 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreetwise Agents: Empowering Offline RL Policies to Outsmart Exogenous Stochastic Disturbances in RTC
Nov 11, 2024



The difficulty of exploring and training online on real production systems limits the scope of real-time online data/feedback-driven decision making. The most feasible approach is to adopt offline reinforcement learning from limited trajectory samples. However, after deployment, such policies fail due to exogenous factors that temporarily or permanently disturb/alter the transition distribution of the assumed decision process structure induced by offline samples. This results in critical policy failures and generalization errors in sensitive domains like Real-Time Communication (RTC). We solve this crucial problem of identifying robust actions in presence of domain shifts due to unseen exogenous stochastic factors in the wild. As it is impossible to learn generalized offline policies within the support of offline data that are robust to these unseen exogenous disturbances, we propose a novel post-deployment shaping of policies (Streetwise), conditioned on real-time characterization of out-of-distribution sub-spaces. This leads to robust actions in bandwidth estimation (BWE) of network bottlenecks in RTC and in standard benchmarks. Our extensive experimental results on BWE and other standard offline RL benchmark environments demonstrate a significant improvement ($\approx$ 18% on some scenarios) in final returns wrt. end-user metrics over state-of-the-art baselines.
COIN: Chance-Constrained Imitation Learning for Uncertainty-aware Adaptive Resource Oversubscription Policy
Jan 13, 2024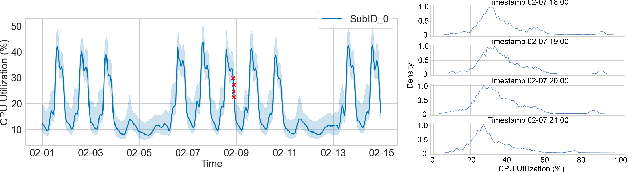
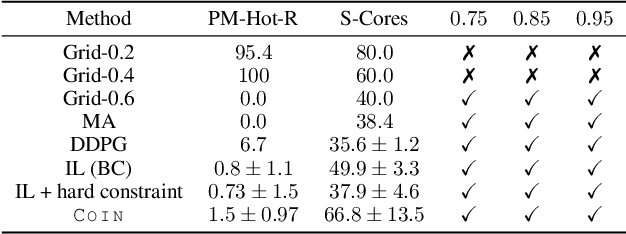
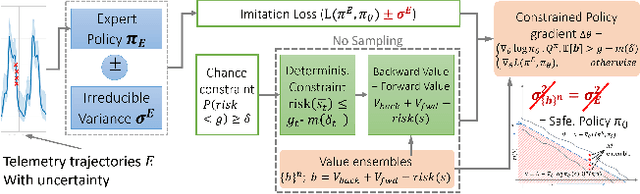
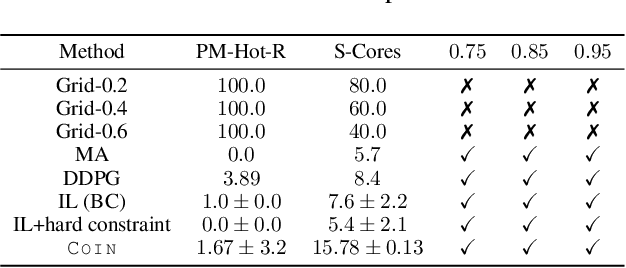
We address the challenge of learning safe and robust decision policies in presence of uncertainty in context of the real scientific problem of adaptive resource oversubscription to enhance resource efficiency while ensuring safety against resource congestion risk. Traditional supervised prediction or forecasting models are ineffective in learning adaptive policies whereas standard online optimization or reinforcement learning is difficult to deploy on real systems. Offline methods such as imitation learning (IL) are ideal since we can directly leverage historical resource usage telemetry. But, the underlying aleatoric uncertainty in such telemetry is a critical bottleneck. We solve this with our proposed novel chance-constrained imitation learning framework, which ensures implicit safety against uncertainty in a principled manner via a combination of stochastic (chance) constraints on resource congestion risk and ensemble value functions. This leads to substantial ($\approx 3-4\times$) improvement in resource efficiency and safety in many oversubscription scenarios, including resource management in cloud services.
