 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine Learning of Dynamic Causal Structures
Feb 26, 2026Learning the dynamic causal structure of time series is a challenging problem. Most existing approaches rely on distributional or structural invariance to uncover underlying causal dynamics, assuming stationary or partially stationary causality. However, these assumptions often conflict with the complex, time-varying causal relationships observed in real-world systems. This motivates the need for methods that address fully dynamic causality, where both instantaneous and lagged dependencies evolve over time. Such a setting poses significant challenges for the efficiency and stability of causal discovery. To address these challenges, we introduce DyCausal, a dynamic causal structure learning framework. DyCausal leverages convolutional networks to capture causal patterns within coarse-grained time windows, and then applies linear interpolation to refine causal structures at each time step, thereby recovering fine-grained and time-varying causal graphs. In addition, we propose an acyclic constraint based on matrix norm scaling, which improves efficiency while effectively constraining loops in evolving causal structures. Comprehensive evaluations on both synthetic and real-world datasets demonstrate that DyCausal achieves superior performance compared to existing methods, offering a stable and efficient approach for identifying fully dynamic causal structures from coarse to fine.
Inside CORE-KG: Evaluating Structured Prompting and Coreference Resolution for Knowledge Graphs
Oct 30, 2025Human smuggling networks are increasingly adaptive and difficult to analyze. Legal case documents offer critical insights but are often unstructured, lexically dense, and filled with ambiguous or shifting references, which pose significant challenges for automated knowledge graph (KG) construction. While recent LLM-based approaches improve over static templates, they still generate noisy, fragmented graphs with duplicate nodes due to the absence of guided extraction and coreference resolution. The recently proposed CORE-KG framework addresses these limitations by integrating a type-aware coreference module and domain-guided structured prompts, significantly reducing node duplication and legal noise. In this work, we present a systematic ablation study of CORE-KG to quantify the individual contributions of its two key components. Our results show that removing coreference resolution results in a 28.32% increase in node duplication and a 4.32% increase in noisy nodes, while removing structured prompts leads to a 4.34% increase in node duplication and a 73.33% increase in noisy nodes. These findings offer empirical insights for designing robust LLM-based pipelines for extracting structured representations from complex legal texts.
LINK-KG: LLM-Driven Coreference-Resolved Knowledge Graphs for Human Smuggling Networks
Oct 30, 2025Human smuggling networks are complex and constantly evolving, making them difficult to analyze comprehensively. Legal case documents offer rich factual and procedural insights into these networks but are often long, unstructured, and filled with ambiguous or shifting references, posing significant challenges for automated knowledge graph (KG) construction. Existing methods either overlook coreference resolution or fail to scale beyond short text spans, leading to fragmented graphs and inconsistent entity linking. We propose LINK-KG, a modular framework that integrates a three-stage, LLM-guided coreference resolution pipeline with downstream KG extraction. At the core of our approach is a type-specific Prompt Cache, which consistently tracks and resolves references across document chunks, enabling clean and disambiguated narratives for structured knowledge graph construction from both short and long legal texts. LINK-KG reduces average node duplication by 45.21% and noisy nodes by 32.22% compared to baseline methods, resulting in cleaner and more coherent graph structures. These improvements establish LINK-KG as a strong foundation for analyzing complex criminal networks.
Fairness is Not Silence: Unmasking Vacuous Neutrality in Small Language Models
Jun 10, 2025The rapid adoption of Small Language Models (SLMs) for on-device and resource-constrained deployments has outpaced our understanding of their ethical risks. To the best of our knowledge, we present the first large-scale audit of instruction-tuned SLMs spanning 0.5 to 5 billion parameters-an overlooked "middle tier" between BERT-class encoders and flagship LLMs. Our evaluation includes nine open-source models from the Qwen 2.5, LLaMA 3.2, Gemma 3, and Phi families. Using the BBQ benchmark under zero-shot prompting, we analyze both utility and fairness across ambiguous and disambiguated contexts. This evaluation reveals three key insights. First, competence and fairness need not be antagonistic: Phi models achieve F1 scores exceeding 90 percent while exhibiting minimal bias, showing that efficient and ethical NLP is attainable. Second, social bias varies significantly by architecture: Qwen 2.5 models may appear fair, but this often reflects vacuous neutrality, random guessing, or evasive behavior rather than genuine ethical alignment. In contrast, LLaMA 3.2 models exhibit stronger stereotypical bias, suggesting overconfidence rather than neutrality. Third, compression introduces nuanced trade-offs: 4-bit AWQ quantization improves F1 scores in ambiguous settings for LLaMA 3.2-3B but increases disability-related bias in Phi-4-Mini by over 7 percentage points. These insights provide practical guidance for the responsible deployment of SLMs in applications demanding fairness and efficiency, particularly benefiting small enterprises and resource-constrained environments.
DispaRisk: Assessing and Interpreting Disparity Risks in Datasets
May 20, 2024



