 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEx-Ante Assessment of Discrimination in Dataset
Aug 18, 2022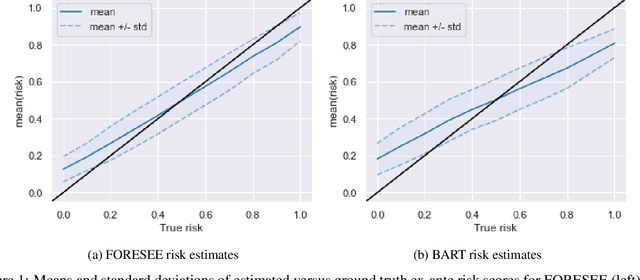
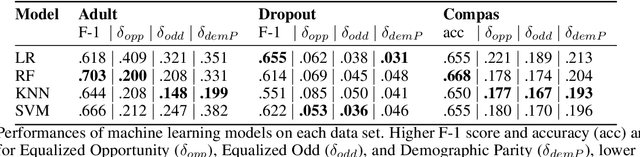
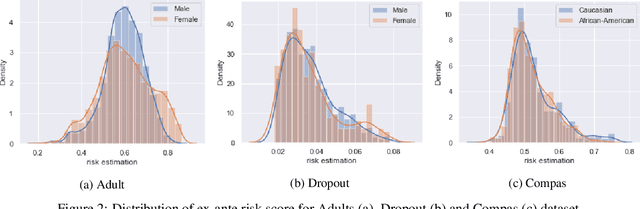
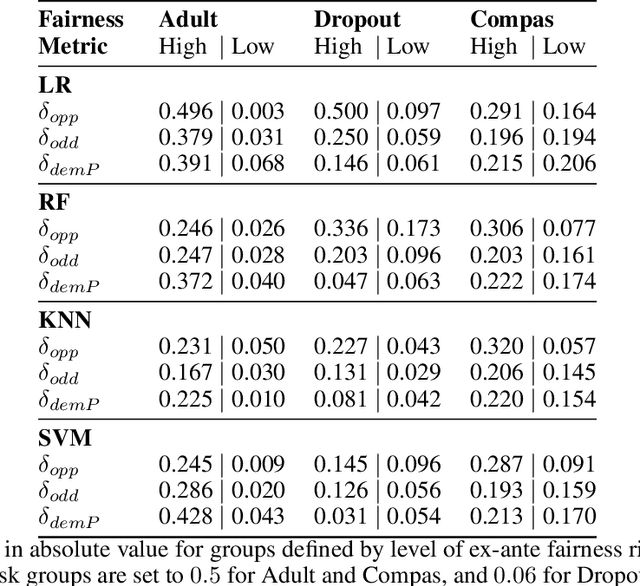
Data owners face increasing liability for how the use of their data could harm under-priviliged communities. Stakeholders would like to identify the characteristics of data that lead to algorithms being biased against any particular demographic groups, for example, defined by their race, gender, age, and/or religion. Specifically, we are interested in identifying subsets of the feature space where the ground truth response function from features to observed outcomes differs across demographic groups. To this end, we propose FORESEE, a FORESt of decision trEEs algorithm, which generates a score that captures how likely an individual's response varies with sensitive attributes. Empirically, we find that our approach allows us to identify the individuals who are most likely to be misclassified by several classifiers, including Random Forest, Logistic Regression, Support Vector Machine, and k-Nearest Neighbors. The advantage of our approach is that it allows stakeholders to characterize risky samples that may contribute to discrimination, as well as, use the FORESEE to estimate the risk of upcoming samples.
