 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Meeting Inclusiveness using Speech Interruption Analysis
Apr 05, 2023

Meetings are a pervasive method of communication within all types of companies and organizations, and using remote collaboration systems to conduct meetings has increased dramatically since the COVID-19 pandemic. However, not all meetings are inclusive, especially in terms of the participation rates among attendees. In a recent large-scale survey conducted at Microsoft, the top suggestion given by meeting participants for improving inclusiveness is to improve the ability of remote participants to interrupt and acquire the floor during meetings. We show that the use of the virtual raise hand (VRH) feature can lead to an increase in predicted meeting inclusiveness at Microsoft. One challenge is that VRH is used in less than 1% of all meetings. In order to drive adoption of its usage to improve inclusiveness (and participation), we present a machine learning-based system that predicts when a meeting participant attempts to obtain the floor, but fails to interrupt (termed a `failed interruption'). This prediction can be used to nudge the user to raise their virtual hand within the meeting. We believe this is the first failed speech interruption detector, and the performance on a realistic test set has an area under curve (AUC) of 0.95 with a true positive rate (TPR) of 50% at a false positive rate (FPR) of <1%. To our knowledge, this is also the first dataset of interruption categories (including the failed interruption category) for remote meetings. Finally, we believe this is the first such system designed to improve meeting inclusiveness through speech interruption analysis and active intervention.
Real-time Speech Interruption Analysis: From Cloud to Client Deployment
Oct 24, 2022



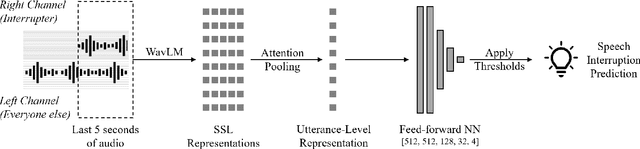
Meetings are an essential form of communication for all types of organizations, and remote collaboration systems have been much more widely used since the COVID-19 pandemic. One major issue with remote meetings is that it is challenging for remote participants to interrupt and speak. We have recently developed the first speech interruption analysis model, which detects failed speech interruptions, shows very promising performance, and is being deployed in the cloud. To deliver this feature in a more cost-efficient and environment-friendly way, we reduced the model complexity and size to ship the WavLM_SI model in client devices. In