 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDispaRisk: Assessing and Interpreting Disparity Risks in Datasets
May 20, 2024



Machine Learning algorithms (ML) impact virtually every aspect of human lives and have found use across diverse sectors, including healthcare, finance, and education. Often, ML algorithms have been found to exacerbate societal biases presented in datasets, leading to adversarial impacts on subsets/groups of individuals, in many cases minority groups. To effectively mitigate these untoward effects, it is crucial that disparities/biases are identified and assessed early in a ML pipeline. This proactive approach facilitates timely interventions to prevent bias amplification and reduce complexity at later stages of model development. In this paper, we introduce DispaRisk, a novel framework designed to proactively assess the potential risks of disparities in datasets during the initial stages of the ML pipeline. We evaluate DispaRisk's effectiveness by benchmarking it with commonly used datasets in fairness research. Our findings demonstrate the capabilities of DispaRisk to identify datasets with a high-risk of discrimination, model families prone to biases, and characteristics that heighten discrimination susceptibility in a ML pipeline. The code for our experiments is available in the following repository: https://github.com/jovasque156/disparisk
Ex-Ante Assessment of Discrimination in Dataset
Aug 18, 2022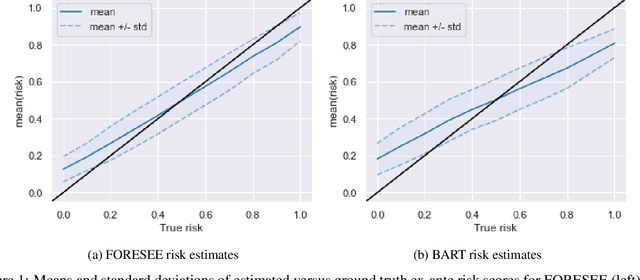
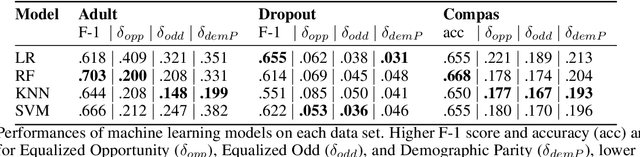
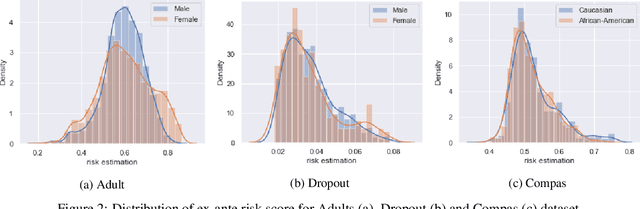
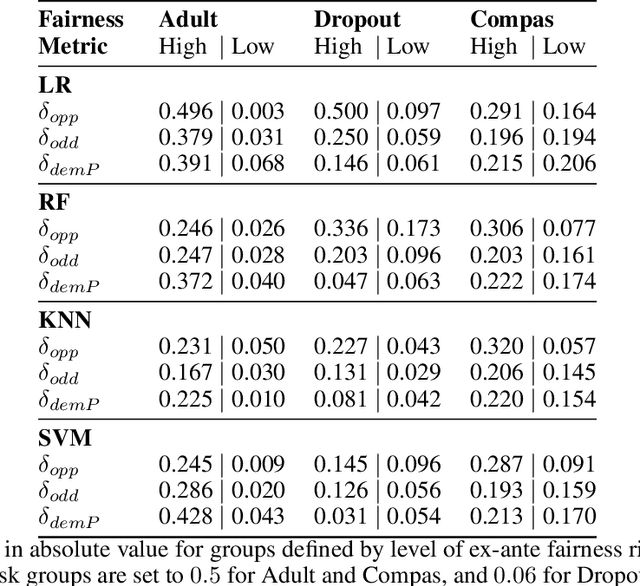
Data owners face increasing liability for how the use of their data could harm under-priviliged communities. Stakeholders would like to identify the characteristics of data that lead to algorithms being biased against any particular demographic groups, for example, defined by their race, gender, age, and/or religion. Specifically, we are interested in identifying subsets of the feature space where the ground truth response function from features to observed outcomes differs across demographic groups. To this end, we propose FORESEE, a FORESt of decision trEEs algorithm, which generates a score that captures how likely an individual's response varies with sensitive attributes. Empirically, we find that our approach allows us to identify the individuals who are most likely to be misclassified by several classifiers, including Random Forest, Logistic Regression, Support Vector Machine, and k-Nearest Neighbors. The advantage of our approach is that it allows stakeholders to characterize risky samples that may contribute to discrimination, as well as, use the FORESEE to estimate the risk of upcoming samples.