SoFaiR: Single Shot Fair Representation Learning
Apr 26, 2022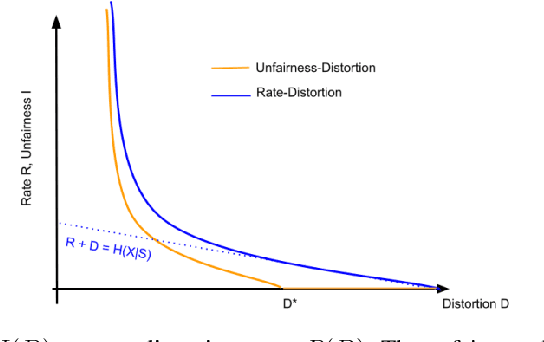
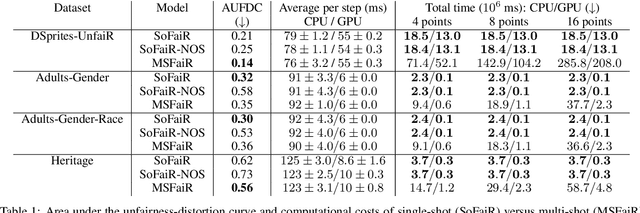
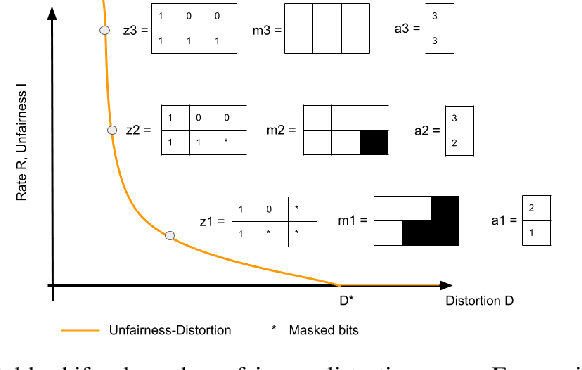

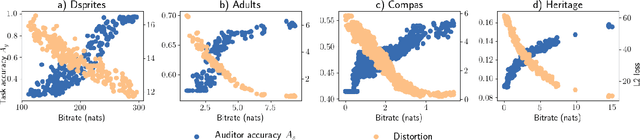
To avoid discriminatory uses of their data, organizations can learn to map them into a representation that filters out information related to sensitive attributes. However, all existing methods in fair representation learning generate a fairness-information trade-off. To achieve different points on the fairness-information plane, one must train different models. In this paper, we first demonstrate that fairness-information trade-offs are fully characterized by rate-distortion trade-offs. Then, we use this key result and propose SoFaiR, a single shot fair representation learning method that generates with one trained model many points on the fairness-information plane. Besides its computational saving, our single-shot approach is, to the extent of our knowledge, the first fair representation learning method that explains what information is affected by changes in the fairness / distortion properties of the representation. Empirically, we find on three datasets that SoFaiR achieves similar fairness-information trade-offs as its multi-shot counterparts.
Aura: Privacy-preserving augmentation to improve test set diversity in noise suppression applications
Oct 08, 2021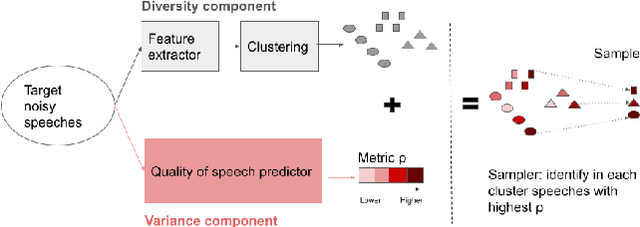
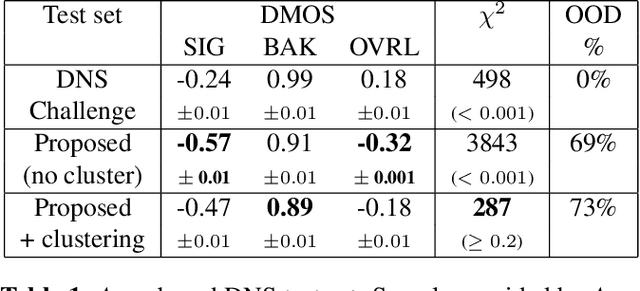
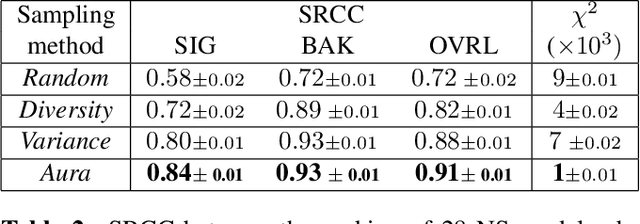
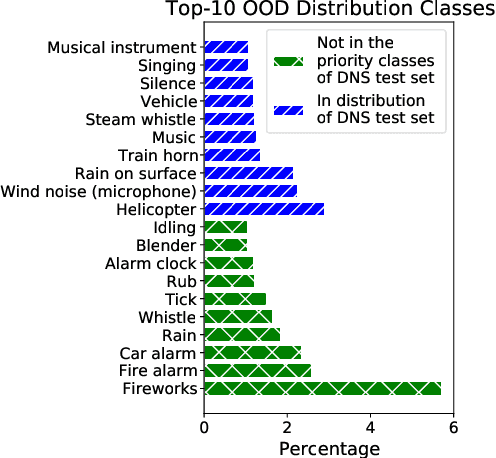
Noise suppression models running in production environments are commonly trained on publicly available datasets. However, this approach leads to regressions in production environments due to the lack of training/testing on representative customer data. Moreover, due to privacy reasons, developers cannot listen to customer content. This `ears-off' situation motivates augmenting existing datasets in a privacy-preserving manner. In this paper, we present Aura, a solution to make existing noise suppression