 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarvey Mudd College at SemEval-2019 Task 4: The Clint Buchanan Hyperpartisan News Detector
Apr 10, 2019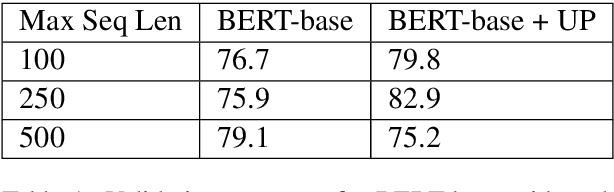

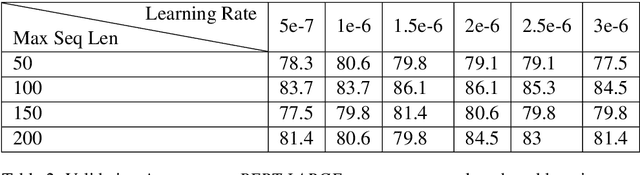
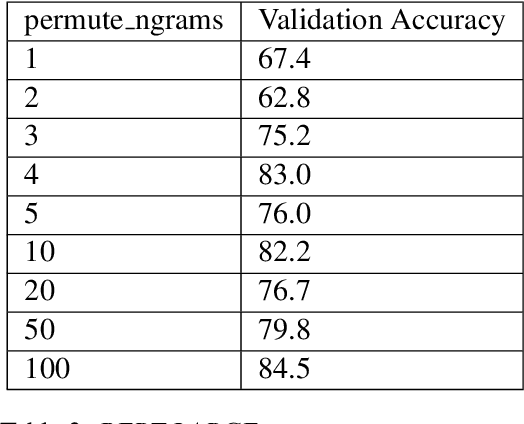
We investigate the recently developed Bidirectional Encoder Representations from Transformers (BERT) model for the hyperpartisan news detection task. Using a subset of hand-labeled articles from SemEval as a validation set, we test the performance of different parameters for BERT models. We find that accuracy from two different BERT models using different proportions of the articles is consistently high, with our best-performing model on the validation set achieving 85% accuracy and the best-performing model on the test set achieving 77%. We further determined that our model exhibits strong consistency, labeling independent slices of the same article identically. Finally, we find that randomizing the order of word pieces dramatically reduces validation accuracy (to approximately 60%), but that shuffling groups of four or more word pieces maintains an accuracy of about 80%, indicating the model mainly gains value from local context.
Hierarchical Text Generation using an Outline
Oct 20, 2018


Many challenges in natural language processing require generating text, including language translation, dialogue generation, and speech recognition. For all of these problems, text generation becomes more difficult as the text becomes longer. Current language models often struggle to keep track of coherence for long pieces of text. Here, we attempt to have the model construct and use an outline of the text it generates to keep it focused. We find that the usage of an outline improves perplexity. We do not find that using the outline improves human evaluation over a simpler baseline, revealing a discrepancy in perplexity and human perception. Similarly, hierarchical generation is not found to improve human evaluation scores.
Program Language Translation Using a Grammar-Driven Tree-to-Tree Model
Jul 04, 2018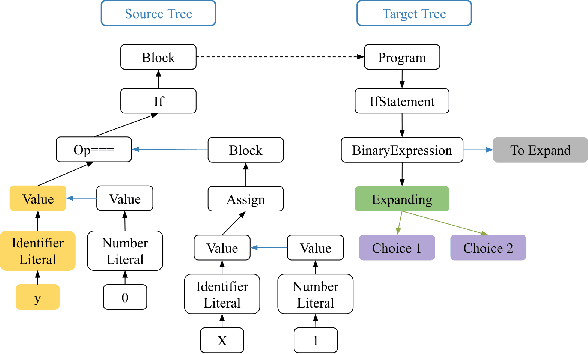

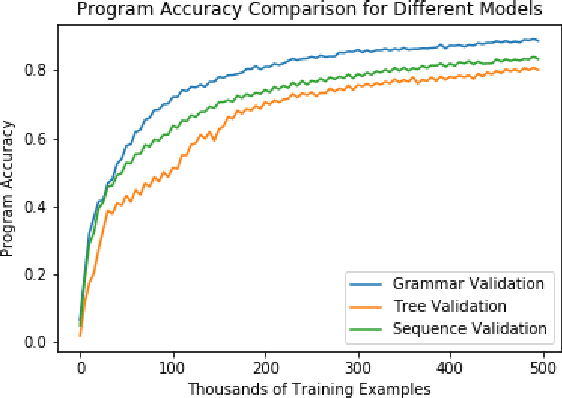
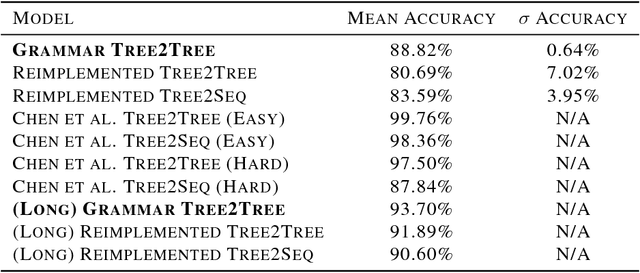
The task of translating between programming languages differs from the challenge of translating natural languages in that programming languages are designed with a far more rigid set of structural and grammatical rules. Previous work has used a tree-to-tree encoder/decoder model to take advantage of the inherent tree structure of programs during translation. Neural decoders, however, by default do not exploit known grammar rules of the target language. In this paper, we describe a tree decoder that leverages knowledge of a language's grammar rules to exclusively generate syntactically correct programs. We find that this grammar-based tree-to-tree model outperforms the state of the art tree-to-tree model in translating between two programming languages on a previously used synthetic task.