Machine Learning algorithms (ML) impact virtually every aspect of human lives and have found use across diverse sectors, including healthcare, finance, and education. Often, ML algorithms have been found to exacerbate societal biases presented in datasets, leading to adversarial impacts on subsets/groups of individuals, in many cases minority groups. To effectively mitigate these untoward effects, it is crucial that disparities/biases are identified and assessed early in a ML pipeline. This proactive approach facilitates timely interventions to prevent bias amplification and reduce complexity at later stages of model development. In this paper, we introduce DispaRisk, a novel framework designed to proactively assess the potential risks of disparities in datasets during the initial stages of the ML pipeline. We evaluate DispaRisk's effectiveness by benchmarking it with commonly used datasets in fairness research. Our findings demonstrate the capabilities of DispaRisk to identify datasets with a high-risk of discrimination, model families prone to biases, and characteristics that heighten discrimination susceptibility in a ML pipeline. The code for our experiments is available in the following repository: https://github.com/jovasque156/disparisk
Federated Causality Learning with Explainable Adaptive Optimization
Dec 09, 2023



Discovering the causality from observational data is a crucial task in various scientific domains. With increasing awareness of privacy, data are not allowed to be exposed, and it is very hard to learn causal graphs from dispersed data, since these data may have different distributions. In this paper, we propose a federated causal discovery strategy (FedCausal) to learn the unified global causal graph from decentralized heterogeneous data. We design a global optimization formula to naturally aggregate the causal graphs from client data and constrain the acyclicity of the global graph without exposing local data. Unlike other federated causal learning algorithms, FedCausal unifies the local and global optimizations into a complete directed acyclic graph (DAG) learning process with a flexible optimization objective. We prove that this optimization objective has a high interpretability and can adaptively handle homogeneous and heterogeneous data. Experimental results on synthetic and real datasets show that FedCausal can effectively deal with non-independently and identically distributed (non-iid) data and has a superior performance.
Long-tail Cross Modal Hashing
Nov 28, 2022



Existing Cross Modal Hashing (CMH) methods are mainly designed for balanced data, while imbalanced data with long-tail distribution is more general in real-world. Several long-tail hashing methods have been proposed but they can not adapt for multi-modal data, due to the complex interplay between labels and individuality and commonality information of multi-modal data. Furthermore, CMH methods mostly mine the commonality of multi-modal data to learn hash codes, which may override tail labels encoded by the individuality of respective modalities. In this paper, we propose LtCMH (Long-tail CMH) to handle imbalanced multi-modal data. LtCMH firstly adopts auto-encoders to mine the individuality and commonality of different modalities by minimizing the dependency between the individuality of respective modalities and by enhancing the commonality of these modalities. Then it dynamically combines the individuality and commonality with direct features extracted from respective modalities to create meta features that enrich the representation of tail labels, and binaries meta features to generate hash codes. LtCMH significantly outperforms state-of-the-art baselines on long-tail datasets and holds a better (or comparable) performance on datasets with balanced labels.
Hub-VAE: Unsupervised Hub-based Regularization of Variational Autoencoders
Nov 18, 2022



Exemplar-based methods rely on informative data points or prototypes to guide the optimization of learning algorithms. Such data facilitate interpretable model design and prediction. Of particular interest is the utility of exemplars in learning unsupervised deep representations. In this paper, we leverage hubs, which emerge as frequent neighbors in high-dimensional spaces, as exemplars to regularize a variational autoencoder and to learn a discriminative embedding for unsupervised down-stream tasks. We propose an unsupervised, data-driven regularization of the latent space with a mixture of hub-based priors and a hub-based contrastive loss. Experimental evaluation shows that our algorithm achieves superior cluster separability in the embedding space, and accurate data reconstruction and generation, compared to baselines and state-of-the-art techniques.
MetaMIML: Meta Multi-Instance Multi-Label Learning
Nov 07, 2021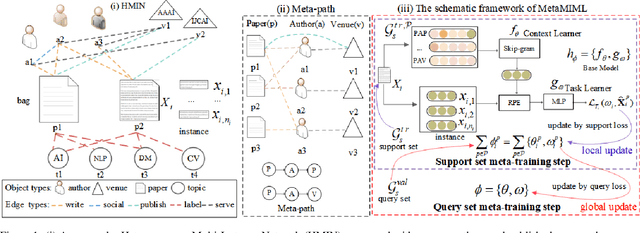
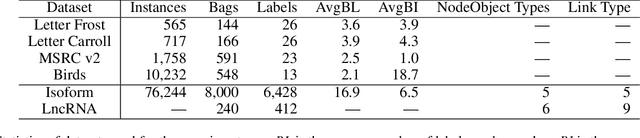
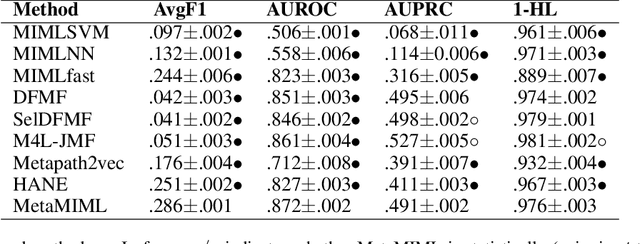