test sets more challenging and diverse while limiting the sampling budget. Aura is `ears-off' because it relies on a feature extractor and a metric of speech quality, DNSMOS P.835, both pre-trained on data obtained from public sources. As an application of \aura, we augment a current benchmark test set in noise suppression by sampling audio files from a new batch of data of 20K clean speech clips from Librivox mixed with noise clips obtained from AudioSet. Aura makes the existing benchmark test set harder by 100% in DNSMOS P.835, a 26 improvement in Spearman's rank correlation coefficient (SRCC) compared to random sampling and, identifies 73% out-of-distribution samples to augment the test set.
Fair Representations by Compression
May 28, 2021

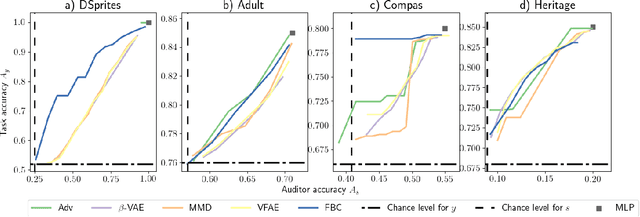
Organizations that collect and sell data face increasing scrutiny for the discriminatory use of data. We propose a novel unsupervised approach to transform data into a compressed binary representation independent of sensitive attributes. We show that in an information bottleneck framework, a parsimonious representation should filter out information related to sensitive attributes if they are provided directly to the decoder. Empirical results show that the proposed method, \textbf{FBC}, achieves state-of-the-art accuracy-fairness trade-off. Explicit control of the entropy of the representation bit stream allows the user to move smoothly and simultaneously along both rate-distortion and rate-fairness curves. \end{abstract}
Learning Smooth and Fair Representations
Jun 15, 2020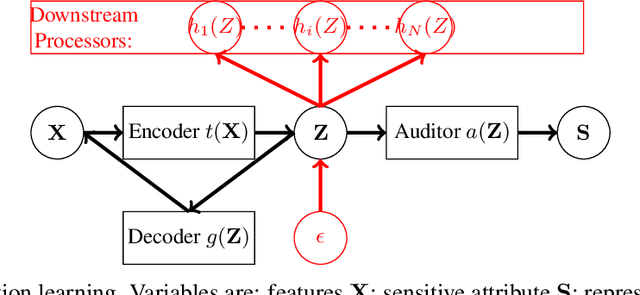
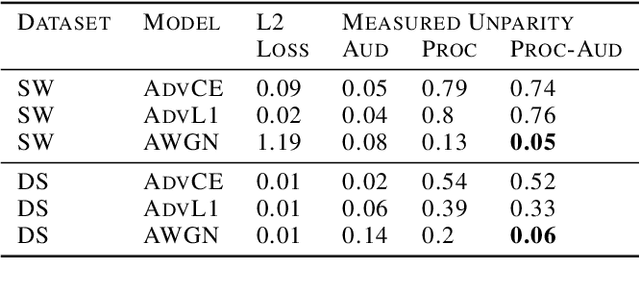

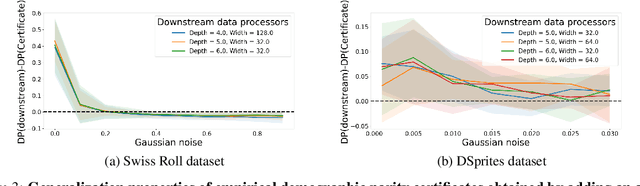
Organizations that own data face increasing legal liability for its discriminatory use against protected demographic groups, extending to contractual transactions involving third parties access and use of the data. This is problematic, since the original data owner cannot ex-ante anticipate all its future uses by downstream users. This paper explores the upstream