 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReID5o: Achieving Omni Multi-modal Person Re-identification in a Single Model
Jun 11, 2025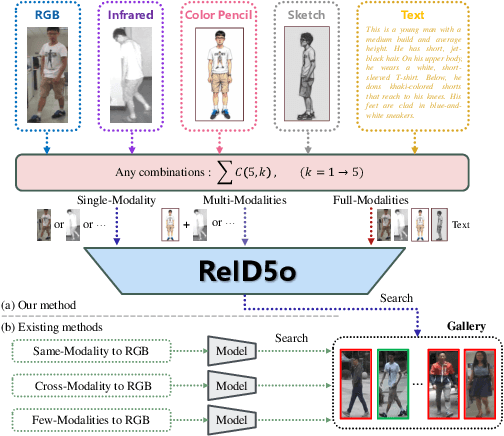
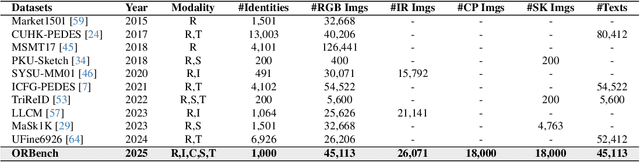
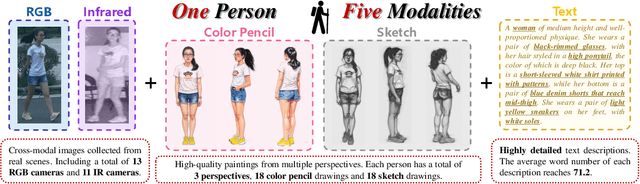
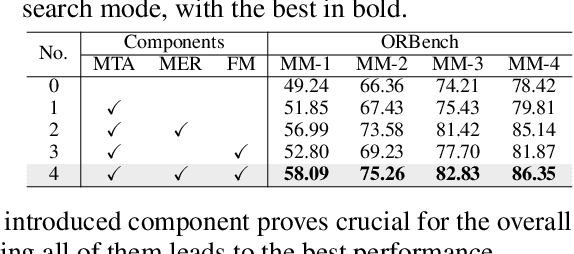
In real-word scenarios, person re-identification (ReID) expects to identify a person-of-interest via the descriptive query, regardless of whether the query is a single modality or a combination of multiple modalities. However, existing methods and datasets remain constrained to limited modalities, failing to meet this requirement. Therefore, we investigate a new challenging problem called Omni Multi-modal Person Re-identification (OM-ReID), which aims to achieve effective retrieval with varying multi-modal queries. To address dataset scarcity, we construct ORBench, the first high-quality multi-modal dataset comprising 1,000 unique identities across five modalities: RGB, infrared, color pencil, sketch, and textual description. This dataset also has significant superiority in terms of diversity, such as the painting perspectives and textual information. It could serve as an ideal platform for follow-up investigations in OM-ReID. Moreover, we propose ReID5o, a novel multi-modal learning framework for person ReID. It enables synergistic fusion and cross-modal alignment of arbitrary modality combinations in a single model, with a unified encoding and multi-expert routing mechanism proposed. Extensive experiments verify the advancement and practicality of our ORBench. A wide range of possible models have been evaluated and compared on it, and our proposed ReID5o model gives the best performance. The dataset and code will be made publicly available at https://github.com/Zplusdragon/ReID5o_ORBench.
Object-Aware Video Matting with Cross-Frame Guidance
Mar 03, 2025



Recently, trimap-free methods have drawn increasing attention in human video matting due to their promising performance. Nevertheless, these methods still suffer from the lack of deterministic foreground-background cues, which impairs their ability to consistently identify and locate foreground targets over time and mine fine-grained details. In this paper, we present a trimap-free Object-Aware Video Matting (OAVM) framework, which can perceive different objects, enabling joint recognition of foreground objects and refinement of edge details. Specifically, we propose an Object-Guided Correction and Refinement (OGCR) module, which employs cross-frame guidance to aggregate object-level instance information into pixel-level detail features, thereby promoting their synergy. Furthermore, we design a Sequential Foreground Merging augmentation strategy to diversify sequential scenarios and enhance capacity of the network for object discrimination. Extensive experiments on recent widely used synthetic and real-world benchmarks demonstrate the state-of-the-art performance of our OAVM with only an initial coarse mask. The code and model will be available.
Adaptive Prototype Replay for Class Incremental Semantic Segmentation
Dec 17, 2024



