 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreetwise Agents: Empowering Offline RL Policies to Outsmart Exogenous Stochastic Disturbances in RTC
Nov 11, 2024



The difficulty of exploring and training online on real production systems limits the scope of real-time online data/feedback-driven decision making. The most feasible approach is to adopt offline reinforcement learning from limited trajectory samples. However, after deployment, such policies fail due to exogenous factors that temporarily or permanently disturb/alter the transition distribution of the assumed decision process structure induced by offline samples. This results in critical policy failures and generalization errors in sensitive domains like Real-Time Communication (RTC). We solve this crucial problem of identifying robust actions in presence of domain shifts due to unseen exogenous stochastic factors in the wild. As it is impossible to learn generalized offline policies within the support of offline data that are robust to these unseen exogenous disturbances, we propose a novel post-deployment shaping of policies (Streetwise), conditioned on real-time characterization of out-of-distribution sub-spaces. This leads to robust actions in bandwidth estimation (BWE) of network bottlenecks in RTC and in standard benchmarks. Our extensive experimental results on BWE and other standard offline RL benchmark environments demonstrate a significant improvement ($\approx$ 18% on some scenarios) in final returns wrt. end-user metrics over state-of-the-art baselines.
VCD: A Video Conferencing Dataset for Video Compression
Sep 14, 2023



Commonly used datasets for evaluating video codecs are all very high quality and not representative of video typically used in video conferencing scenarios. We present the Video Conferencing Dataset (VCD) for evaluating video codecs for real-time communication, the first such dataset focused on video conferencing. VCD includes a wide variety of camera qualities and spatial and temporal information. It includes both desktop and mobile scenarios and two types of video background processing. We report the compression efficiency of H.264, H.265, H.266, and AV1 in low-delay settings on VCD and compare it with the non-video conferencing datasets UVC, MLC-JVC, and HEVC. The results show the source quality and the scenarios have a significant effect on the compression efficiency of all the codecs. VCD enables the evaluation and tuning of codecs for this important scenario. The VCD is publicly available as an open-source dataset at https://github.com/microsoft/VCD.
Full Reference Video Quality Assessment for Machine Learning-Based Video Codecs
Sep 02, 2023



Machine learning-based video codecs have made significant progress in the past few years. A critical area in the development of ML-based video codecs is an accurate evaluation metric that does not require an expensive and slow subjective test. We show that existing evaluation metrics that were designed and trained on DSP-based video codecs are not highly correlated to subjective opinion when used with ML video codecs due to the video artifacts being quite different between ML and video codecs. We provide a new dataset of ML video codec videos that have been accurately labeled for quality. We also propose a new full reference video quality assessment (FRVQA) model that achieves a Pearson Correlation Coefficient (PCC) of 0.99 and a Spearman's Rank Correlation Coefficient (SRCC) of 0.99 at the model level. We make the dataset and FRVQA model open source to help accelerate research in ML video codecs, and so that others can further improve the FRVQA model.
Improving Meeting Inclusiveness using Speech Interruption Analysis
Apr 05, 2023

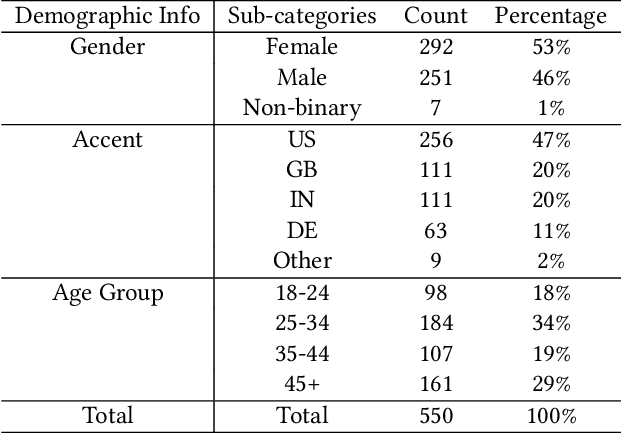
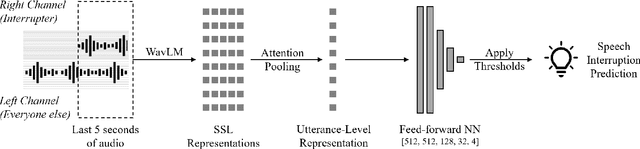
Meetings are a pervasive method of communication within all types of companies and organizations, and using remote collaboration systems to conduct meetings has increased dramatically since the COVID-19 pandemic. However, not all meetings are inclusive, especially in terms of the participation rates among attendees. In a recent large-scale survey conducted at Microsoft, the top suggestion given by meeting participants for improving inclusiveness is to improve the ability of remote participants to interrupt and acquire the floor during meetings. We show that the use of the virtual raise hand (VRH) feature can lead to an increase in predicted meeting inclusiveness at Microsoft. One challenge is that VRH is used in less than 1% of all meetings. In order to drive adoption of its usage to improve inclusiveness (and participation), we present a machine learning-based system that predicts when a meeting participant attempts to obtain the floor, but fails to interrupt (termed a `failed interruption'). This prediction can be used to nudge the user to raise their virtual hand within the meeting. We believe this is the first failed speech interruption detector, and the performance on a realistic test set has an area under curve (AUC) of 0.95 with a true positive rate (TPR) of 50% at a false positive rate (FPR) of <1%. To our knowledge, this is also the first dataset of interruption categories (including the failed interruption category) for remote meetings. Finally, we believe this is the first such system designed to improve meeting inclusiveness through speech interruption analysis and active intervention.
Reinforcement learning for bandwidth estimation and congestion control in real-time communications
Dec 04, 2019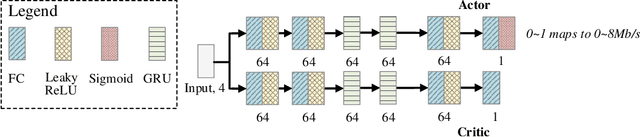

