 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Prototype Replay for Class Incremental Semantic Segmentation
Dec 17, 2024



Class incremental semantic segmentation (CISS) aims to segment new classes during continual steps while preventing the forgetting of old knowledge. Existing methods alleviate catastrophic forgetting by replaying distributions of previously learned classes using stored prototypes or features. However, they overlook a critical issue: in CISS, the representation of class knowledge is updated continuously through incremental learning, whereas prototype replay methods maintain fixed prototypes. This mismatch between updated representation and fixed prototypes limits the effectiveness of the prototype replay strategy. To address this issue, we propose the Adaptive prototype replay (Adapter) for CISS in this paper. Adapter comprises an adaptive deviation compen sation (ADC) strategy and an uncertainty-aware constraint (UAC) loss. Specifically, the ADC strategy dynamically updates the stored prototypes based on the estimated representation shift distance to match the updated representation of old class. The UAC loss reduces prediction uncertainty, aggregating discriminative features to aid in generating compact prototypes. Additionally, we introduce a compensation-based prototype similarity discriminative (CPD) loss to ensure adequate differentiation between similar prototypes, thereby enhancing the efficiency of the adaptive prototype replay strategy. Extensive experiments on Pascal VOC and ADE20K datasets demonstrate that Adapter achieves state-of-the-art results and proves effective across various CISS tasks, particularly in challenging multi-step scenarios. The code and model is available at https://github.com/zhu-gl-ux/Adapter.
Treating Crowdsourcing as Examination: How to Score Tasks and Online Workers?
Apr 26, 2022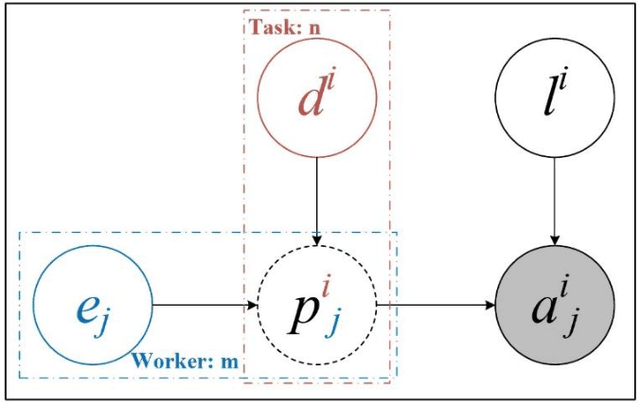

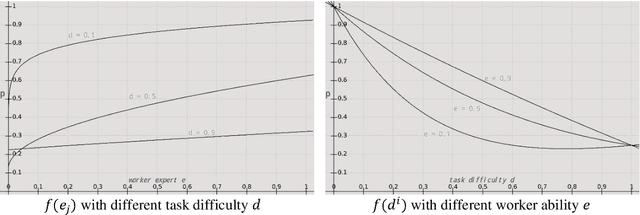
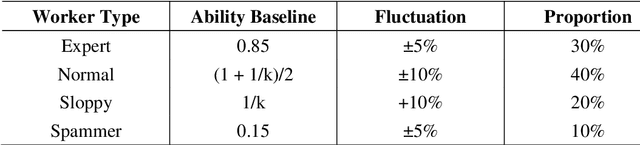
Crowdsourcing is an online outsourcing mode which can solve the current machine learning algorithm's urge need for massive labeled data. Requester posts tasks on crowdsourcing platforms, which employ online workers over the Internet to complete tasks, then aggregate and return results to requester. How to model the interaction between different types of workers and tasks is a hot spot. In this paper, we try to model workers as four types based on their ability: expert, normal worker, sloppy worker and spammer, and divide tasks into hard, medium and easy task according to their difficulty. We believe that even experts struggle with difficult tasks while sloppy workers can get easy tasks right, and spammers always give out wrong answers deliberately. So, good examination tasks should have moderate degree of difficulty and discriminability to score workers more objectively. Thus, we first score workers' ability mainly on the medium difficult tasks, then reducing the weight of answers from sloppy workers and modifying the answers from spammers when inferring the tasks' ground truth. A probability graph model is adopted to simulate the task execution process, and an iterative method is adopted to calculate and update the ground truth, the ability of workers and the difficulty of the task successively. We verify the rightness and effectiveness of our algorithm both in simulated and real crowdsourcing scenes.
Meta Cross-Modal Hashing on Long-Tailed Data
Nov 07, 2021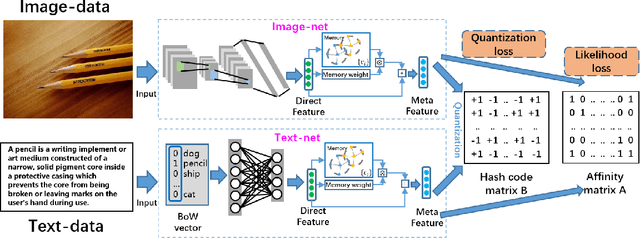
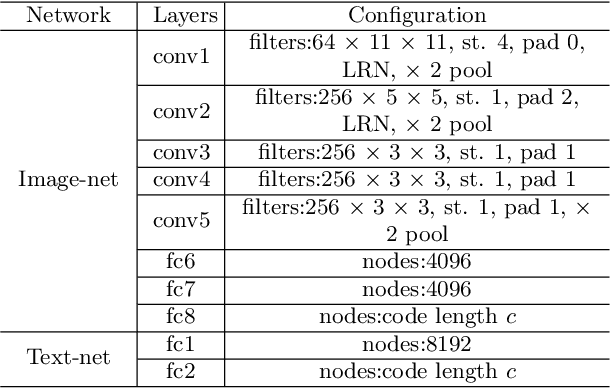
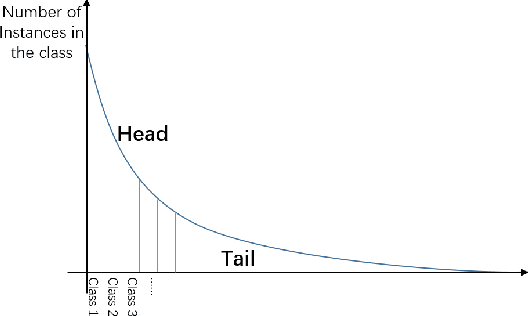