Tree DNN: A Deep Container Network
Dec 07, 2022

Multi-Task Learning (MTL) has shown its importance at user products for fast training, data efficiency, reduced overfitting etc. MTL achieves it by sharing the network parameters and training a network for multiple tasks simultaneously. However, MTL does not provide the solution, if each task needs training from a different dataset. In order to solve the stated problem, we have proposed an architecture named TreeDNN along with it's training methodology. TreeDNN helps in training the model with multiple datasets simultaneously, where each branch of the tree may need a different training dataset. We have shown in the results that TreeDNN provides competitive performance with the advantage of reduced ROM requirement for parameter storage and increased responsiveness of the system by loading only specific branch at inference time.
Human-guided Collaborative Problem Solving: A Natural Language based Framework
Jul 19, 2022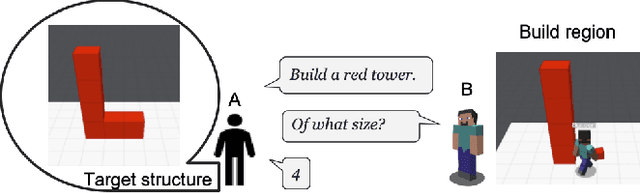
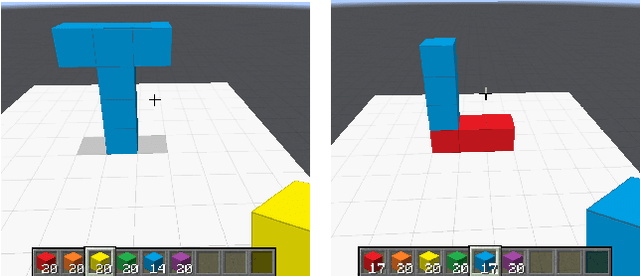
We consider the problem of human-machine collaborative problem solving as a planning task coupled with natural language communication. Our framework consists of three components -- a natural language engine that parses the language utterances to a formal representation and vice-versa, a concept learner that induces generalized concepts for plans based on limited interactions with the user, and an HTN planner that solves the task based on human interaction. We illustrate the ability of this framework to address the key challenges of collaborative problem solving by demonstrating it on a collaborative building task in a Minecraft-based blocksworld domain. The accompanied demo video is available at https://youtu.be/q1pWe4aahF0.
AutoCoMet: Smart Neural Architecture Search via Co-Regulated Shaping Reinforcement
Mar 29, 2022



Designing suitable deep model architectures, for AI-driven on-device apps and features, at par with rapidly evolving mobile hardware and increasingly complex target scenarios is a difficult task. Though Neural Architecture Search (NAS/AutoML) has made this easier by shifting paradigm from extensive manual effort to automated architecture learning from data, yet it has major limitations, leading to critical bottlenecks in the context of mobile devices, including model-hardware fidelity, prohibitive search times and deviation from primary target objective(s). Thus, we propose AutoCoMet that can learn the most suitable DNN architecture optimized for varied types of device hardware and task contexts, ~ 3x faster. Our novel co-regulated shaping reinforcement controller together with the high fidelity hardware meta-behavior predictor produces a smart, fast NAS framework that adapts to context via a generalized formalism for any kind of multi-criteria optimization.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
