 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTstars-Tryon 1.0: Robust and Realistic Virtual Try-On for Diverse Fashion Items
Apr 22, 2026Recent advances in image generation and editing have opened new opportunities for virtual try-on. However, existing methods still struggle to meet complex real-world demands. We present Tstars-Tryon 1.0, a commercial-scale virtual try-on system that is robust, realistic, versatile, and highly efficient. First, our system maintains a high success rate across challenging cases like extreme poses, severe illumination variations, motion blur, and other in-the-wild conditions. Second, it delivers highly photorealistic results with fine-grained details, faithfully preserving garment texture, material properties, and structural characteristics, while largely avoiding common AI-generated artifacts. Third, beyond apparel try-on, our model supports flexible multi-image composition (up to 6 reference images) across 8 fashion categories, with coordinated control over person identity and background. Fourth, to overcome the latency bottlenecks of commercial deployment, our system is heavily optimized for inference speed, delivering near real-time generation for a seamless user experience. These capabilities are enabled by an integrated system design spanning end-to-end model architecture, a scalable data engine, robust infrastructure, and a multi-stage training paradigm. Extensive evaluation and large-scale product deployment demonstrate that Tstars-Tryon1.0 achieves leading overall performance. To support future research, we also release a comprehensive benchmark. The model has been deployed at an industrial scale on the Taobao App, serving millions of users with tens of millions of requests.
Tunnel Try-on: Excavating Spatial-temporal Tunnels for High-quality Virtual Try-on in Videos
Apr 26, 2024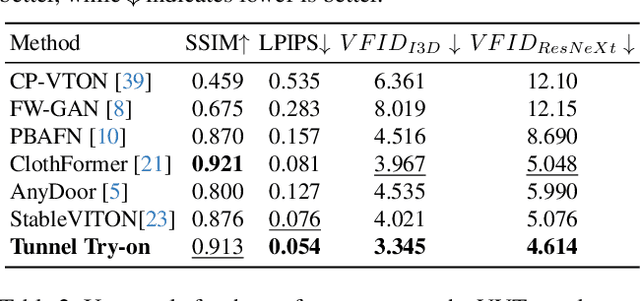
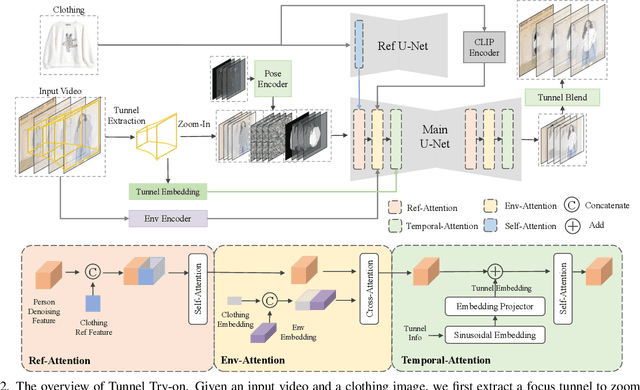
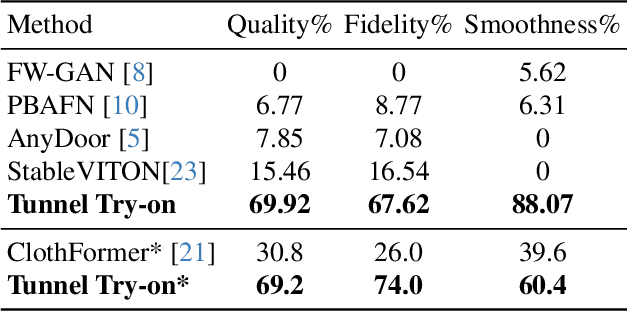

Video try-on is a challenging task and has not been well tackled in previous works. The main obstacle lies in preserving the details of the clothing and modeling the coherent motions simultaneously. Faced with those difficulties, we address video try-on by proposing a diffusion-based framework named "Tunnel Try-on." The core idea is excavating a "focus tunnel" in the input video that gives close-up shots around the clothing regions. We zoom in on the region in the tunnel to better preserve the fine details of the clothing. To generate coherent motions, we first leverage the Kalman filter to construct smooth crops in the focus tunnel and inject the position embedding of the tunnel into attention layers to improve the continuity of the generated videos. In addition, we develop an environment encoder to extract the context information outside the tunnels as supplementary cues. Equipped with these techniques, Tunnel Try-on keeps the fine details of the clothing and synthesizes stable and smooth videos. Demonstrating significant advancements, Tunnel Try-on could be regarded as the first attempt toward the commercial-level application of virtual try-on in videos.
SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation
Jan 15, 2024Recent real-time semantic segmentation methods usually adopt an additional semantic branch to pursue rich long-range context. However, the additional branch incurs undesirable computational overhead and slows inference speed. To eliminate this dilemma, we propose SCTNet, a single branch CNN with transformer semantic information for real-time segmentation. SCTNet enjoys the rich semantic representations of an inference-free semantic branch while retaining the high efficiency of lightweight single branch CNN. SCTNet utilizes a transformer as the training-only semantic branch considering its superb ability to extract long-range context. With the help of the proposed transformer-like CNN block CFBlock and the semantic information alignment module, SCTNet could capture the rich semantic information from the transformer branch in training. During the inference, only the single branch CNN needs to be deployed. We conduct extensive experiments on Cityscapes, ADE20K, and COCO-Stuff-10K, and the results show that our method achieves the new state-of-the-art performance. The code and model is available at https://github.com/xzz777/SCTNet