 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGD with Partial Hessian for Deep Neural Networks Optimization
Mar 05, 2024Due to the effectiveness of second-order algorithms in solving classical optimization problems, designing second-order optimizers to train deep neural networks (DNNs) has attracted much research interest in recent years. However, because of the very high dimension of intermediate features in DNNs, it is difficult to directly compute and store the Hessian matrix for network optimization. Most of the previous second-order methods approximate the Hessian information imprecisely, resulting in unstable performance. In this work, we propose a compound optimizer, which is a combination of a second-order optimizer with a precise partial Hessian matrix for updating channel-wise parameters and the first-order stochastic gradient descent (SGD) optimizer for updating the other parameters. We show that the associated Hessian matrices of channel-wise parameters are diagonal and can be extracted directly and precisely from Hessian-free methods. The proposed method, namely SGD with Partial Hessian (SGD-PH), inherits the advantages of both first-order and second-order optimizers. Compared with first-order optimizers, it adopts a certain amount of information from the Hessian matrix to assist optimization, while compared with the existing second-order optimizers, it keeps the good generalization performance of first-order optimizers. Experiments on image classification tasks demonstrate the effectiveness of our proposed optimizer SGD-PH. The code is publicly available at \url{https://github.com/myingysun/SGDPH}.
Improving the Stability of Diffusion Models for Content Consistent Super-Resolution
Dec 30, 2023



The generative priors of pre-trained latent diffusion models have demonstrated great potential to enhance the perceptual quality of image super-resolution (SR) results. Unfortunately, the existing diffusion prior-based SR methods encounter a common problem, i.e., they tend to generate rather different outputs for the same low-resolution image with different noise samples. Such stochasticity is desired for text-to-image generation tasks but problematic for SR tasks, where the image contents are expected to be well preserved. To improve the stability of diffusion prior-based SR, we propose to employ the diffusion models to refine image structures, while employing the generative adversarial training to enhance image fine details. Specifically, we propose a non-uniform timestep learning strategy to train a compact diffusion network, which has high efficiency and stability to reproduce the image main structures, and finetune the pre-trained decoder of variational auto-encoder (VAE) by adversarial training for detail enhancement. Extensive experiments show that our proposed method, namely content consistent super-resolution (CCSR), can significantly reduce the stochasticity of diffusion prior-based SR, improving the content consistency of SR outputs and speeding up the image generation process. Codes and models can be found at {https://github.com/csslc/CCSR}.
Perception-Distortion Balanced Super-Resolution: A Multi-Objective Optimization Perspective
Dec 24, 2023High perceptual quality and low distortion degree are two important goals in image restoration tasks such as super-resolution (SR). Most of the existing SR methods aim to achieve these goals by minimizing the corresponding yet conflicting losses, such as the $\ell_1$ loss and the adversarial loss. Unfortunately, the commonly used gradient-based optimizers, such as Adam, are hard to balance these objectives due to the opposite gradient decent directions of the contradictory losses. In this paper, we formulate the perception-distortion trade-off in SR as a multi-objective optimization problem and develop a new optimizer by integrating the gradient-free evolutionary algorithm (EA) with gradient-based Adam, where EA and Adam focus on the divergence and convergence of the optimization directions respectively. As a result, a population of optimal models with different perception-distortion preferences is obtained. We then design a fusion network to merge these models into a single stronger one for an effective perception-distortion trade-off. Experiments demonstrate that with the same backbone network, the perception-distortion balanced SR model trained by our method can achieve better perceptual quality than its competitors while attaining better reconstruction fidelity. Codes and models can be found at https://github.com/csslc/EA-Adam.
Spatial-Frequency Attention for Image Denoising
Feb 27, 2023The recently developed transformer networks have achieved impressive performance in image denoising by exploiting the self-attention (SA) in images. However, the existing methods mostly use a relatively small window to compute SA due to the quadratic complexity of it, which limits the model's ability to model long-term image information. In this paper, we propose the spatial-frequency attention network (SFANet) to enhance the network's ability in exploiting long-range dependency. For spatial attention module (SAM), we adopt dilated SA to model long-range dependency. In the frequency attention module (FAM), we exploit more global information by using Fast Fourier Transform (FFT) by designing a window-based frequency channel attention (WFCA) block to effectively model deep frequency features and their dependencies. To make our module applicable to images of different sizes and keep the model consistency between training and inference, we apply window-based FFT with a set of fixed window sizes. In addition, channel attention is computed on both real and imaginary parts of the Fourier spectrum, which further improves restoration performance. The proposed WFCA block can effectively model image long-range dependency with acceptable complexity. Experiments on multiple denoising benchmarks demonstrate the leading performance of SFANet network.