this paper, we first describe how we successfully improved the True Positive Rate (TPR) at a 1% False Positive Rate (FPR) from 50.9% to 68.3% for the failed speech interruption detection model by training on a larger dataset and fine-tuning. We then shrank the model size from 222.7 MB to 9.3 MB with an acceptable loss in accuracy and reduced the complexity from 31.2 GMACS (Giga Multiply-Accumulate Operations per Second) to 4.3 GMACS. We also estimated the environmental impact of the complexity reduction, which can be used as a general guideline for large Transformer-based models, and thus make those models more accessible with less computation overhead.
Aura: Privacy-preserving augmentation to improve test set diversity in noise suppression applications
Oct 08, 2021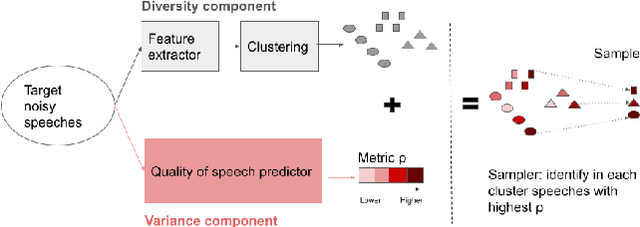
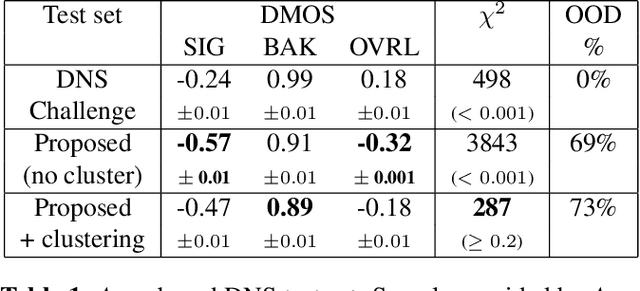
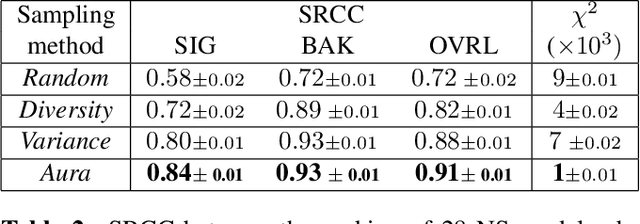
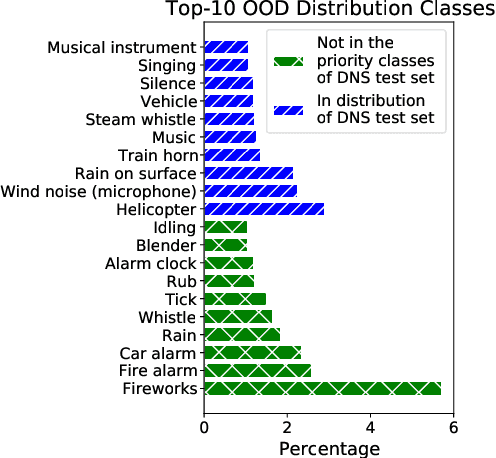
Noise suppression models running in production environments are commonly trained on publicly available datasets. However, this approach leads to regressions in production environments due to the lack of training/testing on representative customer data. Moreover, due to privacy reasons, developers cannot listen to customer content. This `ears-off' situation motivates augmenting existing datasets in a privacy-preserving manner. In this paper, we present Aura, a solution to make existing noise suppression test sets more challenging and diverse while limiting the sampling budget. Aura is `ears-off' because it relies on a feature extractor and a metric of speech quality, DNSMOS P.835, both pre-trained on data obtained from public sources. As an application of \aura, we augment a current benchmark test set in noise suppression by sampling audio files from a new batch of data of 20K clean speech clips from Librivox mixed with noise clips obtained from AudioSet. Aura makes the existing benchmark test set harder by 100% in DNSMOS P.835, a 26 improvement in Spearman's rank correlation coefficient (SRCC) compared to random sampling and, identifies 73% out-of-distribution samples to augment the test set.
Resonance: Replacing Software Constants with Context-Aware Models in Real-time Communication
Nov 23, 2020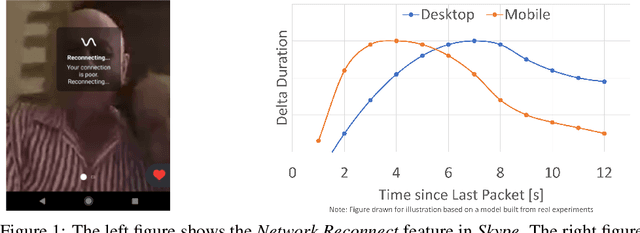