Due to the advantage of reducing storage while speeding up query time on big heterogeneous data, cross-modal hashing has been extensively studied for approximate nearest neighbor search of multi-modal data. Most hashing methods assume that training data is class-balanced.However, in practice, real world data often have a long-tailed distribution. In this paper, we introduce a meta-learning based cross-modal hashing method (MetaCMH) to handle long-tailed data. Due to the lack of training samples in the tail classes, MetaCMH first learns direct features from data in different modalities, and then introduces an associative memory module to learn the memory features of samples of the tail classes. It then combines the direct and memory features to obtain meta features for each sample. For samples of the head classes of the long tail distribution, the weight of the direct features is larger, because there are enough training data to learn them well; while for rare classes, the weight of the memory features is larger. Finally, MetaCMH uses a likelihood loss function to preserve the similarity in different modalities and learns hash functions in an end-to-end fashion. Experiments on long-tailed datasets show that MetaCMH performs significantly better than state-of-the-art methods, especially on the tail classes.
Cross-modal Zero-shot Hashing by Label Attributes Embedding
Nov 07, 2021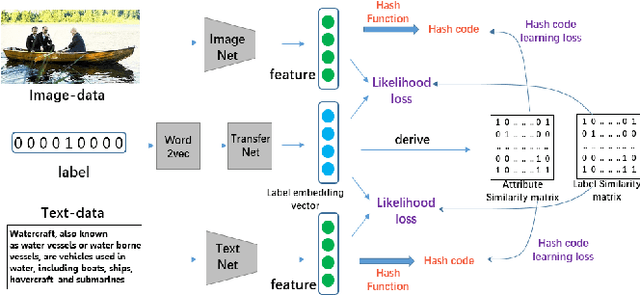
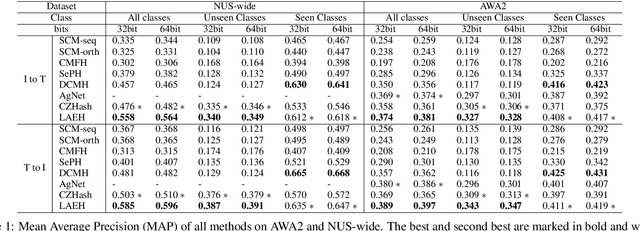
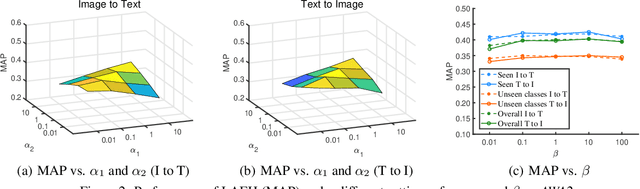
Cross-modal hashing (CMH) is one of the most promising methods in cross-modal approximate nearest neighbor search. Most CMH solutions ideally assume the labels of training and testing set are identical. However, the assumption is often violated, causing a zero-shot CMH problem. Recent efforts to address this issue focus on transferring knowledge from the seen classes to the unseen ones using label attributes. However, the attributes are isolated from the features of multi-modal data. To reduce the information gap, we introduce an approach called LAEH (Label Attributes Embedding for zero-shot cross-modal Hashing). LAEH first gets the initial semantic attribute vectors of labels by word2vec model and then uses a transformation network to transform them into a common subspace. Next, it leverages the hash vectors and the feature similarity matrix to guide the feature extraction network of different modalities. At the same time, LAEH uses the attribute similarity as the supplement of label similarity to rectify the label embedding and common subspace. Experiments show that LAEH outperforms related representative zero-shot and cross-modal hashing methods.