Multi-Instance Multi-Label learning (MIML) models complex objects (bags), each of which is associated with a set of interrelated labels and composed with a set of instances. Current MIML solutions still focus on a single-type of objects and assumes an IID distribution of training data. But these objects are linked with objects of other types, %(i.e., pictures in Facebook link with various users), which also encode the semantics of target objects. In addition, they generally need abundant labeled data for training. To effectively mine interdependent MIML objects of different types, we propose a network embedding and meta learning based approach (MetaMIML). MetaMIML introduces the context learner with network embedding to capture semantic information of objects of different types, and the task learner to extract the meta knowledge for fast adapting to new tasks. In this way, MetaMIML can naturally deal with MIML objects at data level improving, but also exploit the power of meta-learning at the model enhancing. Experiments on benchmark datasets demonstrate that MetaMIML achieves a significantly better performance than state-of-the-art algorithms.
Meta Cross-Modal Hashing on Long-Tailed Data
Nov 07, 2021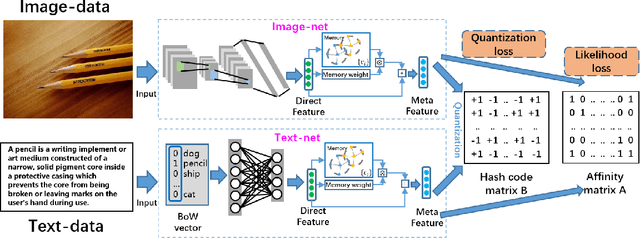
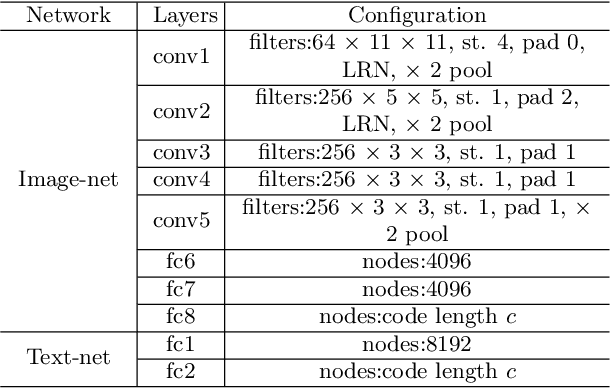
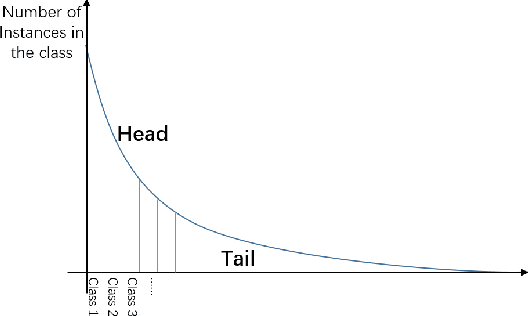

Due to the advantage of reducing storage while speeding up query time on big heterogeneous data, cross-modal hashing has been extensively studied for approximate nearest neighbor search of multi-modal data. Most hashing methods assume that training data is class-balanced.However, in practice, real world data often have a long-tailed distribution. In this paper, we introduce a meta-learning based cross-modal hashing method (MetaCMH) to handle long-tailed data. Due to the lack of training samples in the tail classes, MetaCMH first learns direct features from data in different modalities, and then introduces an associative memory module to learn the memory features of samples of the tail classes. It then combines the direct and memory features to obtain meta features for each sample. For samples of the head classes of the long tail distribution, the weight of the direct features is larger, because there are enough training data to learn them well; while for rare classes, the weight of the memory features is larger. Finally, MetaCMH uses a likelihood loss function to preserve the similarity in different modalities and learns hash functions in an end-to-end fashion. Experiments on long-tailed datasets show that MetaCMH performs significantly better than state-of-the-art methods, especially on the tail classes.