User Friendly Automatic Construction of Background Knowledge: Mode Construction from ER Diagrams
Dec 16, 2019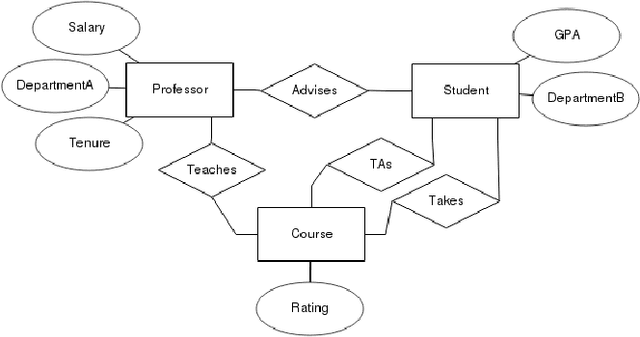

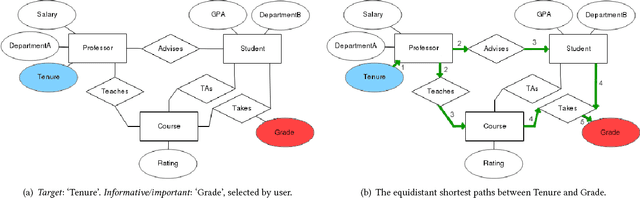
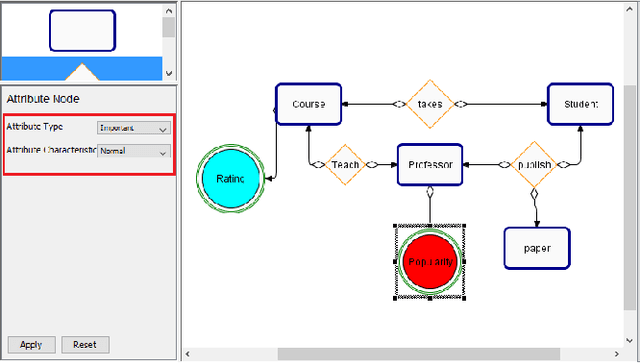
One of the key advantages of Inductive Logic Programming systems is the ability of the domain experts to provide background knowledge as modes that allow for efficient search through the space of hypotheses. However, there is an inherent assumption that this expert should also be an ILP expert to provide effective modes. We relax this assumption by designing a graphical user interface that allows the domain expert to interact with the system using Entity Relationship diagrams. These interactions are used to construct modes for the learning system. We evaluate our algorithm on a probabilistic logic learning system where we demonstrate that the user is able to construct effective background knowledge on par with the expert-encoded knowledge on five data sets.
* 8 pages. Published in Proceedings of the Knowledge Capture Conference, 2017
One-Shot Induction of Generalized Logical Concepts via Human Guidance
Dec 15, 2019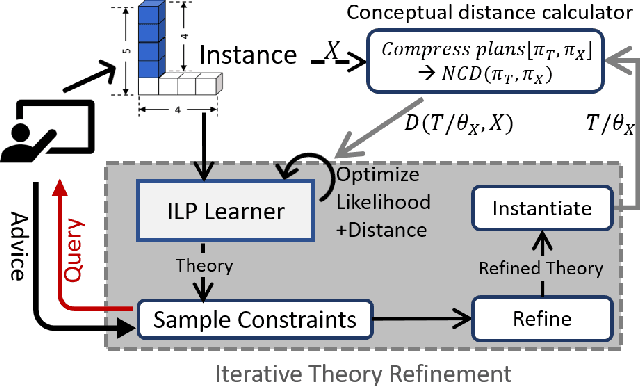

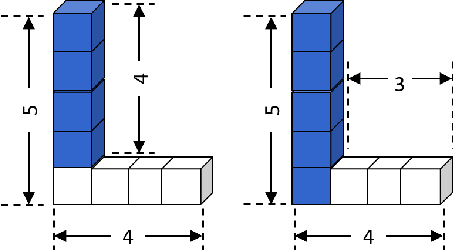
We consider the problem of learning generalized first-order representations of concepts from a single example. To address this challenging problem, we augment an inductive logic programming learner with two novel algorithmic contributions. First, we define a distance measure between candidate concept representations that improves the efficiency of search for target concept and generalization. Second, we leverage richer human inputs in the form of advice to improve the sample-efficiency of learning. We prove that the proposed distance measure is semantically valid and use that to derive a PAC bound. Our experimental analysis on diverse concept learning tasks demonstrates both the effectiveness and efficiency of the proposed approach over a first-order concept learner using only examples.
Knowledge-augmented Column Networks: Guiding Deep Learning with Advice
May 31, 2019
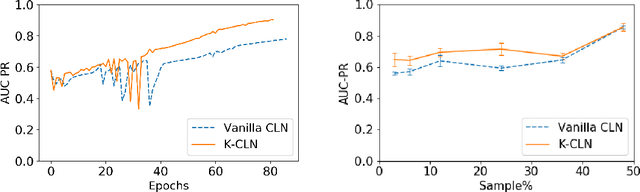
Recently, deep models have had considerable success in several tasks, especially with low-level representations. However, effective learning from sparse noisy samples is a major challenge in most deep models, especially in domains with structured representations. Inspired by the proven success of human guided machine learning, we propose Knowledge-augmented Column Networks, a relational deep learning framework that leverages human advice/knowledge to learn better models in presence of sparsity and systematic noise.
