 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential-informed Sample Selection Accelerates Multimodal Contrastive Learning
Jul 17, 2025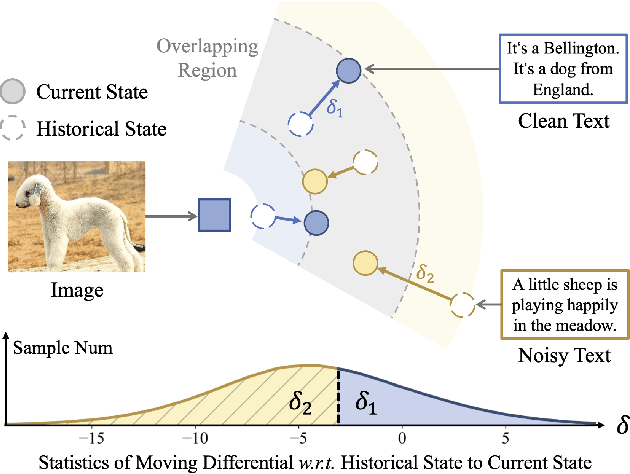
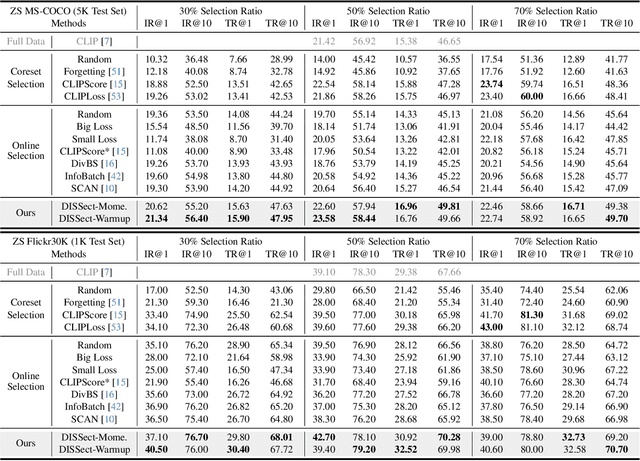
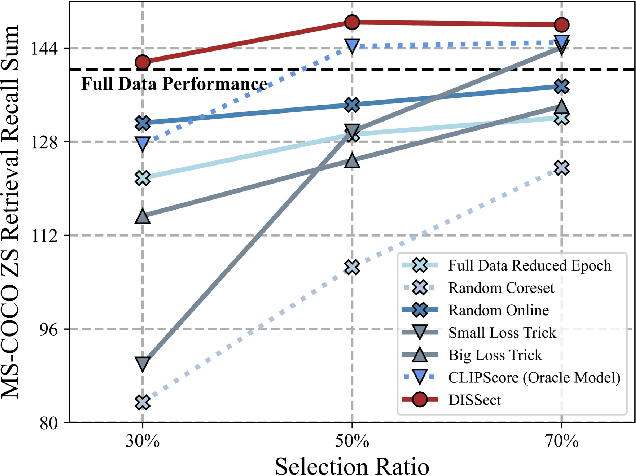
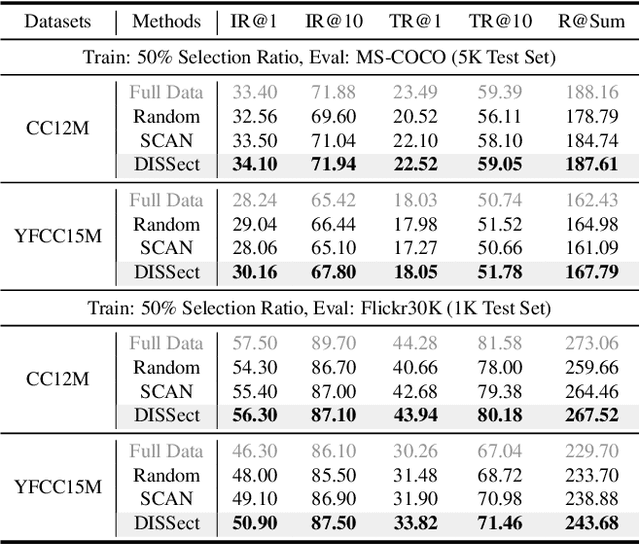
The remarkable success of contrastive-learning-based multimodal models has been greatly driven by training on ever-larger datasets with expensive compute consumption. Sample selection as an alternative efficient paradigm plays an important direction to accelerate the training process. However, recent advances on sample selection either mostly rely on an oracle model to offline select a high-quality coreset, which is limited in the cold-start scenarios, or focus on online selection based on real-time model predictions, which has not sufficiently or efficiently considered the noisy correspondence. To address this dilemma, we propose a novel Differential-Informed Sample Selection (DISSect) method, which accurately and efficiently discriminates the noisy correspondence for training acceleration. Specifically, we rethink the impact of noisy correspondence on contrastive learning and propose that the differential between the predicted correlation of the current model and that of a historical model is more informative to characterize sample quality. Based on this, we construct a robust differential-based sample selection and analyze its theoretical insights. Extensive experiments on three benchmark datasets and various downstream tasks demonstrate the consistent superiority of DISSect over current state-of-the-art methods. Source code is available at: https://github.com/MediaBrain-SJTU/DISSect.