ability to preemptively remove the correlations between features and sensitive attributes by mapping features to a fair representation space. Our main result shows that the fairness measured by the demographic parity of the representation distribution can be certified from a finite sample if and only if the chi-squared mutual information between features and representations is finite. Empirically, we find that smoothing the representation distribution provides generalization guarantees of fairness certificates, which improves upon existing fair representation learning approaches. Moreover, we do not observe that smoothing the representation distribution degrades the accuracy of downstream tasks compared to state-of-the-art methods in fair representation learning.
Single-Frame Super-Resolution of Solar Magnetograms: Investigating Physics-Based Metrics \& Losses
Nov 04, 2019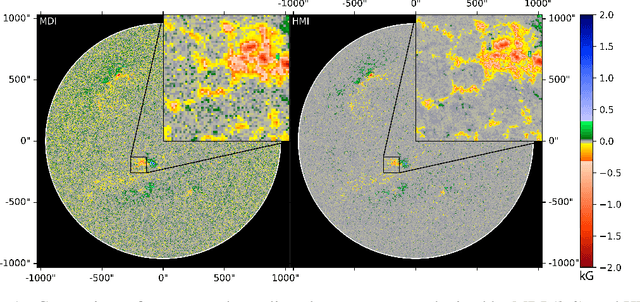
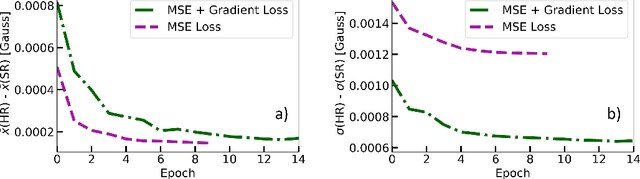
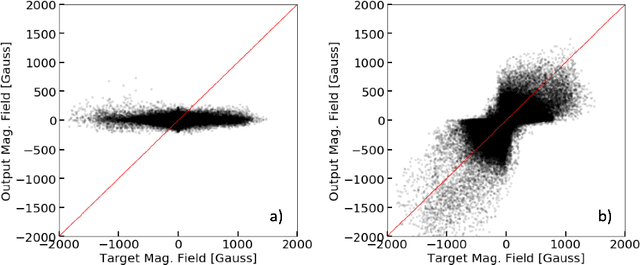
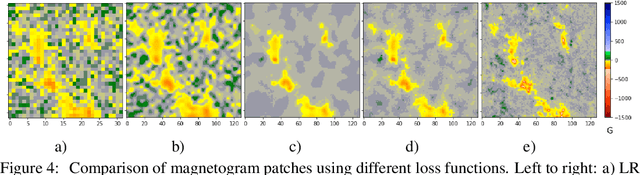
Breakthroughs in our understanding of physical phenomena have traditionally followed improvements in instrumentation. Studies of the magnetic field of the Sun, and its influence on the solar dynamo and space weather events, have benefited from improvements in resolution and measurement frequency of new instruments. However, in order to fully understand the solar cycle, high-quality data across time-scales longer than the typical lifespan of a solar instrument are required. At the moment, discrepancies between measurement surveys prevent the combined use of all available data. In this work, we show that machine learning can help bridge the gap between measurement surveys by learning to \textbf{super-resolve} low-resolution magnetic field images and \textbf{translate} between characteristics of contemporary instruments in orbit. We also introduce the notion of physics-based metrics and losses for super-resolution to preserve underlying physics and constrain the solution space of possible super-resolution outputs.
