 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreating Crowdsourcing as Examination: How to Score Tasks and Online Workers?
Apr 26, 2022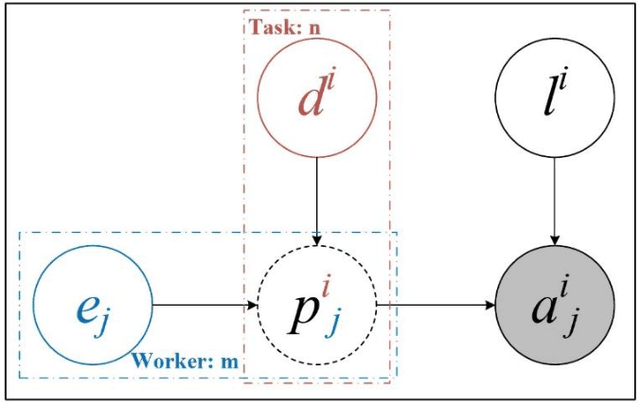

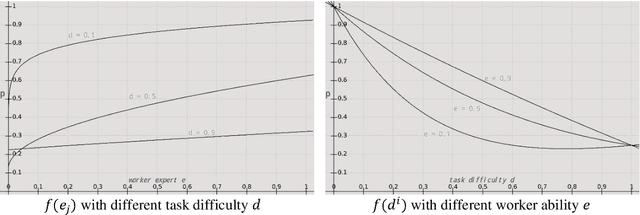
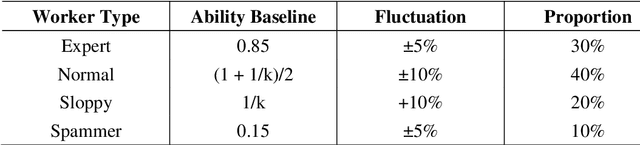
Crowdsourcing is an online outsourcing mode which can solve the current machine learning algorithm's urge need for massive labeled data. Requester posts tasks on crowdsourcing platforms, which employ online workers over the Internet to complete tasks, then aggregate and return results to requester. How to model the interaction between different types of workers and tasks is a hot spot. In this paper, we try to model workers as four types based on their ability: expert, normal worker, sloppy worker and spammer, and divide tasks into hard, medium and easy task according to their difficulty. We believe that even experts struggle with difficult tasks while sloppy workers can get easy tasks right, and spammers always give out wrong answers deliberately. So, good examination tasks should have moderate degree of difficulty and discriminability to score workers more objectively. Thus, we first score workers' ability mainly on the medium difficult tasks, then reducing the weight of answers from sloppy workers and modifying the answers from spammers when inferring the tasks' ground truth. A probability graph model is adopted to simulate the task execution process, and an iterative method is adopted to calculate and update the ground truth, the ability of workers and the difficulty of the task successively. We verify the rightness and effectiveness of our algorithm both in simulated and real crowdsourcing scenes.
Open-Set Crowdsourcing using Multiple-Source Transfer Learning
Nov 07, 2021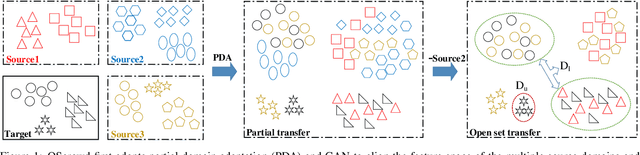

