 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Unpaired Image Dehazing with Physics-based Rehazy Generation
Jun 15, 2025
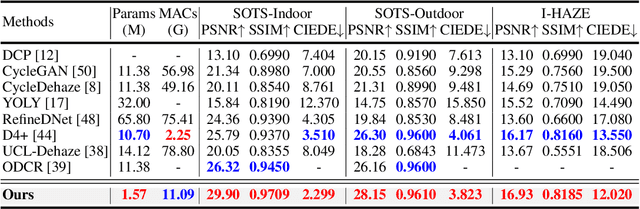
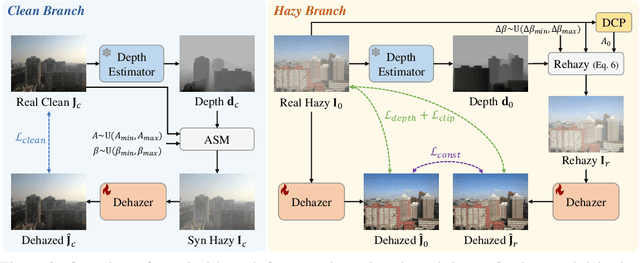
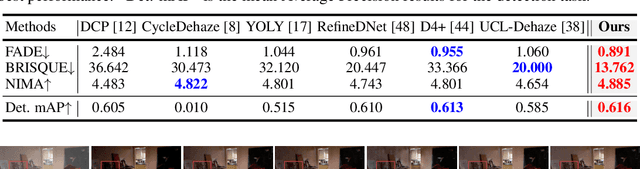
Overfitting to synthetic training pairs remains a critical challenge in image dehazing, leading to poor generalization capability to real-world scenarios. To address this issue, existing approaches utilize unpaired realistic data for training, employing CycleGAN or contrastive learning frameworks. Despite their progress, these methods often suffer from training instability, resulting in limited dehazing performance. In this paper, we propose a novel training strategy for unpaired image dehazing, termed Rehazy, to improve both dehazing performance and training stability. This strategy explores the consistency of the underlying clean images across hazy images and utilizes hazy-rehazy pairs for effective learning of real haze characteristics. To favorably construct hazy-rehazy pairs, we develop a physics-based rehazy generation pipeline, which is theoretically validated to reliably produce high-quality rehazy images. Additionally, leveraging the rehazy strategy, we introduce a dual-branch framework for dehazing network training, where a clean branch provides a basic dehazing capability in a synthetic manner, and a hazy branch enhances the generalization ability with hazy-rehazy pairs. Moreover, we design a new dehazing network within these branches to improve the efficiency, which progressively restores clean scenes from coarse to fine. Extensive experiments on four benchmarks demonstrate the superior performance of our approach, exceeding the previous state-of-the-art methods by 3.58 dB on the SOTS-Indoor dataset and by 1.85 dB on the SOTS-Outdoor dataset in PSNR. Our code will be publicly available.
Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time
Sep 30, 2020



Recent years have witnessed the increasing popularity of learning based methods to enhance the color and tone of photos. However, many existing photo enhancement methods either deliver unsatisfactory results or consume too much computational and memory resources, hindering their application to high-resolution images (usually with more than 12 megapixels) in practice. In this paper, we learn image-adaptive 3-dimensional lookup tables (3D LUTs) to achieve fast and robust photo enhancement. 3D LUTs are widely used for manipulating color and tone of photos, but they are usually manually tuned and fixed in camera imaging pipeline or photo editing tools. We, for the first time to our best knowledge, propose to learn 3D LUTs from annotated data using pairwise or unpaired learning. More importantly, our learned 3D LUT is image-adaptive for flexible photo enhancement. We learn multiple basis 3D LUTs and a small convolutional neural network (CNN) simultaneously in an end-to-end manner. The small CNN works on the down-sampled version of the input image to predict content-dependent weights to fuse the multiple basis 3D LUTs into an image-adaptive one, which is employed to transform the color and tone of source images efficiently. Our model contains less than 600K parameters and takes less than 2 ms to process an image of 4K resolution using one Titan RTX GPU. While being highly efficient, our model also outperforms the state-of-the-art photo enhancement methods by a large margin in terms of PSNR, SSIM and a color difference metric on two publically available benchmark datasets.
Grid Anchor based Image Cropping: A New Benchmark and An Efficient Model
Sep 18, 2019



