 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunnel Try-on: Excavating Spatial-temporal Tunnels for High-quality Virtual Try-on in Videos
Apr 26, 2024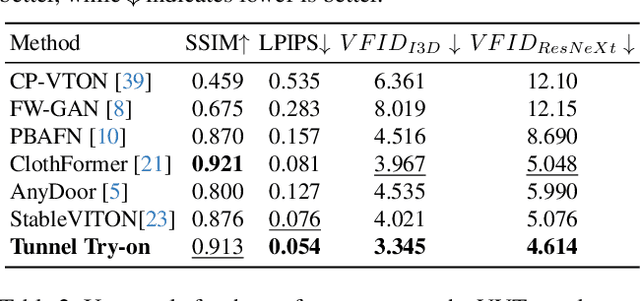
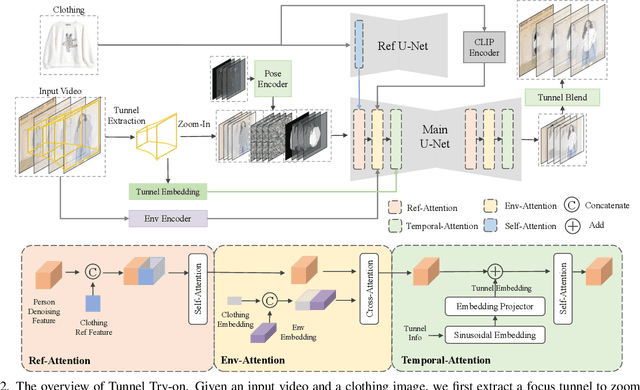
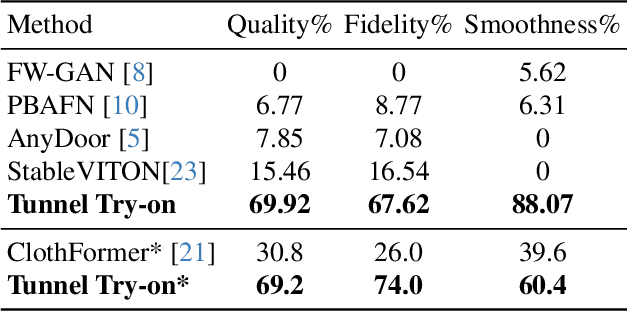

Video try-on is a challenging task and has not been well tackled in previous works. The main obstacle lies in preserving the details of the clothing and modeling the coherent motions simultaneously. Faced with those difficulties, we address video try-on by proposing a diffusion-based framework named "Tunnel Try-on." The core idea is excavating a "focus tunnel" in the input video that gives close-up shots around the clothing regions. We zoom in on the region in the tunnel to better preserve the fine details of the clothing. To generate coherent motions, we first leverage the Kalman filter to construct smooth crops in the focus tunnel and inject the position embedding of the tunnel into attention layers to improve the continuity of the generated videos. In addition, we develop an environment encoder to extract the context information outside the tunnels as supplementary cues. Equipped with these techniques, Tunnel Try-on keeps the fine details of the clothing and synthesizes stable and smooth videos. Demonstrating significant advancements, Tunnel Try-on could be regarded as the first attempt toward the commercial-level application of virtual try-on in videos.
Enhanced Multimodal Representation Learning with Cross-modal KD
Jun 13, 2023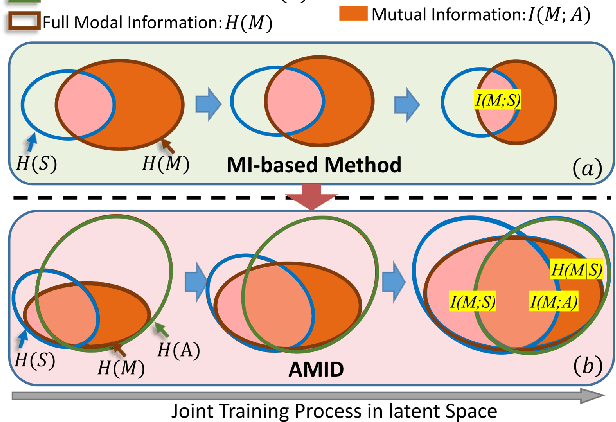
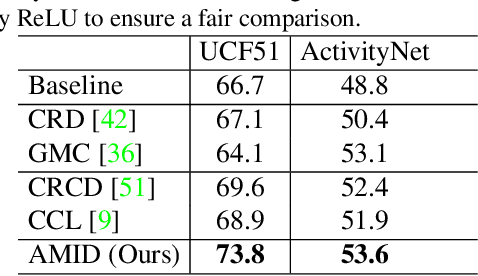

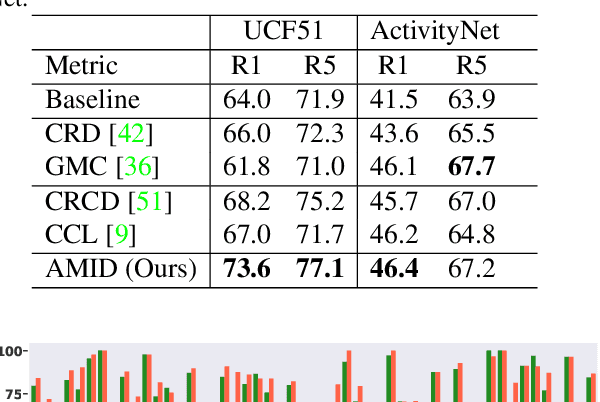
This paper explores the tasks of leveraging auxiliary modalities which are only available at training to enhance multimodal representation learning through cross-modal Knowledge Distillation (KD). The widely adopted mutual information maximization-based objective leads to a short-cut solution of the weak teacher, i.e., achieving the maximum mutual information by simply making the teacher model as weak as the student model. To prevent such a weak solution, we introduce an additional objective term, i.e., the mutual information between the teacher and the auxiliary modality model. Besides, to narrow down the information gap between the student and teacher, we further propose to minimize the conditional entropy of the teacher given the student. Novel training schemes based on contrastive learning and adversarial learning are designed to optimize the mutual information and the conditional entropy, respectively. Experimental results on three popular multimodal benchmark datasets have shown that the proposed method outperforms a range of state-of-the-art approaches for video recognition, video retrieval and emotion classification.