Unfolded Deep Kernel Estimation for Blind Image Super-resolution
Mar 10, 2022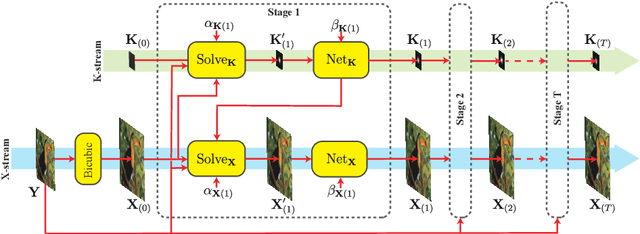
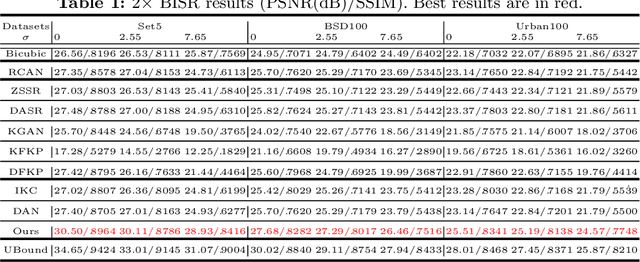

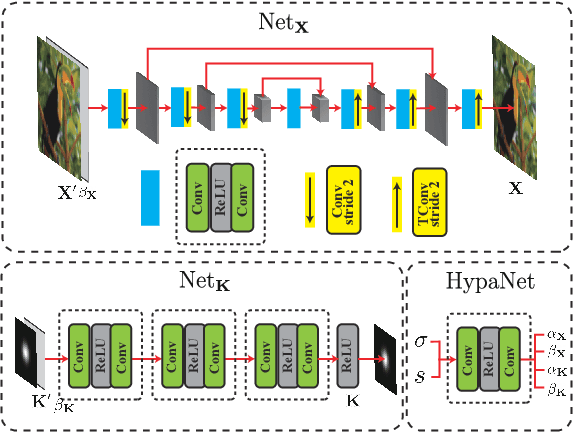
Blind image super-resolution (BISR) aims to reconstruct a high-resolution image from its low-resolution counterpart degraded by unknown blur kernel and noise. Many deep neural network based methods have been proposed to tackle this challenging problem without considering the image degradation model. However, they largely rely on the training sets and often fail to handle images with unseen blur kernels during inference. Deep unfolding methods have also been proposed to perform BISR by utilizing the degradation model. Nonetheless, the existing deep unfolding methods cannot explicitly solve the data term of the unfolding objective function, limiting their capability in blur kernel estimation. In this work, we propose a novel unfolded deep kernel estimation (UDKE) method, which, for the first time to our best knowledge, explicitly solves the data term with high efficiency. The UDKE based BISR method can jointly learn image and kernel priors in an end-to-end manner, and it can effectively exploit the information in both training data and image degradation model. Experiments on benchmark datasets and real-world data demonstrate that the proposed UDKE method could well predict complex unseen non-Gaussian blur kernels in inference, achieving significantly better BISR performance than state-of-the-art. The source code of UDKE is available at: https://github.com/natezhenghy/UDKE.