Image cropping aims to improve the composition as well as aesthetic quality of an image by removing extraneous content from it. Most of the existing image cropping databases provide only one or several human-annotated bounding boxes as the groundtruths, which can hardly reflect the non-uniqueness and flexibility of image cropping in practice. The employed evaluation metrics such as intersection-over-union cannot reliably reflect the real performance of a cropping model, either. This work revisits the problem of image cropping, and presents a grid anchor based formulation by considering the special properties and requirements (e.g., local redundancy, content preservation, aspect ratio) of image cropping. Our formulation reduces the searching space of candidate crops from millions to no more than ninety. Consequently, a grid anchor based cropping benchmark is constructed, where all crops of each image are annotated and more reliable evaluation metrics are defined. To meet the practical demands of robust performance and high efficiency, we also design an effective and lightweight cropping model. By simultaneously considering the region of interest and region of discard, and leveraging multi-scale information, our model can robustly output visually pleasing crops for images of different scenes. With less than 2.5M parameters, our model runs at a speed of 200 FPS on one single GTX 1080Ti GPU and 12 FPS on one i7-6800K CPU. The code is available at: \url{https://github.com/HuiZeng/Grid-Anchor-based-Image-Cropping-Pytorch}.
CameraNet: A Two-Stage Framework for Effective Camera ISP Learning
Aug 08, 2019



Traditional image signal processing (ISP) pipeline consists of a set of individual image processing components onboard a camera to reconstruct a high-quality sRGB image from the sensor raw data. Due to the hand-crafted nature of the ISP components, traditional ISP pipeline has limited reconstruction quality under challenging scenes. Recently, the convolutional neural networks (CNNs) have demonstrated their competitiveness in solving many individual image processing problems, such as image denoising, demosaicking, white balance and contrast enhancement. However, it remains a question whether a CNN model can address the multiple tasks inside an ISP pipeline simultaneously. We make a good attempt along this line and propose a novel framework, which we call CameraNet, for effective and general ISP pipeline learning. The CameraNet is composed of two CNN modules to account for two sets of relatively uncorrelated subtasks in an ISP pipeline: restoration and enhancement. To train the two-stage CameraNet model, we specify two groundtruths that can be easily created in the common workflow of photography. CameraNet is trained to progressively address the restoration and the enhancement subtasks with its two modules. Experiments show that the proposed CameraNet achieves consistently compelling reconstruction quality on three benchmark datasets and outperforms traditional ISP pipelines.
Reliable and Efficient Image Cropping: A Grid Anchor based Approach
Apr 09, 2019



Image cropping aims to improve the composition as well as aesthetic quality of an image by removing extraneous content from it. Existing image cropping databases provide only one or several human-annotated bounding boxes as the groundtruth, which cannot reflect the non-uniqueness and flexibility of image cropping in practice. The employed evaluation metrics such as intersection-over-union cannot reliably reflect the real performance of cropping models, either. This work revisits the problem of image cropping, and presents a grid anchor based formulation by considering the special properties and requirements (e.g., local redundancy, content preservation, aspect ratio) of image cropping. Our formulation reduces the searching space of candidate crops from millions to less than one hundred. Consequently, a grid anchor based cropping benchmark is constructed, where all crops of each image are annotated and more reliable evaluation metrics are defined. We also design an effective and lightweight network module, which simultaneously considers the region of interest and region of discard for more accurate image cropping. Our model can stably output visually pleasing crops for images of different scenes and run at a speed of 125 FPS. Code and dataset are available at: https://github.com/HuiZeng/Grid-Anchor-based-Image-Cropping.
Toward Real-World Single Image Super-Resolution: A New Benchmark and A New Model
Apr 01, 2019