Large software systems tune hundreds of 'constants' to optimize their runtime performance. These values are commonly derived through intuition, lab tests, or A/B tests. A 'one-size-fits-all' approach is often sub-optimal as the best value depends on runtime context. In this paper, we provide an experimental approach to replace constants with learned contextual functions for Skype - a widely used real-time communication (RTC) application. We present Resonance, a system based on contextual bandits (CB). We describe experiences from three real-world experiments: applying it to the audio, video, and transport components in Skype. We surface a unique and practical challenge of performing machine learning (ML) inference in large software systems written using encapsulation principles. Finally, we open-source FeatureBroker, a library to reduce the friction in adopting ML models in such development environments
Lumos: A Library for Diagnosing Metric Regressions in Web-Scale Applications
Jun 23, 2020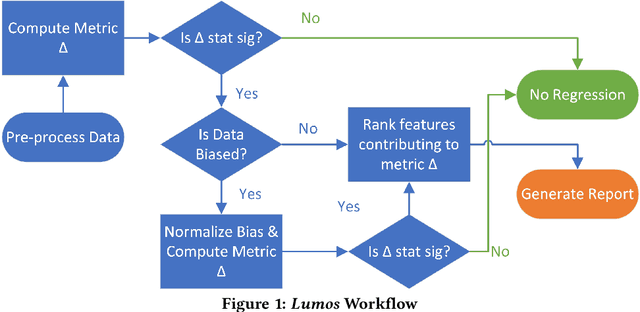
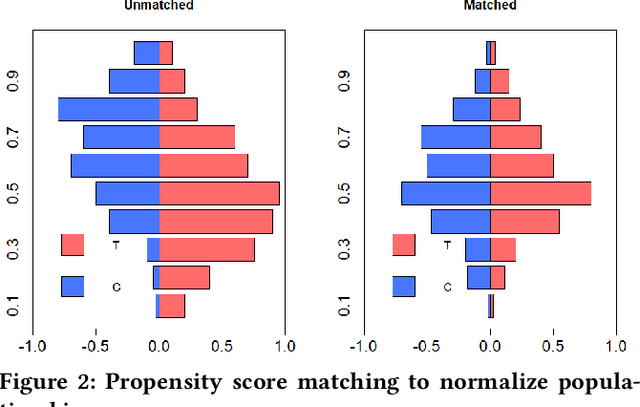
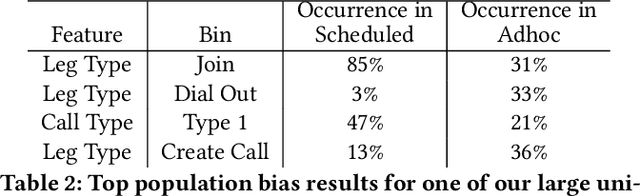
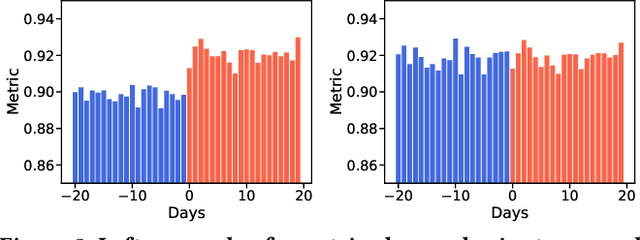
Web-scale applications can ship code on a daily to weekly cadence. These applications rely on online metrics to monitor the health of new releases. Regressions in metric values need to be detected and diagnosed as early as possible to reduce the disruption to users and product owners. Regressions in metrics can surface due to a variety of reasons: genuine product regressions, changes in user population, and bias due to telemetry loss (or processing) are among the common causes. Diagnosing the cause of these metric regressions is costly for engineering teams as they need to invest time in finding the root cause of the issue as soon as possible. We present Lumos, a Python library built using the principles of AB testing to systematically diagnose metric regressions to automate such analysis. Lumos has been deployed across the component teams in Microsoft's Real-Time Communication applications Skype and Microsoft Teams. It has enabled engineering teams to detect 100s of real changes in metrics and reject 1000s of false alarms detected by anomaly detectors. The application of Lumos has resulted in freeing up as much as 95% of the time allocated to metric-based investigations. In this work, we open source Lumos and present our results from applying it to two different components within the RTC group over millions of sessions. This general library can be coupled with any production system to manage the volume of alerting efficiently.
A Dataset for measuring reading levels in India at scale
Nov 27, 2019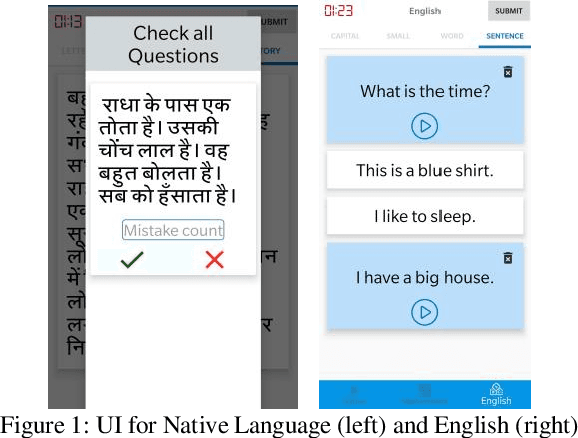