We raise and define a new crowdsourcing scenario, open set crowdsourcing, where we only know the general theme of an unfamiliar crowdsourcing project, and we don't know its label space, that is, the set of possible labels. This is still a task annotating problem, but the unfamiliarity with the tasks and the label space hampers the modelling of the task and of workers, and also the truth inference. We propose an intuitive solution, OSCrowd. First, OSCrowd integrates crowd theme related datasets into a large source domain to facilitate partial transfer learning to approximate the label space inference of these tasks. Next, it assigns weights to each source domain based on category correlation. After this, it uses multiple-source open set transfer learning to model crowd tasks and assign possible annotations. The label space and annotations given by transfer learning will be used to guide and standardize crowd workers' annotations. We validate OSCrowd in an online scenario, and prove that OSCrowd solves the open set crowdsourcing problem, works better than related crowdsourcing solutions.
Crowdsourcing with Meta-Workers: A New Way to Save the Budget
Nov 07, 2021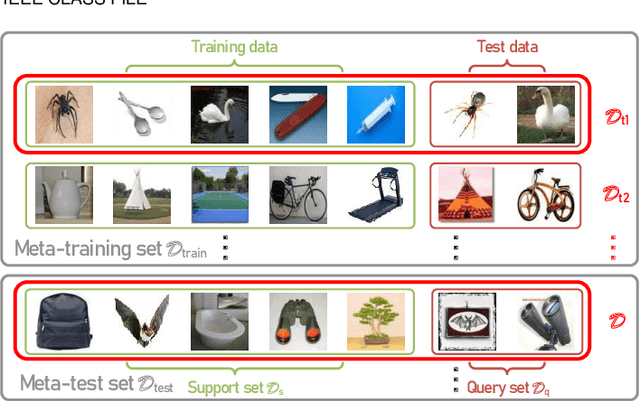
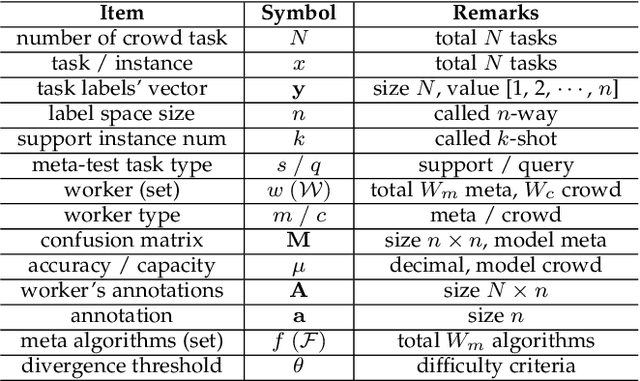
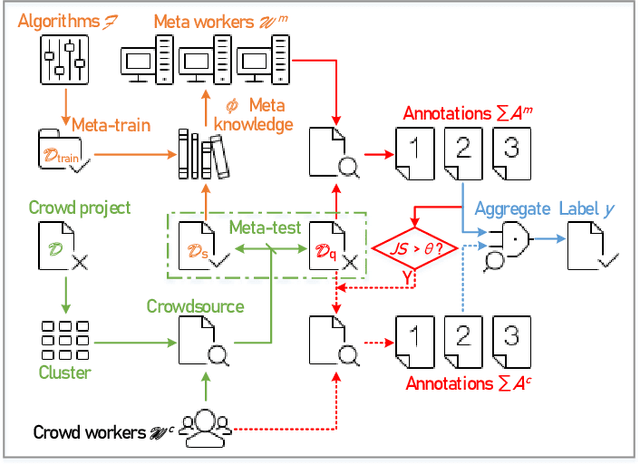

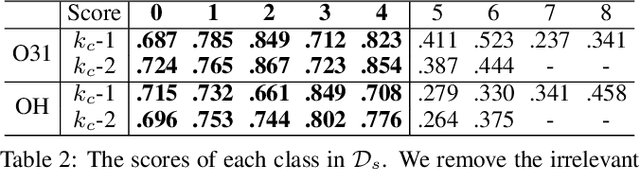
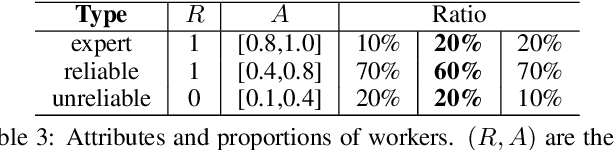
Due to the unreliability of Internet workers, it's difficult to complete a crowdsourcing project satisfactorily, especially when the tasks are multiple and the budget is limited. Recently, meta learning has brought new vitality to few-shot learning, making it possible to obtain a classifier with a fair performance using only a few training samples. Here we introduce the concept of \emph{meta-worker}, a machine annotator trained by meta learning for types of tasks (i.e., image classification) that are well-fit for AI. Unlike regular crowd workers, meta-workers can be reliable, stable, and more importantly, tireless and free. We first cluster unlabeled data and ask crowd workers to repeatedly annotate the instances nearby the cluster centers; we then leverage the annotated data and meta-training datasets to build a cluster of meta-workers using different meta learning algorithms. Subsequently, meta-workers are asked to annotate the remaining crowdsourced tasks. The Jensen-Shannon divergence is used to measure the disagreement among the annotations provided by the meta-workers, which determines whether or not crowd workers should be invited for further annotation of the same task. Finally, we model meta-workers' preferences and compute the consensus annotation by weighted majority voting. Our empirical study confirms that, by combining machine and human intelligence, we can accomplish a crowdsourcing project with a lower budget than state-of-the-art task assignment methods, while achieving a superior or comparable quality.