 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWRF4CIR: Weight-Regularized Fine-Tuning Network for Composed Image Retrieval
Apr 07, 2026Composed Image Retrieval (CIR) task aims to retrieve target images based on reference images and modification texts. Current CIR methods primarily rely on fine-tuning vision-language pre-trained models. However, we find that these approaches commonly suffer from severe overfitting, posing challenges for CIR with limited triplet data. To better understand this issue, we present a systematic study of overfitting in VLP-based CIR, revealing a significant and previously overlooked generalization gap across different models and datasets. Motivated by these findings, we introduce WRF4CIR, a Weight-Regularized Fine-tuning network for CIR. Specifically, during the fine-tuning process, we apply adversarial perturbations to the model weights for regularization, where these perturbations are generated in the opposite direction of gradient descent. Intuitively, WRF4CIR increases the difficulty of fitting the training data, which helps mitigate overfitting in CIR under limited triplet supervision. Extensive experiments on benchmark datasets demonstrate that WRF4CIR significantly narrows the generalization gap and achieves substantial improvements over existing methods.
Stealthy and Adjustable Text-Guided Backdoor Attacks on Multimodal Pretrained Models
Apr 07, 2026Multimodal pretrained models are vulnerable to backdoor attacks, yet most existing methods rely on visual or multimodal triggers, which are impractical since visually embedded triggers rarely occur in real-world data. To overcome this limitation, we propose a novel Text-Guided Backdoor (TGB) attack on multimodal pretrained models, where commonly occurring words in textual descriptions serve as backdoor triggers, significantly improving stealthiness and practicality. Furthermore, we introduce visual adversarial perturbations on poisoned samples to modulate the model's learning of textual triggers, enabling a controllable and adjustable TGB attack. Extensive experiments on downstream tasks built upon multimodal pretrained models, including Composed Image Retrieval (CIR) and Visual Question Answering (VQA), demonstrate that TGB achieves practicality and stealthiness with adjustable attack success rates across diverse realistic settings, revealing critical security vulnerabilities in multimodal pretrained models.
Learning Unpaired Image Dehazing with Physics-based Rehazy Generation
Jun 15, 2025
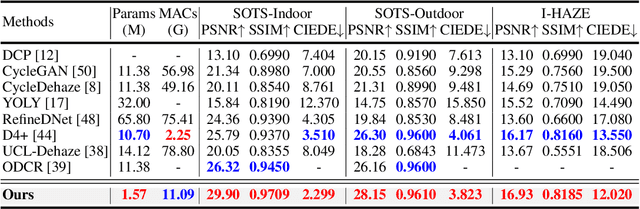
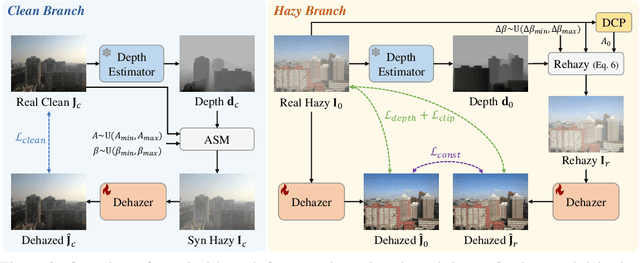
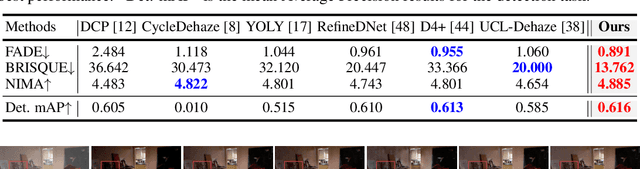
Overfitting to synthetic training pairs remains a critical challenge in image dehazing, leading to poor generalization capability to real-world scenarios. To address this issue, existing approaches utilize unpaired realistic data for training, employing CycleGAN or contrastive learning frameworks. Despite their progress, these methods often suffer from training instability, resulting in limited dehazing performance. In this paper, we propose a novel training strategy for unpaired image dehazing, termed Rehazy, to improve both dehazing performance and training stability. This strategy explores the consistency of the underlying clean images across hazy images and utilizes hazy-rehazy pairs for effective learning of real haze characteristics. To favorably construct hazy-rehazy pairs, we develop a physics-based rehazy generation pipeline, which is theoretically validated to reliably produce high-quality rehazy images. Additionally, leveraging the rehazy strategy, we introduce a dual-branch framework for dehazing network training, where a clean branch provides a basic dehazing capability in a synthetic manner, and a hazy branch enhances the generalization ability with hazy-rehazy pairs. Moreover, we design a new dehazing network within these branches to improve the efficiency, which progressively restores clean scenes from coarse to fine. Extensive experiments on four benchmarks demonstrate the superior performance of our approach, exceeding the previous state-of-the-art methods by 3.58 dB on the SOTS-Indoor dataset and by 1.85 dB on the SOTS-Outdoor dataset in PSNR. Our code will be publicly available.
NTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Object-Aware Video Matting with Cross-Frame Guidance
Mar 03, 2025



Recently, trimap-free methods have drawn increasing attention in human video matting due to their promising performance. Nevertheless, these methods still suffer from the lack of deterministic foreground-background cues, which impairs their ability to consistently identify and locate foreground targets over time and mine fine-grained details. In this paper, we present a trimap-free Object-Aware Video Matting (OAVM) framework, which can perceive different objects, enabling joint recognition of foreground objects and refinement of edge details. Specifically, we propose an Object-Guided Correction and Refinement (OGCR) module, which employs cross-frame guidance to aggregate object-level instance information into pixel-level detail features, thereby promoting their synergy. Furthermore, we design a Sequential Foreground Merging augmentation strategy to diversify sequential scenarios and enhance capacity of the network for object discrimination. Extensive experiments on recent widely used synthetic and real-world benchmarks demonstrate the state-of-the-art performance of our OAVM with only an initial coarse mask. The code and model will be available.
Few-Shot Object Detection: Research Advances and Challenges
Apr 07, 2024



Object detection as a subfield within computer vision has achieved remarkable progress, which aims to accurately identify and locate a specific object from images or videos. Such methods rely on large-scale labeled training samples for each object category to ensure accurate detection, but obtaining extensive annotated data is a labor-intensive and expensive process in many real-world scenarios. To tackle this challenge, researchers have explored few-shot object detection (FSOD) that combines few-shot learning and object detection techniques to rapidly adapt to novel objects with limited annotated samples. This paper presents a comprehensive survey to review the significant advancements in the field of FSOD in recent years and summarize the existing challenges and solutions. Specifically, we first introduce the background and definition of FSOD to emphasize potential value in advancing the field of computer vision. We then propose a novel FSOD taxonomy method and survey the plentifully remarkable FSOD algorithms based on this fact to report a comprehensive overview that facilitates a deeper understanding of the FSOD problem and the development of innovative solutions. Finally, we discuss the advantages and limitations of these algorithms to summarize the challenges, potential research direction, and development trend of object detection in the data scarcity scenario.
Adaptive Semantic Consistency for Cross-domain Few-shot Classification
Aug 01, 2023Cross-domain few-shot classification (CD-FSC) aims to identify novel target classes with a few samples, assuming that there exists a domain shift between source and target domains. Existing state-of-the-art practices typically pre-train on source domain and then finetune on the few-shot target data to yield task-adaptive representations. Despite promising progress, these methods are prone to overfitting the limited target distribution since data-scarcity and ignore the transferable knowledge learned in the source domain. To alleviate this problem, we propose a simple plug-and-play Adaptive Semantic Consistency (ASC) framework, which improves cross-domain robustness by preserving source transfer capability during the finetuning stage. Concretely, we reuse the source images in the pretraining phase and design an adaptive weight assignment strategy to highlight the samples similar to target domain, aiming to aggregate informative target-related knowledge from source domain. Subsequently, a semantic consistency regularization is applied to constrain the consistency between the semantic features of the source images output by the source model and target model. In this way, the proposed ASC enables explicit transfer of source domain knowledge to prevent the model from overfitting the target domain. Extensive experiments on multiple benchmarks demonstrate the effectiveness of the proposed ASC, and ASC provides consistent improvements over the baselines. The source code will be released.