Variational Image Restoration Network
Aug 25, 2020
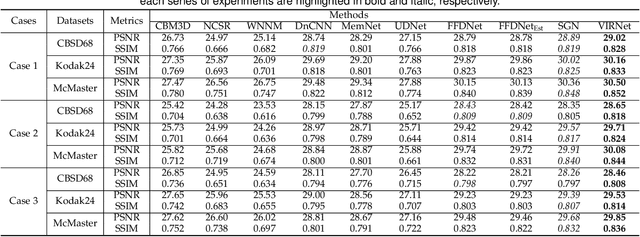
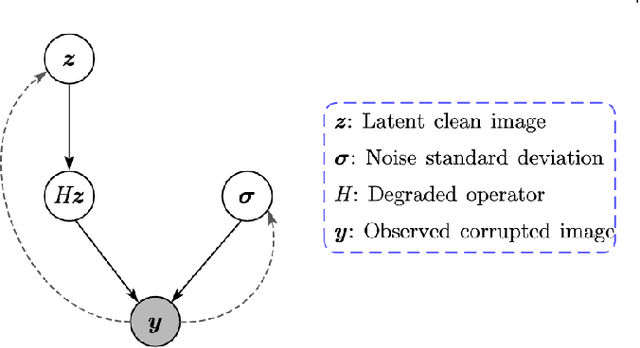
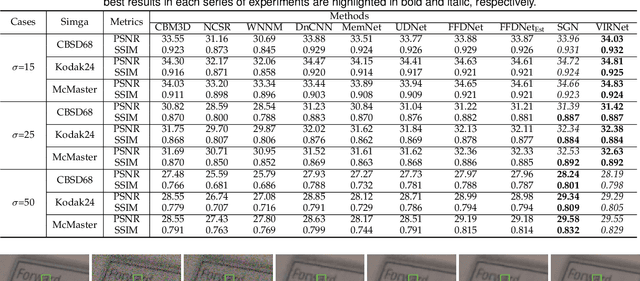
Deep neural networks (DNNs) have achieved significant success in image restoration tasks by directly learning a powerful non-linear mapping from corrupted images to their latent clean ones. However, there still exist two major limitations for these deep learning (DL)-based methods. Firstly, the noises contained in real corrupted images are very complex, usually neglected and largely under-estimated in most current methods. Secondly, existing DL methods are mostly trained on one pre-assumed degradation process for all of the training image pairs, such as the widely used bicubic downsampling assumption in the image super-resolution task, inevitably leading to poor generalization performance when the true degradation does not match with such assumed one. To address these issues, we propose a unified generative model for the image restoration, which elaborately configures the degradation process from the latent clean image to the observed corrupted one. Specifically, different from most of current methods, the pixel-wisely non-i.i.d. Gaussian distribution, being with more flexibility, is adopted in our method to fit the complex real noises. Furthermore, the method is built on the general image degradation process, making it capable of adapting diverse degradations under one single model. Besides, we design a variational inference algorithm to learn all parameters involved in the proposed model with explicit form of objective loss. Specifically, beyond traditional variational methodology, two DNNs are employed to parameterize the posteriori distributions, one to infer the distribution of the latent clean image, and another to infer the distribution of the image noise. Extensive experiments demonstrate the superiority of the proposed method on three classical image restoration tasks, including image denoising, image super-resolution and JPEG image deblocking.
Gradient Centralization: A New Optimization Technique for Deep Neural Networks
Apr 08, 2020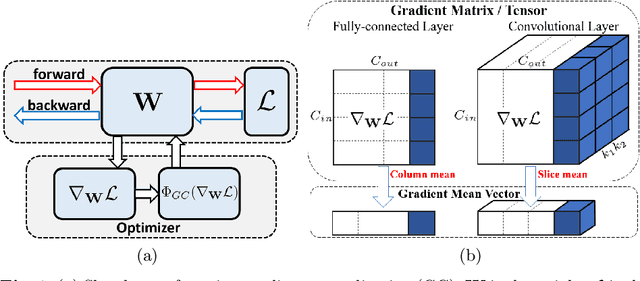
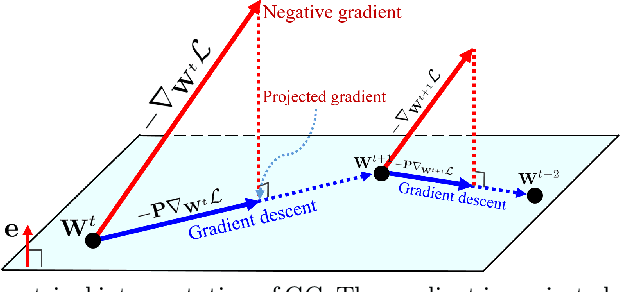

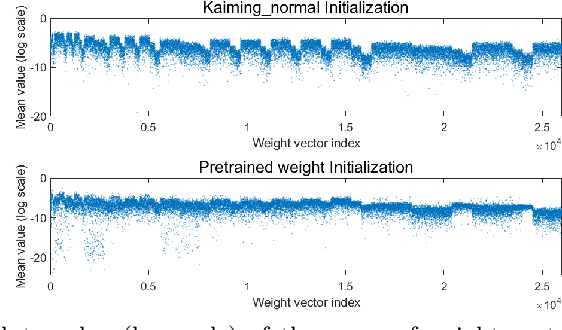
Optimization techniques are of great importance to effectively and efficiently train a deep neural network (DNN). It has been shown that using the first and second order statistics (e.g., mean and variance) to perform Z-score standardization on network activations or weight vectors, such as batch normalization (BN) and weight standardization (WS), can improve the training performance. Different from these existing methods that mostly operate on activations or weights, we present a new optimization technique, namely gradient centralization (GC), which operates directly on gradients by centralizing the gradient vectors to have zero mean. GC can be viewed as a projected gradient descent method with a constrained loss function. We show that GC can regularize both the weight space and output feature space so that it can boost the generalization performance of DNNs. Moreover, GC improves the Lipschitzness of the loss function and its gradient so that the training process becomes more efficient and stable. GC is very simple to implement and can be easily embedded into existing gradient based DNN optimizers with only one line of code. It can also be directly used to fine-tune the pre-trained DNNs. Our experiments on various applications, including general image classification, fine-grained image classification, detection and segmentation, demonstrate that GC can consistently improve the performance of DNN learning. The code of GC can be found at https://github.com/Yonghongwei/Gradient-Centralization.