Human-Guided Learning of Column Networks: Augmenting Deep Learning with Advice
Apr 15, 2019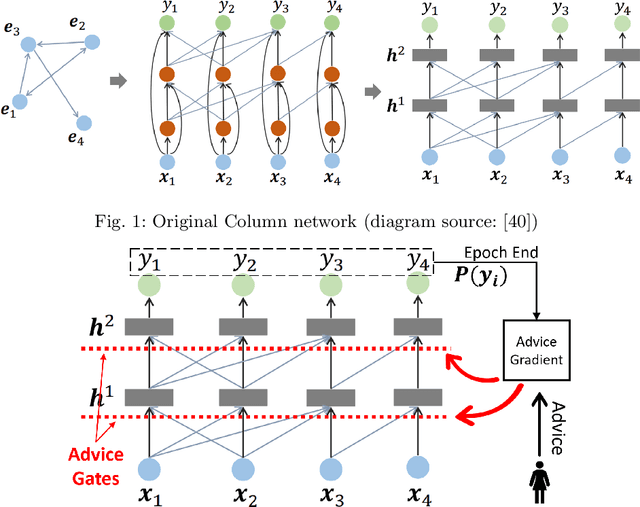

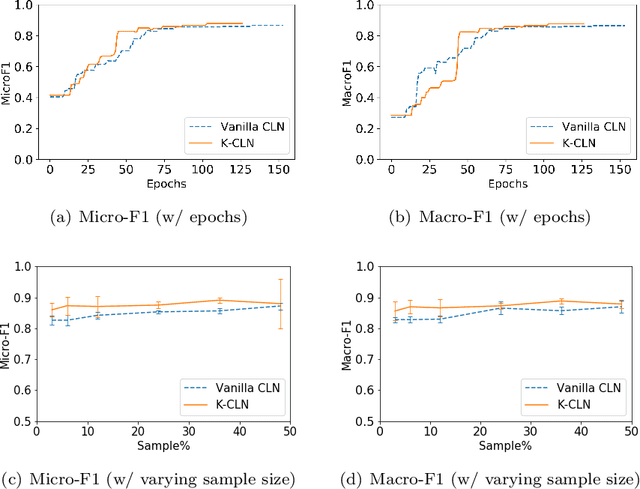
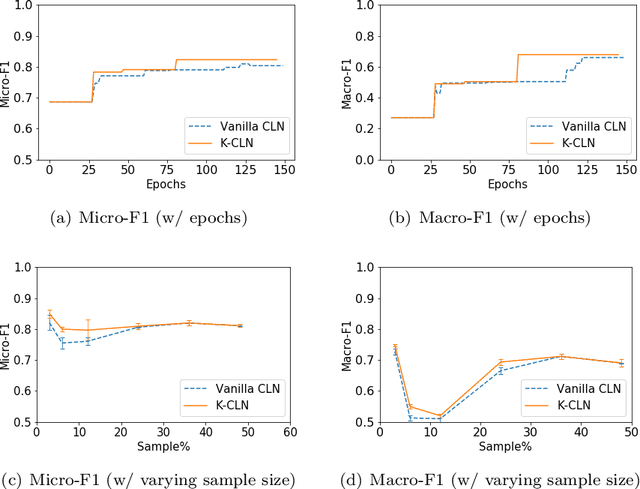
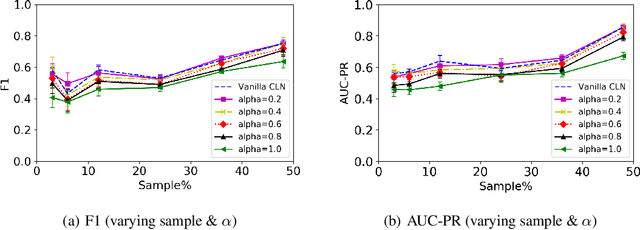
Recently, deep models have been successfully applied in several applications, especially with low-level representations. However, sparse, noisy samples and structured domains (with multiple objects and interactions) are some of the open challenges in most deep models. Column Networks, a deep architecture, can succinctly capture such domain structure and interactions, but may still be prone to sub-optimal learning from sparse and noisy samples. Inspired by the success of human-advice guided learning in AI, especially in data-scarce domains, we propose Knowledge-augmented Column Networks that leverage human advice/knowledge for better learning with noisy/sparse samples. Our experiments demonstrate that our approach leads to either superior overall performance or faster convergence (i.e., both effective and efficient).