Context-aware Proposal Network for Temporal Action Detection
Jun 18, 2022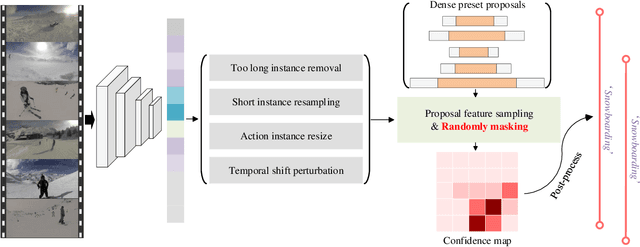
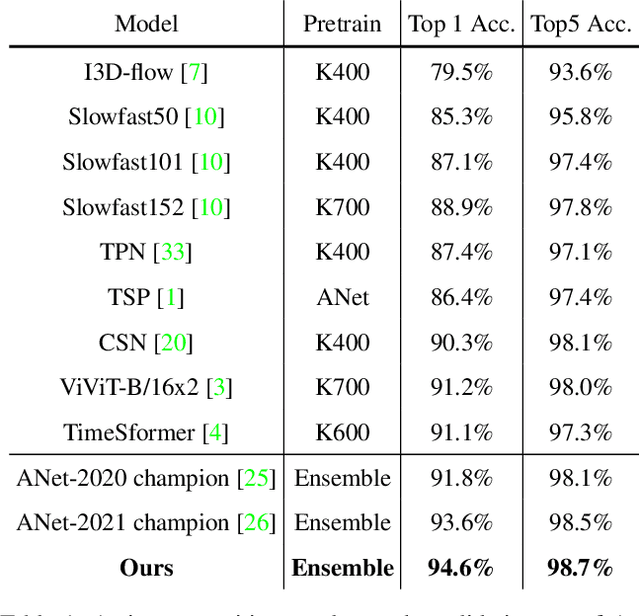

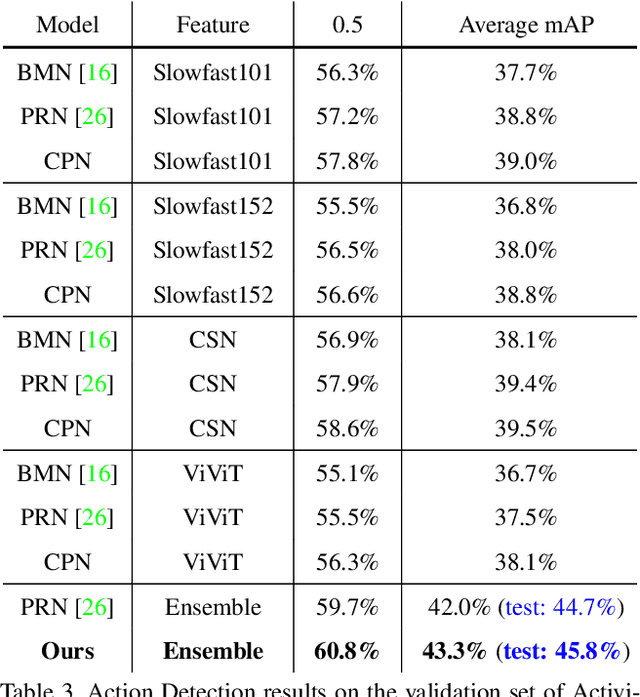
This technical report presents our first place winning solution for temporal action detection task in CVPR-2022 AcitivityNet Challenge. The task aims to localize temporal boundaries of action instances with specific classes in long untrimmed videos. Recent mainstream attempts are based on dense boundary matchings and enumerate all possible combinations to produce proposals. We argue that the generated proposals contain rich contextual information, which may benefits detection confidence prediction. To this end, our method mainly consists of the following three steps: 1) action classification and feature extraction by Slowfast, CSN, TimeSformer, TSP, I3D-flow, VGGish-audio, TPN and ViViT; 2) proposal generation. Our proposed Context-aware Proposal Network (CPN) builds on top of BMN, GTAD and PRN to aggregate contextual information by randomly masking some proposal features. 3) action detection. The final detection prediction is calculated by assigning the proposals with corresponding video-level classifcation results. Finally, we ensemble the results under different feature combination settings and achieve 45.8% performance on the test set, which improves the champion result in CVPR-2021 ActivityNet Challenge by 1.1% in terms of average mAP.
