 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning for bandwidth estimation and congestion control in real-time communications
Dec 04, 2019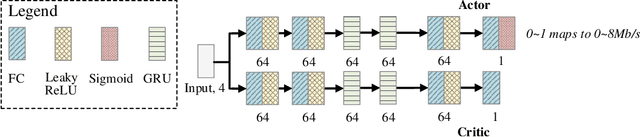

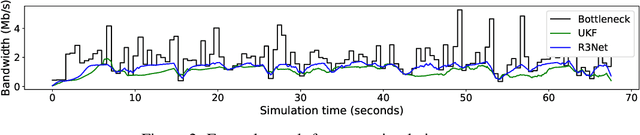

Bandwidth estimation and congestion control for real-time communications (i.e., audio and video conferencing) remains a difficult problem, despite many years of research. Achieving high quality of experience (QoE) for end users requires continual updates due to changing network architectures and technologies. In this paper, we apply reinforcement learning for the first time to the problem of real-time communications (RTC), where we seek to optimize user-perceived quality. We present initial proof-of-concept results, where we learn an agent to control sending rate in an RTC system, evaluating using both network simulation and real Internet video calls. We discuss the challenges we observed, particularly in designing realistic reward functions that reflect QoE, and in bridging the gap between the training environment and real-world networks.
On Design of Problem Token Questions in Quality of Experience Surveys
Aug 19, 2018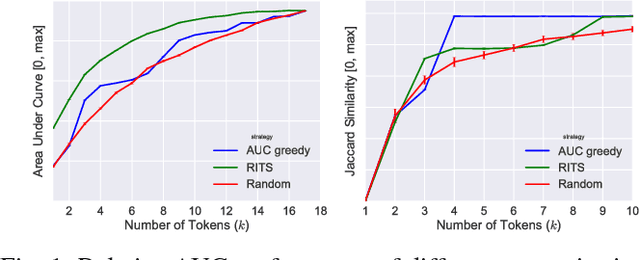
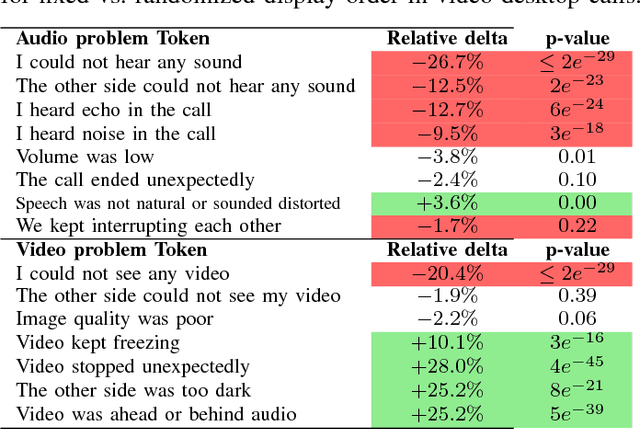
User surveys for Quality of Experience (QoE) are a critical source of information. In addition to the common "star rating" used to estimate Mean Opinion Score (MOS), more detailed survey questions (problem tokens) about specific areas provide valuable insight into the factors impacting QoE. This paper explores two aspects of the problem token questionnaire design. First, we study the bias introduced by fixed question order, and second, we study the challenge of selecting a subset of questions to keep the token set small. Based on 900,000 calls gathered using a randomized controlled experiment from a live system, we find that the order bias can be significantly reduced by randomizing the display order of tokens. The difference in response rate varies based on token position and display design. It is worth noting that the users respond to the randomized-order variant at levels that are comparable to the fixed-order variant. The effective selection of a subset of token questions is achieved by extracting tokens that provide the highest information gain over user ratings. This selection is known to be in the class of NP-hard problems. We apply a well-known greedy submodular maximization method on our dataset to capture 94% of the information using just 30% of the questions.