Variational Denoising Network: Toward Blind Noise Modeling and Removal
Sep 23, 2019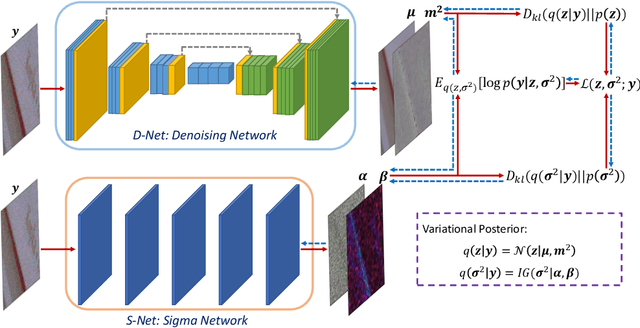
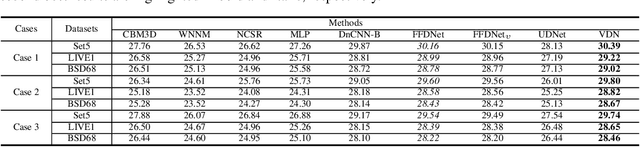
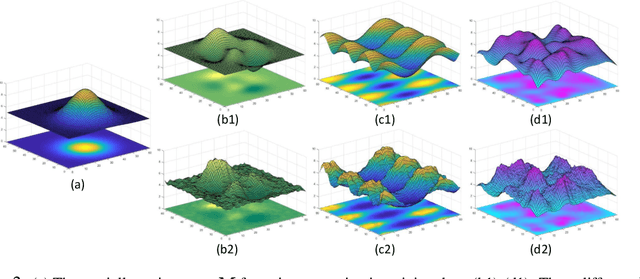
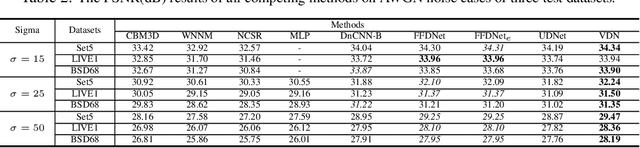
Blind image denoising is an important yet very challenging problem in computer vision due to the complicated acquisition process of real images. In this work we propose a new variational inference method, which integrates both noise estimation and image denoising into a unique Bayesian framework, for blind image denoising. Specifically, an approximate posterior, parameterized by deep neural networks, is presented by taking the intrinsic clean image and noise variances as latent variables conditioned on the input noisy image. This posterior provides explicit parametric forms for all its involved hyper-parameters, and thus can be easily implemented for blind image denoising with automatic noise estimation for the test noisy image. On one hand, as other data-driven deep learning methods, our method, namely variational denoising network (VDN), can perform denoising efficiently due to its explicit form of posterior expression. On the other hand, VDN inherits the advantages of traditional model-driven approaches, especially the good generalization capability of generative models. VDN has good interpretability and can be flexibly utilized to estimate and remove complicated non-i.i.d. noise collected in real scenarios. Comprehensive experiments are performed to substantiate the superiority of our method in blind image denoising.