Probabilistic Super-Resolution of Solar Magnetograms: Generating Many Explanations and Measuring Uncertainties
Nov 04, 2019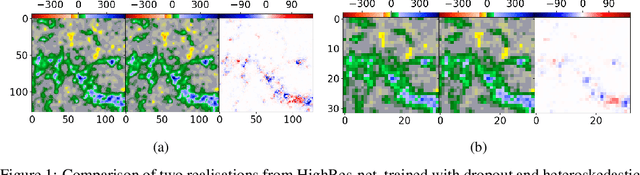

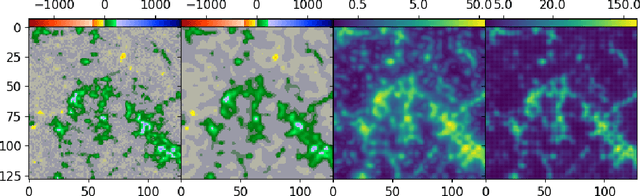
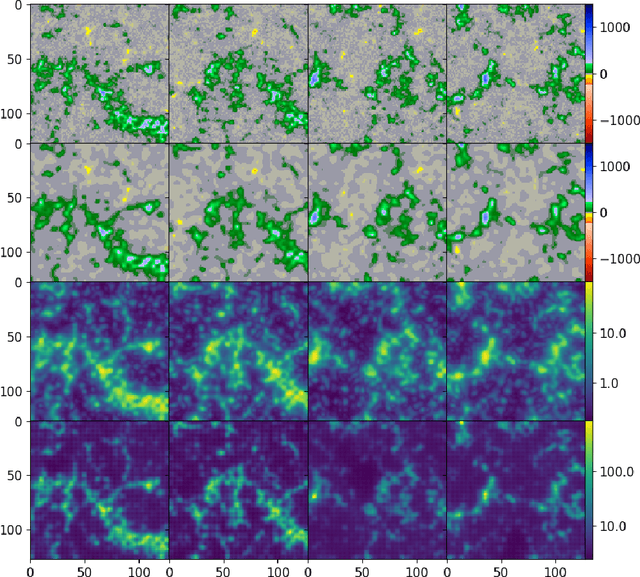
Machine learning techniques have been successfully applied to super-resolution tasks on natural images where visually pleasing results are sufficient. However in many scientific domains this is not adequate and estimations of errors and uncertainties are crucial. To address this issue we propose a Bayesian framework that decomposes uncertainties into epistemic and aleatoric uncertainties. We test the validity of our approach by super-resolving images of the Sun's magnetic field and by generating maps measuring the range of possible high resolution explanations compatible with a given low resolution magnetogram.
