 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarvey Mudd College at SemEval-2019 Task 4: The Clint Buchanan Hyperpartisan News Detector
Apr 10, 2019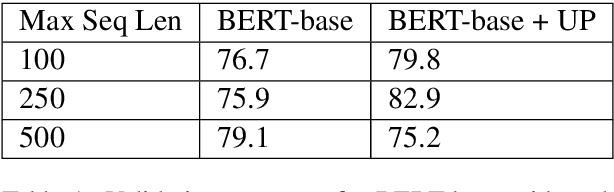

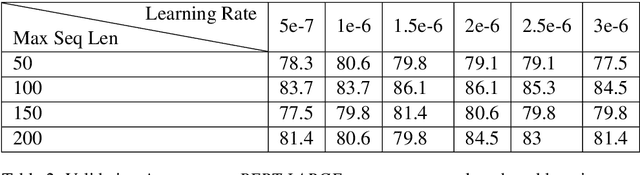
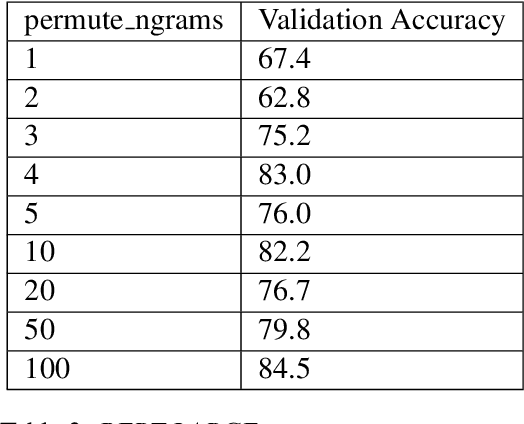
We investigate the recently developed Bidirectional Encoder Representations from Transformers (BERT) model for the hyperpartisan news detection task. Using a subset of hand-labeled articles from SemEval as a validation set, we test the performance of different parameters for BERT models. We find that accuracy from two different BERT models using different proportions of the articles is consistently high, with our best-performing model on the validation set achieving 85% accuracy and the best-performing model on the test set achieving 77%. We further determined that our model exhibits strong consistency, labeling independent slices of the same article identically. Finally, we find that randomizing the order of word pieces dramatically reduces validation accuracy (to approximately 60%), but that shuffling groups of four or more word pieces maintains an accuracy of about 80%, indicating the model mainly gains value from local context.
Generating Memorable Mnemonic Encodings of Numbers
May 07, 2017


The major system is a mnemonic system that can be used to memorize sequences of numbers. In this work, we present a method to automatically generate sentences that encode a given number. We propose several encoding models and compare the most promising ones in a password memorability study. The results of the study show that a model combining part-of-speech sentence templates with an $n$-gram language model produces the most memorable password representations.