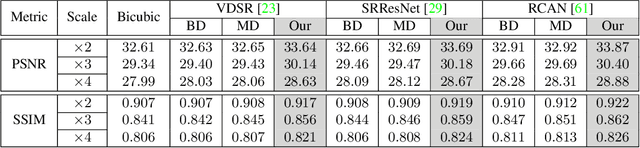
Most of the existing learning-based single image superresolution (SISR) methods are trained and evaluated on simulated datasets, where the low-resolution (LR) images are generated by applying a simple and uniform degradation (i.e., bicubic downsampling) to their high-resolution (HR) counterparts. However, the degradations in real-world LR images are far more complicated. As a consequence, the SISR models trained on simulated data become less effective when applied to practical scenarios. In this paper, we build a real-world super-resolution (RealSR) dataset where paired LR-HR images on the same scene are captured by adjusting the focal length of a digital camera. An image registration algorithm is developed to progressively align the image pairs at different resolutions. Considering that the degradation kernels are naturally non-uniform in our dataset, we present a Laplacian pyramid based kernel prediction network (LP-KPN), which efficiently learns per-pixel kernels to recover the HR image. Our extensive experiments demonstrate that SISR models trained on our RealSR dataset deliver better visual quality with sharper edges and finer textures on real-world scenes than those trained on simulated datasets. Though our RealSR dataset is built by using only two cameras (Canon 5D3 and Nikon D810), the trained model generalizes well to other camera devices such as Sony a7II and mobile phones.
Learning a Single Tucker Decomposition Network for Lossy Image Compression with Multiple Bits-Per-Pixel Rates
Jul 10, 2018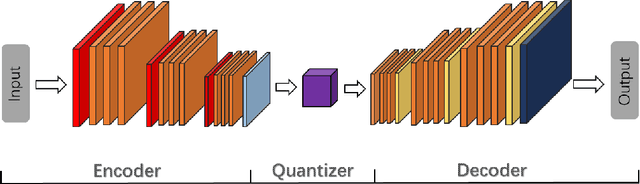
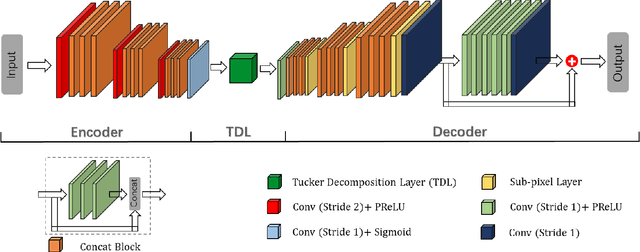
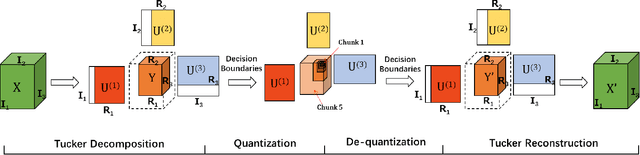

Lossy image compression (LIC), which aims to utilize inexact approximations to represent an image more compactly, is a classical problem in image processing. Recently, deep convolutional neural networks (CNNs) have achieved interesting results in LIC by learning an encoder-quantizer-decoder network from a large amount of data. However, existing CNN-based LIC methods usually can only train a network for a specific bits-per-pixel (bpp). Such a "one network per bpp" problem limits the generality and flexibility of CNNs to practical LIC applications. In this paper, we propose to learn a single CNN which can perform LIC at multiple bpp rates. A simple yet effective Tucker Decomposition Network (TDNet) is developed, where there is a novel tucker decomposition layer (TDL) to decompose a latent image representation into a set of projection matrices and a core tensor. By changing the rank of the core tensor and its quantization, we can easily adjust the bpp rate of latent image representation within a single CNN. Furthermore, an iterative non-uniform quantization scheme is presented to optimize the quantizer, and a coarse-to-fine training strategy is introduced to reconstruct the decompressed images. Extensive experiments demonstrate the state-of-the-art compression performance of TDNet in terms of both PSNR and MS-SSIM indices.