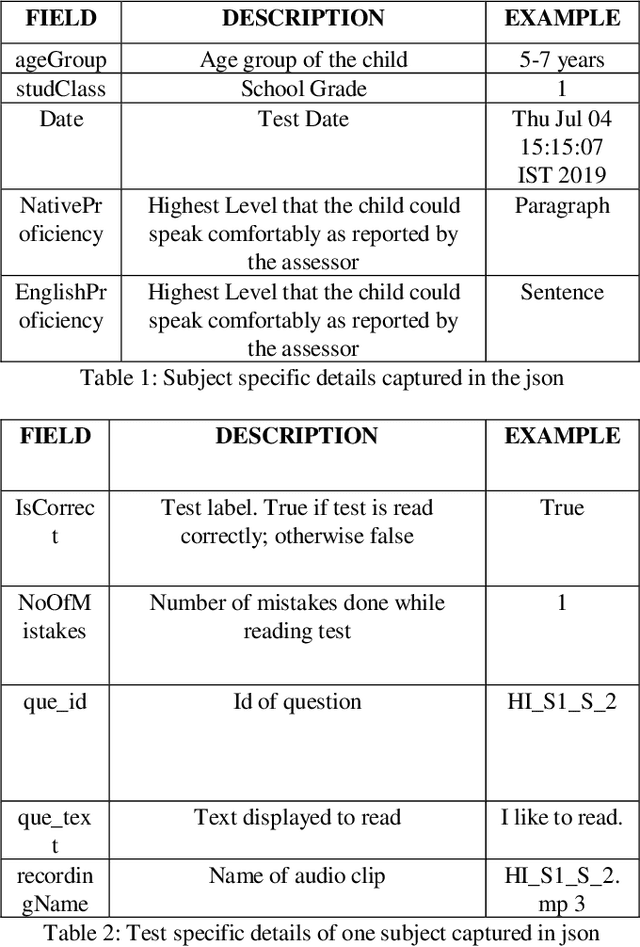
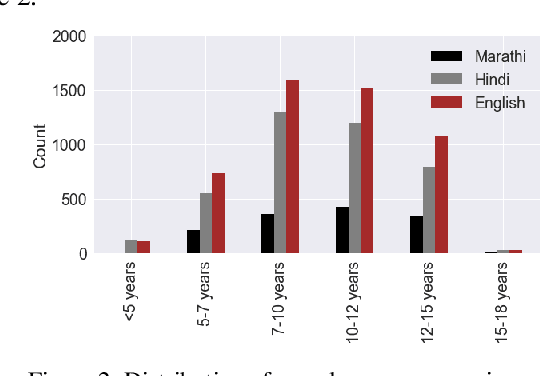
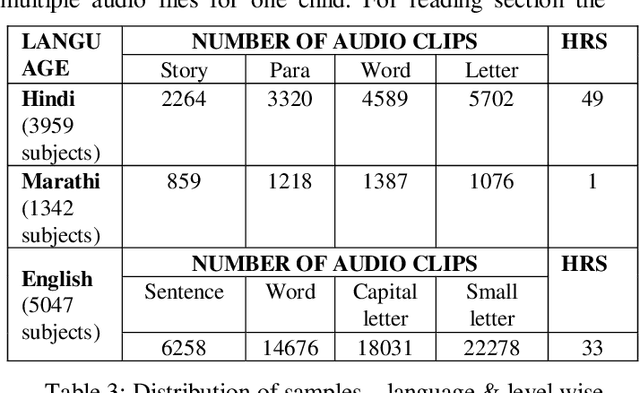
One out of four children in India are leaving grade eight without basic reading skills. Measuring the reading levels in a vast country like India poses significant hurdles. Recent advances in machine learning opens up the possibility of automating this task. However, the datasets are primarily in English. To solve this assessment problem and advance deep learning research in regional Indian languages, we present the ASER dataset of children in the age group of 6-14. The dataset consists of 5,300 subjects generating 81,658 labeled audio clips in Hindi, Marathi and English. These labels represent expert opinions on the ability of the child to read at a specified level. Using this dataset, we built a simple ASR-based classifier. Early results indicate that we can achieve a prediction accuracy of 86 percent for the English language. Considering the ASER survey spans half a million subjects, this dataset can grow to those scales.
On Design of Problem Token Questions in Quality of Experience Surveys
Aug 19, 2018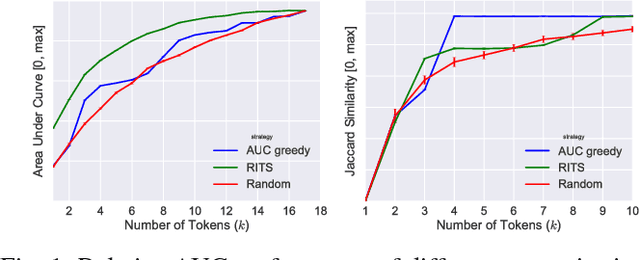
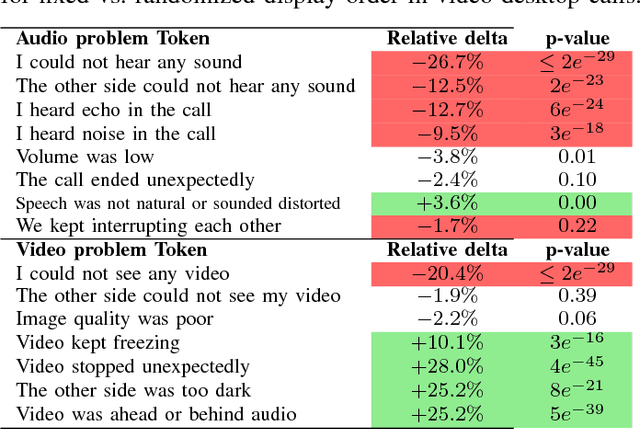
User surveys for Quality of Experience (QoE) are a critical source of information. In addition to the common "star rating" used to estimate Mean Opinion Score (MOS), more detailed survey questions (problem tokens) about specific areas provide valuable insight into the factors impacting QoE. This paper explores two aspects of the problem token questionnaire design. First, we study the bias introduced by fixed question order, and second, we study the challenge of selecting a subset of questions to keep the token set small. Based on 900,000 calls gathered using a randomized controlled experiment from a live system, we find that the order bias can be significantly reduced by randomizing the display order of tokens. The difference in response rate varies based on token position and display design. It is worth noting that the users respond to the randomized-order variant at levels that are comparable to the fixed-order variant. The effective selection of a subset of token questions is achieved by extracting tokens that provide the highest information gain over user ratings. This selection is known to be in the class of NP-hard problems. We apply a well-known greedy submodular maximization method on our dataset to capture 94% of the information using just 30% of the questions.
