 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreating Crowdsourcing as Examination: How to Score Tasks and Online Workers?
Apr 26, 2022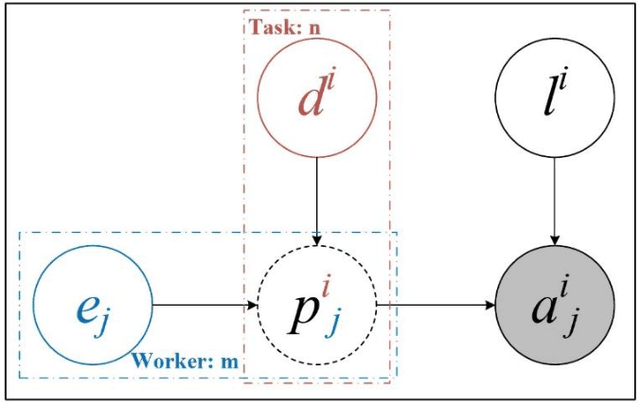

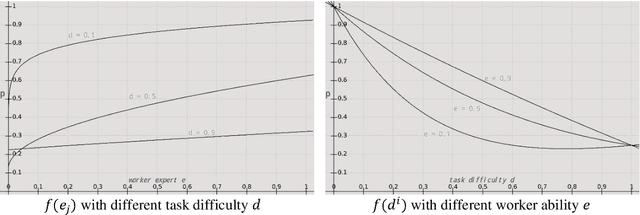
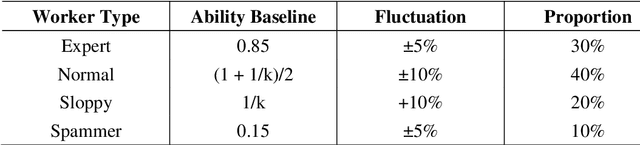
Crowdsourcing is an online outsourcing mode which can solve the current machine learning algorithm's urge need for massive labeled data. Requester posts tasks on crowdsourcing platforms, which employ online workers over the Internet to complete tasks, then aggregate and return results to requester. How to model the interaction between different types of workers and tasks is a hot spot. In this paper, we try to model workers as four types based on their ability: expert, normal worker, sloppy worker and spammer, and divide tasks into hard, medium and easy task according to their difficulty. We believe that even experts struggle with difficult tasks while sloppy workers can get easy tasks right, and spammers always give out wrong answers deliberately. So, good examination tasks should have moderate degree of difficulty and discriminability to score workers more objectively. Thus, we first score workers' ability mainly on the medium difficult tasks, then reducing the weight of answers from sloppy workers and modifying the answers from spammers when inferring the tasks' ground truth. A probability graph model is adopted to simulate the task execution process, and an iterative method is adopted to calculate and update the ground truth, the ability of workers and the difficulty of the task successively. We verify the rightness and effectiveness of our algorithm both in simulated and real crowdsourcing scenes.