Mitigating Noisy Correspondence by Geometrical Structure Consistency Learning
May 27, 2024



Noisy correspondence that refers to mismatches in cross-modal data pairs, is prevalent on human-annotated or web-crawled datasets. Prior approaches to leverage such data mainly consider the application of uni-modal noisy label learning without amending the impact on both cross-modal and intra-modal geometrical structures in multimodal learning. Actually, we find that both structures are effective to discriminate noisy correspondence through structural differences when being well-established. Inspired by this observation, we introduce a Geometrical Structure Consistency (GSC) method to infer the true correspondence. Specifically, GSC ensures the preservation of geometrical structures within and between modalities, allowing for the accurate discrimination of noisy samples based on structural differences. Utilizing these inferred true correspondence labels, GSC refines the learning of geometrical structures by filtering out the noisy samples. Experiments across four cross-modal datasets confirm that GSC effectively identifies noisy samples and significantly outperforms the current leading methods.
Enhanced Multimodal Representation Learning with Cross-modal KD
Jun 13, 2023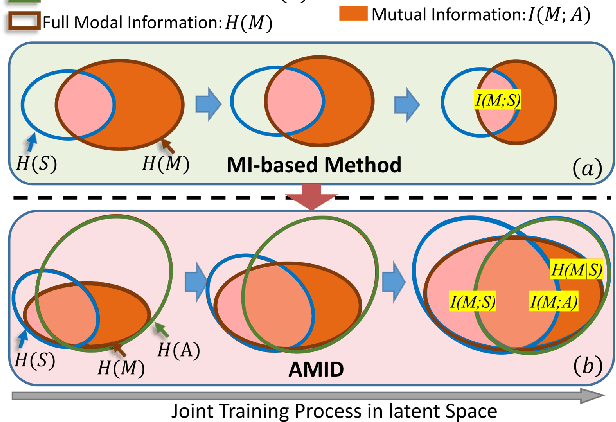
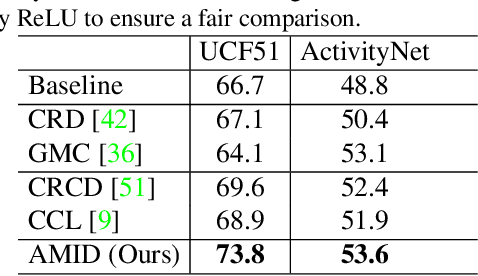

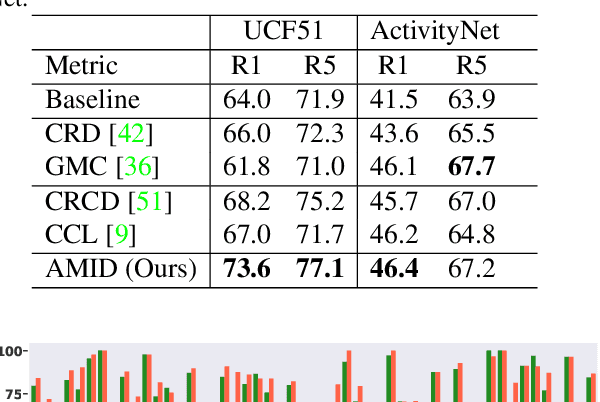
This paper explores the tasks of leveraging auxiliary modalities which are only available at training to enhance multimodal representation learning through cross-modal Knowledge Distillation (KD). The widely adopted mutual information maximization-based objective leads to a short-cut solution of the weak teacher, i.e., achieving the maximum mutual information by simply making the teacher model as weak as the student model. To prevent such a weak solution, we introduce an additional objective term, i.e., the mutual information between the teacher and the auxiliary modality model. Besides, to narrow down the information gap between the student and teacher, we further propose to minimize the conditional entropy of the teacher given the student. Novel training schemes based on contrastive learning and adversarial learning are designed to optimize the mutual information and the conditional entropy, respectively. Experimental results on three popular multimodal benchmark datasets have shown that the proposed method outperforms a range of state-of-the-art approaches for video recognition, video retrieval and emotion classification.