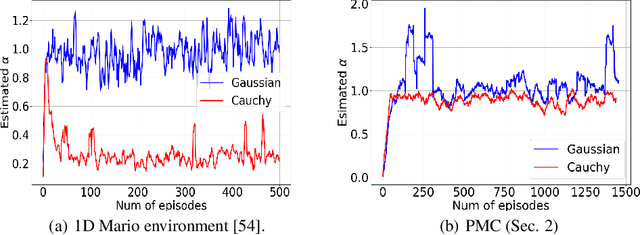

Reinforcement learning is a framework for interactive decision-making with incentives sequentially revealed across time without a system dynamics model. Due to its scaling to continuous spaces, we focus on policy search where one iteratively improves a parameterized policy with stochastic policy gradient (PG) updates. In tabular Markov Decision Problems (MDPs), under persistent exploration and suitable parameterization, global optimality may be obtained. By contrast, in continuous space, the non-convexity poses a pathological challenge as evidenced by existing convergence results being mostly limited to stationarity or arbitrary local extrema. To close this gap, we step towards persistent exploration in continuous space through policy parameterizations defined by distributions of heavier tails defined by tail-index parameter alpha, which increases the likelihood of jumping in state space. Doing so invalidates smoothness conditions of the score function common to PG. Thus, we establish how the convergence rate to stationarity depends on the policy's tail index alpha, a Holder continuity parameter, integrability conditions, and an exploration tolerance parameter introduced here for the first time. Further, we characterize the dependence of the set of local maxima on the tail index through an exit and transition time analysis of a suitably defined Markov chain, identifying that policies associated with Levy Processes of a heavier tail converge to wider peaks. This phenomenon yields improved stability to perturbations in supervised learning, which we corroborate also manifests in improved performance of policy search, especially when myopic and farsighted incentives are misaligned.
A Decentralized Approach to Bayesian Learning
Jul 14, 2020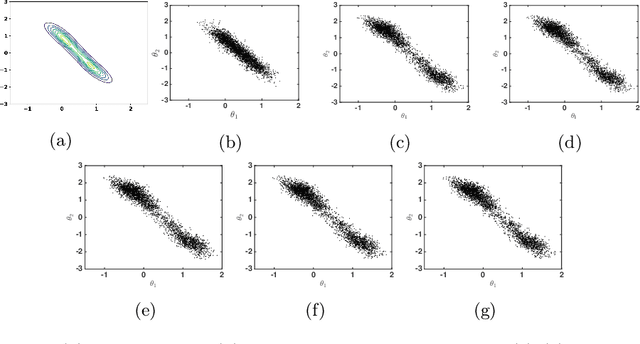
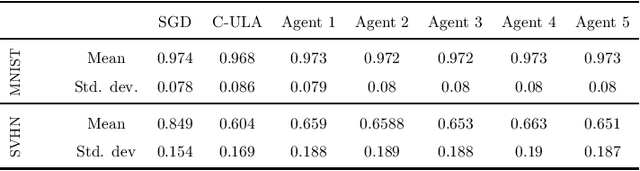
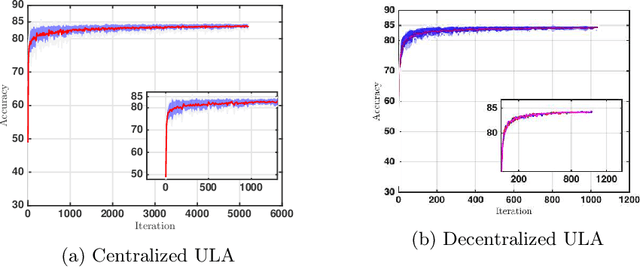
Motivated by decentralized approaches to machine learning, we propose a collaborative Bayesian learning algorithm taking the form of decentralized Langevin dynamics in a non-convex setting. Our analysis show that the initial KL-divergence between the Markov Chain and the target posterior distribution is exponentially decreasing while the error contributions to the overall KL-divergence from the additive noise is decreasing in polynomial time. We further show that the polynomial-term experiences speed-up with number of agents and provide sufficient conditions on the time-varying step-sizes to guarantee convergence to the desired distribution. The performance of the proposed algorithm is evaluated on a wide variety of machine learning tasks. The empirical results show that the performance of individual agents with locally available data is on par with the centralized setting with considerable improvement in the convergence rate.