Multi-Differential Fairness Auditor for Black Box Classifiers
Mar 18, 2019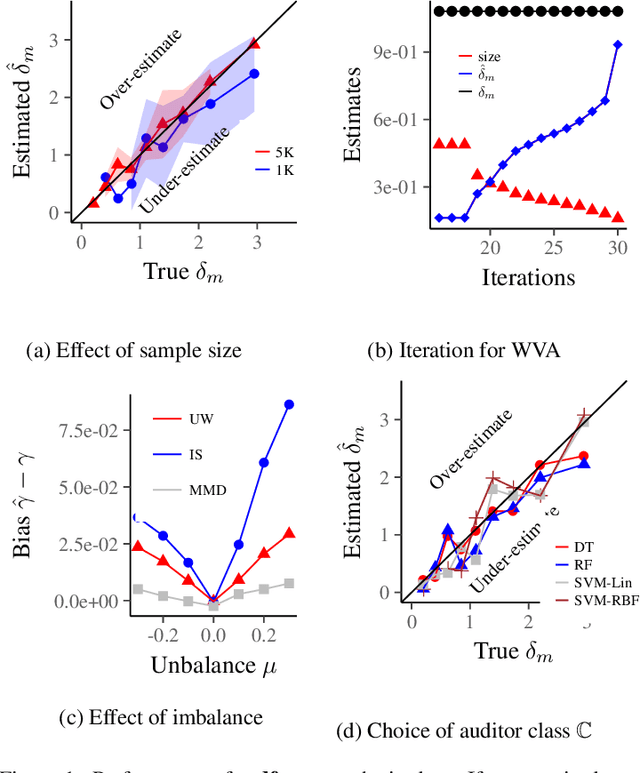
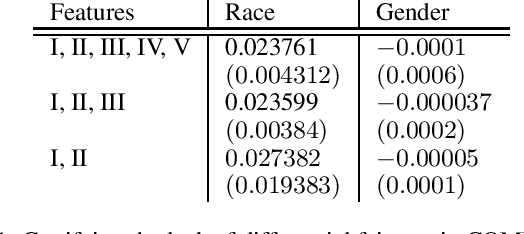
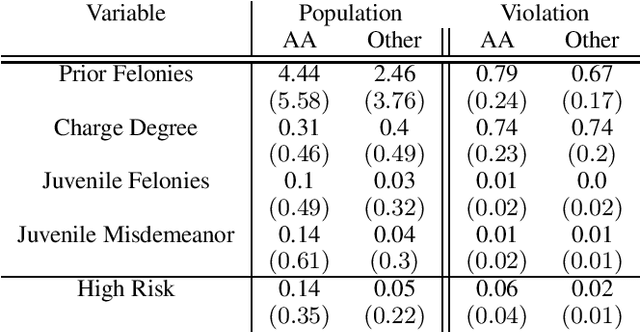
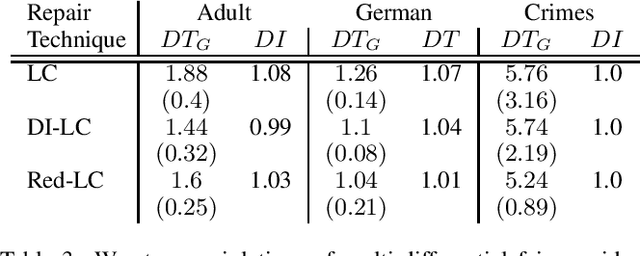
Machine learning algorithms are increasingly involved in sensitive decision-making process with adversarial implications on individuals. This paper presents mdfa, an approach that identifies the characteristics of the victims of a classifier's discrimination. We measure discrimination as a violation of multi-differential fairness. Multi-differential fairness is a guarantee that a black box classifier's outcomes do not leak information on the sensitive attributes of a small group of individuals. We reduce the problem of identifying worst-case violations to matching distributions and predicting where sensitive attributes and classifier's outcomes coincide. We apply mdfa to a recidivism risk assessment classifier and demonstrate that individuals identified as African-American with little criminal history are three-times more likely to be considered at high risk of violent recidivism than similar individuals but not African-American.