Model-Based Event Detection in Wireless Sensor Networks
Jan 25, 2009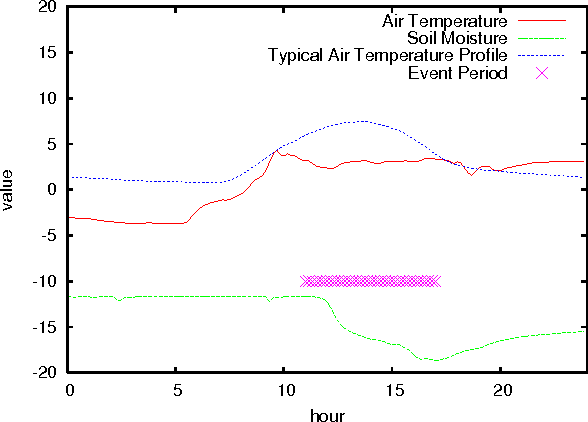
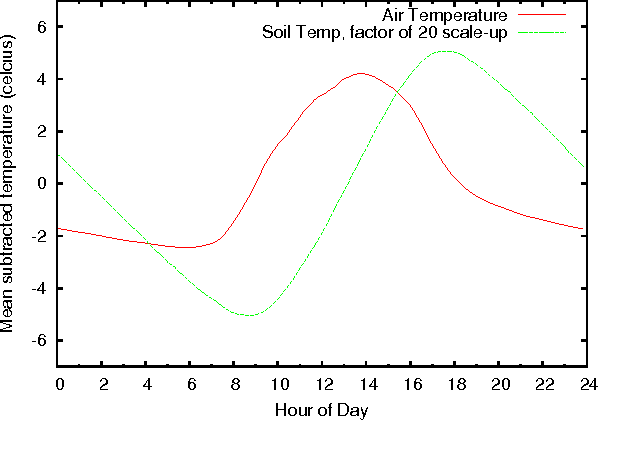

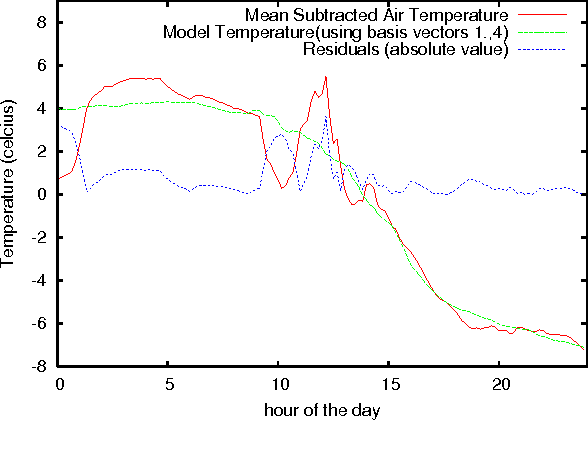
In this paper we present an application of techniques from statistical signal processing to the problem of event detection in wireless sensor networks used for environmental monitoring. The proposed approach uses the well-established Principal Component Analysis (PCA) technique to build a compact model of the observed phenomena that is able to capture daily and seasonal trends in the collected measurements. We then use the divergence between actual measurements and model predictions to detect the existence of discrete events within the collected data streams. Our preliminary results show that this event detection mechanism is sensitive enough to detect the onset of rain events using the temperature modality of a wireless sensor network.