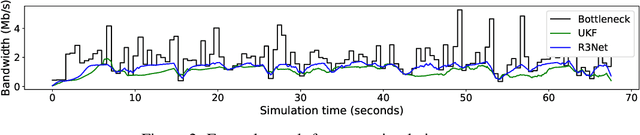

Bandwidth estimation and congestion control for real-time communications (i.e., audio and video conferencing) remains a difficult problem, despite many years of research. Achieving high quality of experience (QoE) for end users requires continual updates due to changing network architectures and technologies. In this paper, we apply reinforcement learning for the first time to the problem of real-time communications (RTC), where we seek to optimize user-perceived quality. We present initial proof-of-concept results, where we learn an agent to control sending rate in an RTC system, evaluating using both network simulation and real Internet video calls. We discuss the challenges we observed, particularly in designing realistic reward functions that reflect QoE, and in bridging the gap between the training environment and real-world networks.
On Design of Problem Token Questions in Quality of Experience Surveys
Aug 19, 2018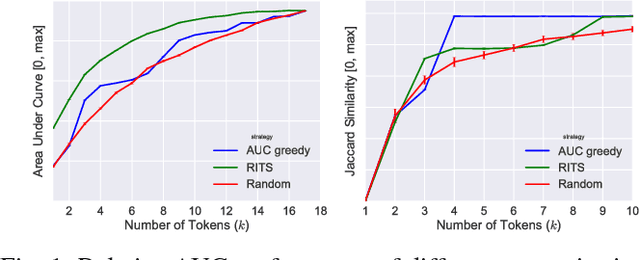
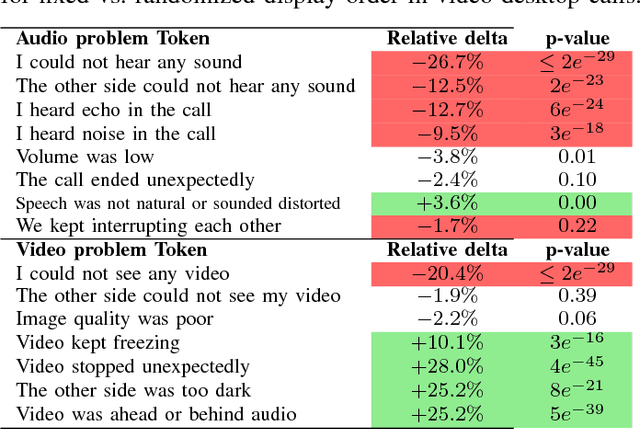
User surveys for Quality of Experience (QoE) are a critical source of information. In addition to the common "star rating" used to estimate Mean Opinion Score (MOS), more detailed survey questions (problem tokens) about specific areas provide valuable insight into the factors impacting QoE. This paper explores two aspects of the problem token questionnaire design. First, we study the bias introduced by fixed question order, and second, we study the challenge of selecting a subset of questions to keep the token set small. Based on 900,000 calls gathered using a randomized controlled experiment from a live system, we find that the order bias can be significantly reduced by randomizing the display order of tokens. The difference in response rate varies based on token position and display design. It is worth noting that the users respond to the randomized-order variant at levels that are comparable to the fixed-order variant. The effective selection of a subset of token questions is achieved by extracting tokens that provide the highest information gain over user ratings. This selection is known to be in the class of NP-hard problems. We apply a well-known greedy submodular maximization method on our dataset to capture 94% of the information using just 30% of the questions.