Class incremental semantic segmentation (CISS) aims to segment new classes during continual steps while preventing the forgetting of old knowledge. Existing methods alleviate catastrophic forgetting by replaying distributions of previously learned classes using stored prototypes or features. However, they overlook a critical issue: in CISS, the representation of class knowledge is updated continuously through incremental learning, whereas prototype replay methods maintain fixed prototypes. This mismatch between updated representation and fixed prototypes limits the effectiveness of the prototype replay strategy. To address this issue, we propose the Adaptive prototype replay (Adapter) for CISS in this paper. Adapter comprises an adaptive deviation compen sation (ADC) strategy and an uncertainty-aware constraint (UAC) loss. Specifically, the ADC strategy dynamically updates the stored prototypes based on the estimated representation shift distance to match the updated representation of old class. The UAC loss reduces prediction uncertainty, aggregating discriminative features to aid in generating compact prototypes. Additionally, we introduce a compensation-based prototype similarity discriminative (CPD) loss to ensure adequate differentiation between similar prototypes, thereby enhancing the efficiency of the adaptive prototype replay strategy. Extensive experiments on Pascal VOC and ADE20K datasets demonstrate that Adapter achieves state-of-the-art results and proves effective across various CISS tasks, particularly in challenging multi-step scenarios. The code and model is available at https://github.com/zhu-gl-ux/Adapter.
Structural Pruning via Spatial-aware Information Redundancy for Semantic Segmentation
Dec 17, 2024



In recent years, semantic segmentation has flourished in various applications. However, the high computational cost remains a significant challenge that hinders its further adoption. The filter pruning method for structured network slimming offers a direct and effective solution for the reduction of segmentation networks. Nevertheless, we argue that most existing pruning methods, originally designed for image classification, overlook the fact that segmentation is a location-sensitive task, which consequently leads to their suboptimal performance when applied to segmentation networks. To address this issue, this paper proposes a novel approach, denoted as Spatial-aware Information Redundancy Filter Pruning~(SIRFP), which aims to reduce feature redundancy between channels. First, we formulate the pruning process as a maximum edge weight clique problem~(MEWCP) in graph theory, thereby minimizing the redundancy among the remaining features after pruning. Within this framework, we introduce a spatial-aware redundancy metric based on feature maps, thus endowing the pruning process with location sensitivity to better adapt to pruning segmentation networks. Additionally, based on the MEWCP, we propose a low computational complexity greedy strategy to solve this NP-hard problem, making it feasible and efficient for structured pruning. To validate the effectiveness of our method, we conducted extensive comparative experiments on various challenging datasets. The results demonstrate the superior performance of SIRFP for semantic segmentation tasks.
SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation
Jan 15, 2024Recent real-time semantic segmentation methods usually adopt an additional semantic branch to pursue rich long-range context. However, the additional branch incurs undesirable computational overhead and slows inference speed. To eliminate this dilemma, we propose SCTNet, a single branch CNN with transformer semantic information for real-time segmentation. SCTNet enjoys the rich semantic representations of an inference-free semantic branch while retaining the high efficiency of lightweight single branch CNN. SCTNet utilizes a transformer as the training-only semantic branch considering its superb ability to extract long-range context. With the help of the proposed transformer-like CNN block CFBlock and the semantic information alignment module, SCTNet could capture the rich semantic information from the transformer branch in training. During the inference, only the single branch CNN needs to be deployed. We conduct extensive experiments on Cityscapes, ADE20K, and COCO-Stuff-10K, and the results show that our method achieves the new state-of-the-art performance. The code and model is available at https://github.com/xzz777/SCTNet
Semantic Segmentation via Pixel-to-Center Similarity Calculation
Jan 12, 2023



Since the fully convolutional network has achieved great success in semantic segmentation, lots of works have been proposed focusing on extracting discriminative pixel feature representations. However, we observe that existing methods still suffer from two typical challenges, i.e. (i) large intra-class feature variation in different scenes, (ii) small inter-class feature distinction in the same scene. In this paper, we first rethink semantic segmentation from a perspective of similarity between pixels and class centers. Each weight vector of the segmentation head represents its corresponding semantic class in the whole dataset, which can be regarded as the embedding of the class center. Thus, the pixel-wise classification amounts to computing similarity in the final feature space between pixels and the class centers. Under this novel view, we propose a Class Center Similarity layer (CCS layer) to address the above-mentioned challenges by generating adaptive class centers conditioned on different scenes and supervising the similarities between class centers. It utilizes a Adaptive Class Center Module (ACCM) to generate class centers conditioned on each scene, which adapt the large intra-class variation between different scenes. Specially designed loss functions are introduced to control both inter-class and intra-class distances based on predicted center-to-center and pixel-to-center similarity, respectively. Finally, the CCS layer outputs the processed pixel-to-center similarity as the segmentation prediction. Extensive experiments demonstrate that our model performs favourably against the state-of-the-art CNN-based methods.