 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAura: Privacy-preserving augmentation to improve test set diversity in noise suppression applications
Oct 08, 2021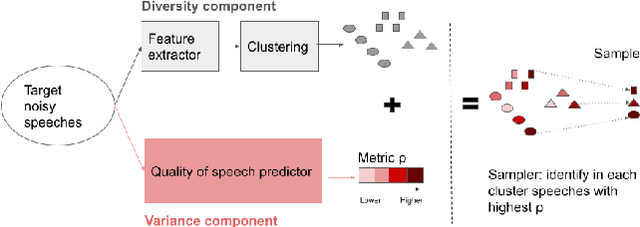
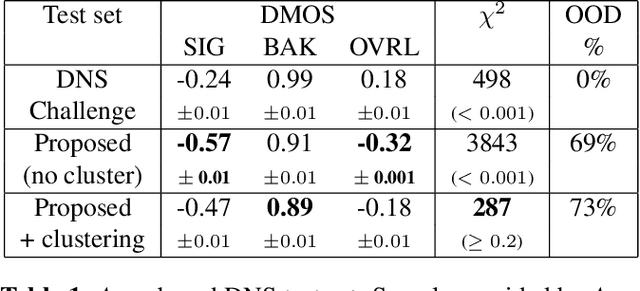
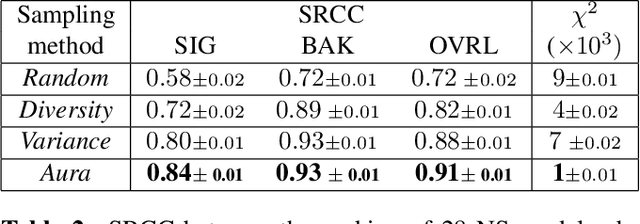
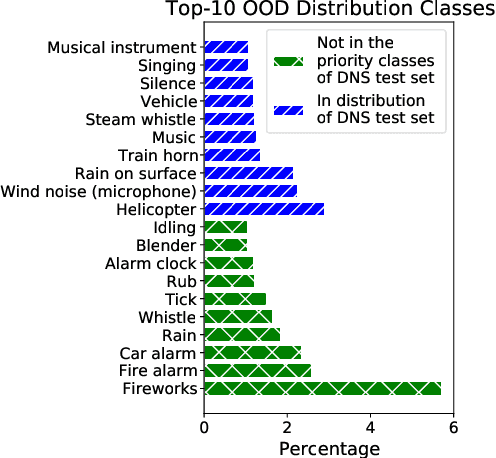
Noise suppression models running in production environments are commonly trained on publicly available datasets. However, this approach leads to regressions in production environments due to the lack of training/testing on representative customer data. Moreover, due to privacy reasons, developers cannot listen to customer content. This `ears-off' situation motivates augmenting existing datasets in a privacy-preserving manner. In this paper, we present Aura, a solution to make existing noise suppression test sets more challenging and diverse while limiting the sampling budget. Aura is `ears-off' because it relies on a feature extractor and a metric of speech quality, DNSMOS P.835, both pre-trained on data obtained from public sources. As an application of \aura, we augment a current benchmark test set in noise suppression by sampling audio files from a new batch of data of 20K clean speech clips from Librivox mixed with noise clips obtained from AudioSet. Aura makes the existing benchmark test set harder by 100% in DNSMOS P.835, a 26 improvement in Spearman's rank correlation coefficient (SRCC) compared to random sampling and, identifies 73% out-of-distribution samples to augment the test set.
Program Language Translation Using a Grammar-Driven Tree-to-Tree Model
Jul 04, 2018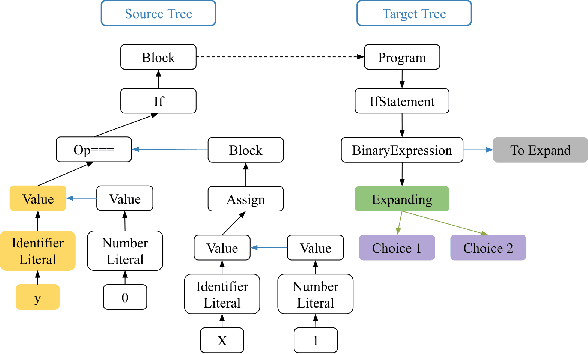

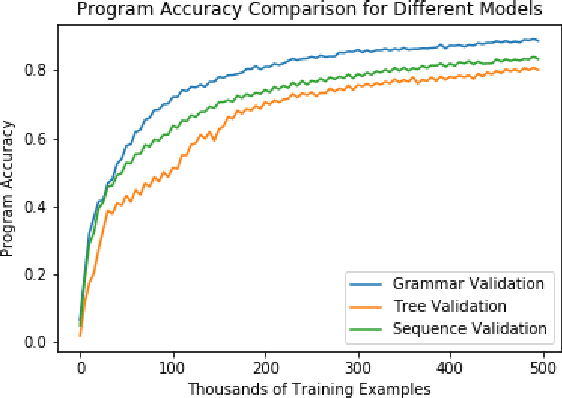
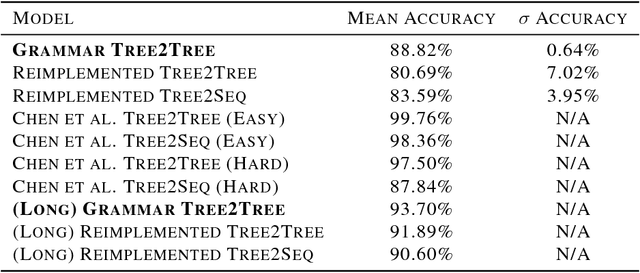
The task of translating between programming languages differs from the challenge of translating natural languages in that programming languages are designed with a far more rigid set of structural and grammatical rules. Previous work has used a tree-to-tree encoder/decoder model to take advantage of the inherent tree structure of programs during translation. Neural decoders, however, by default do not exploit known grammar rules of the target language. In this paper, we describe a tree decoder that leverages knowledge of a language's grammar rules to exclusively generate syntactically correct programs. We find that this grammar-based tree-to-tree model outperforms the state of the art tree-to-tree model in translating between two programming languages on a previously used synthetic task.