 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunnel Try-on: Excavating Spatial-temporal Tunnels for High-quality Virtual Try-on in Videos
Paper and Code
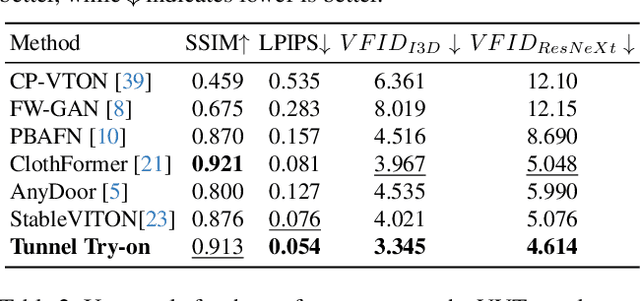
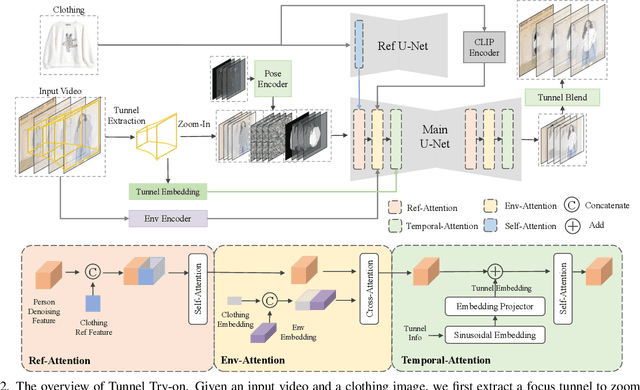
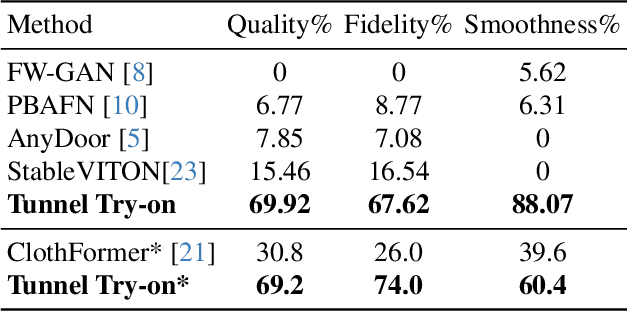

Video try-on is a challenging task and has not been well tackled in previous works. The main obstacle lies in preserving the details of the clothing and modeling the coherent motions simultaneously. Faced with those difficulties, we address video try-on by proposing a diffusion-based framework named "Tunnel Try-on." The core idea is excavating a "focus tunnel" in the input video that gives close-up shots around the clothing regions. We zoom in on the region in the tunnel to better preserve the fine details of the clothing. To generate coherent motions, we first leverage the Kalman filter to construct smooth crops in the focus tunnel and inject the position embedding of the tunnel into attention layers to improve the continuity of the generated videos. In addition, we develop an environment encoder to extract the context information outside the tunnels as supplementary cues. Equipped with these techniques, Tunnel Try-on keeps the fine details of the clothing and synthesizes stable and smooth videos. Demonstrating significant advancements, Tunnel Try-on could be regarded as the first attempt toward the commercial-level application of virtual try-on in videos.