Toward Real-World Single Image Super-Resolution: A New Benchmark and A New Model
Apr 01, 2019

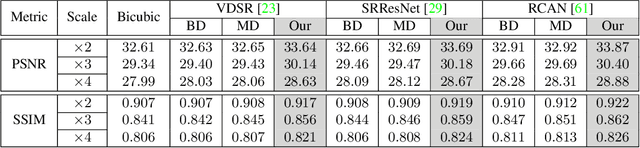
Most of the existing learning-based single image superresolution (SISR) methods are trained and evaluated on simulated datasets, where the low-resolution (LR) images are generated by applying a simple and uniform degradation (i.e., bicubic downsampling) to their high-resolution (HR) counterparts. However, the degradations in real-world LR images are far more complicated. As a consequence, the SISR models trained on simulated data become less effective when applied to practical scenarios. In this paper, we build a real-world super-resolution (RealSR) dataset where paired LR-HR images on the same scene are captured by adjusting the focal length of a digital camera. An image registration algorithm is developed to progressively align the image pairs at different resolutions. Considering that the degradation kernels are naturally non-uniform in our dataset, we present a Laplacian pyramid based kernel prediction network (LP-KPN), which efficiently learns per-pixel kernels to recover the HR image. Our extensive experiments demonstrate that SISR models trained on our RealSR dataset deliver better visual quality with sharper edges and finer textures on real-world scenes than those trained on simulated datasets. Though our RealSR dataset is built by using only two cameras (Canon 5D3 and Nikon D810), the trained model generalizes well to other camera devices such as Sony a7II and mobile phones.
Model Inconsistent but Correlated Noise: Multi-view Subspace Learning with Regularized Mixture of Gaussians
Nov 07, 2018
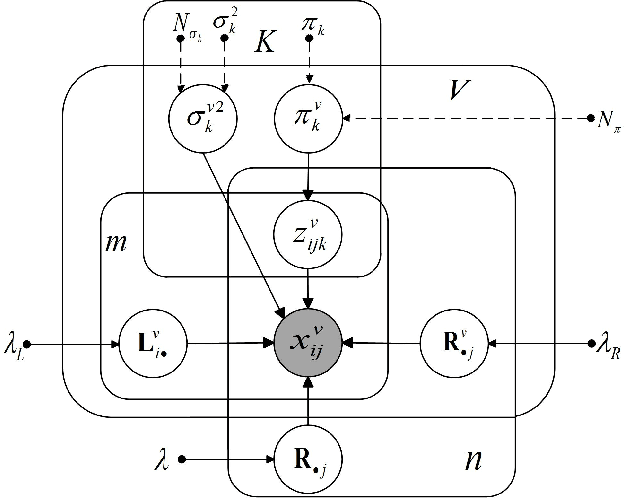
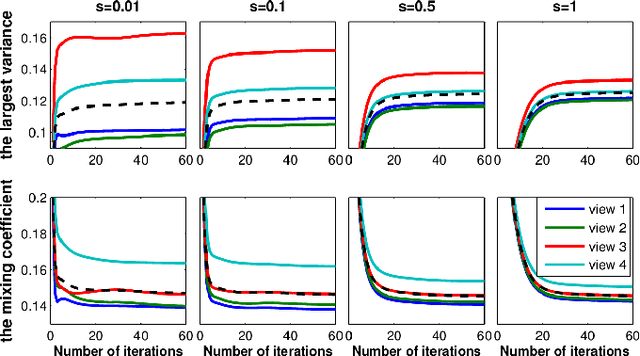
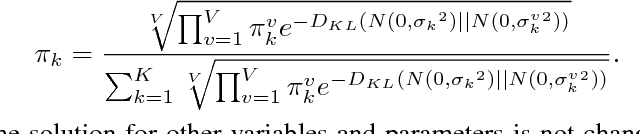
Multi-view subspace learning (MSL) aims to find a low-dimensional subspace of the data obtained from multiple views. Different from single view case, MSL should take both common and specific knowledge among different views into consideration. To enhance the robustness of model, the complexity, non-consistency and similarity of noise in multi-view data should be fully taken into consideration. Most current MSL methods only assume a simple Gaussian or Laplacian distribution for the noise while neglect the complex noise configurations in each view and noise correlations among different views of practical data. To this issue, this work initiates a MSL method by encoding the multi-view-shared and single-view-specific noise knowledge in data. Specifically, we model data noise in each view as a separated Mixture of Gaussians (MoG), which can fit a wider range of complex noise types than conventional Gaussian/Laplacian. Furthermore, we link all single-view-noise as a whole by regularizing them by a common MoG component, encoding the shared noise knowledge among them. Such regularization component can be formulated as a concise KL-divergence regularization term under a MAP framework, leading to good interpretation of our model and simple EM-based solving strategy to the problem. Experimental results substantiate the superiority of our method.