Multi-Centroid Representation Network for Domain Adaptive Person Re-ID
Dec 22, 2021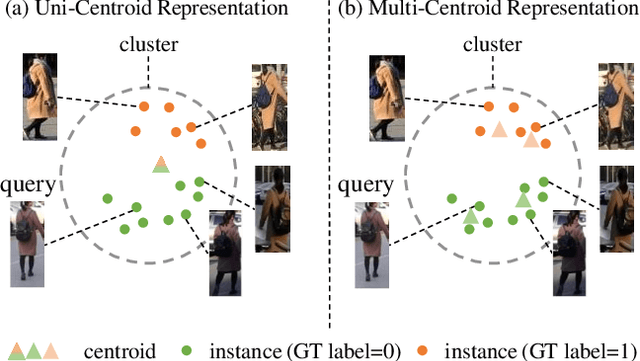
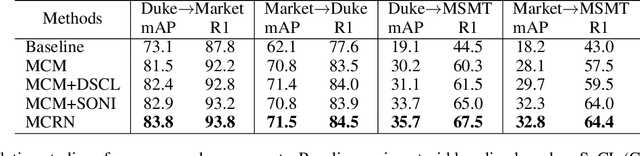
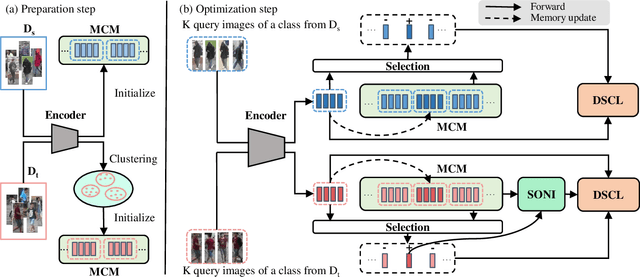
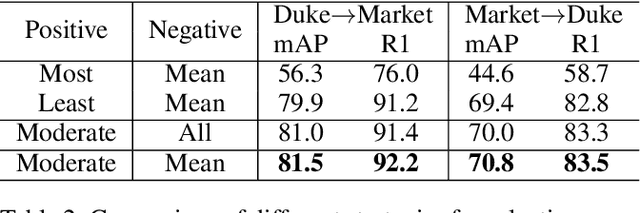
Recently, many approaches tackle the Unsupervised Domain Adaptive person re-identification (UDA re-ID) problem through pseudo-label-based contrastive learning. During training, a uni-centroid representation is obtained by simply averaging all the instance features from a cluster with the same pseudo label. However, a cluster may contain images with different identities (label noises) due to the imperfect clustering results, which makes the uni-centroid representation inappropriate. In this paper, we present a novel Multi-Centroid Memory (MCM) to adaptively capture different identity information within the cluster. MCM can effectively alleviate the issue of label noises by selecting proper positive/negative centroids for the query image. Moreover, we further propose two strategies to improve the contrastive learning process. First, we present a Domain-Specific Contrastive Learning (DSCL) mechanism to fully explore intradomain information by comparing samples only from the same domain. Second, we propose Second-Order Nearest Interpolation (SONI) to obtain abundant and informative negative samples. We integrate MCM, DSCL, and SONI into a unified framework named Multi-Centroid Representation Network (MCRN). Extensive experiments demonstrate the superiority of MCRN over state-of-the-art approaches on multiple UDA re-ID tasks and fully unsupervised re-ID tasks.
Unsupervised Low-Light Image Enhancement via Histogram Equalization Prior
Dec 03, 2021

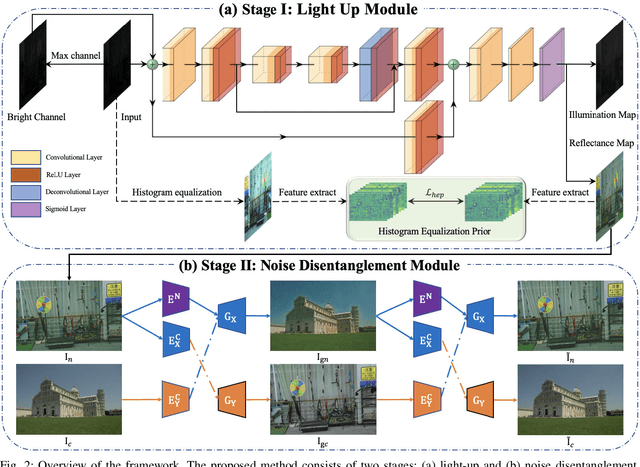

Deep learning-based methods for low-light image enhancement typically require enormous paired training data, which are impractical to capture in real-world scenarios. Recently, unsupervised approaches have been explored to eliminate the reliance on paired training data. However, they perform erratically in diverse real-world scenarios due to the absence of priors. To address this issue, we propose an unsupervised low-light image enhancement method based on an effective prior termed histogram equalization prior (HEP). Our work is inspired by the interesting observation that the feature maps of histogram equalization enhanced image and the ground truth are similar. Specifically, we formulate the HEP to provide abundant texture and luminance information. Embedded into a Light Up Module (LUM), it helps to decompose the low-light images into illumination and reflectance maps, and the reflectance maps can be regarded as restored images. However, the derivation based on Retinex theory reveals that the reflectance maps are contaminated by noise. We introduce a Noise Disentanglement Module (NDM) to disentangle the noise and content in the reflectance maps with the reliable aid of unpaired clean images. Guided by the histogram equalization prior and noise disentanglement, our method can recover finer details and is more capable to suppress noise in real-world low-light scenarios. Extensive experiments demonstrate that our method performs favorably against the state-of-the-art unsupervised low-light enhancement algorithms and even matches the state-of-the-art supervised algorithms.