 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Exemplars Make Large Language Models More Robust: A Domain-Agnostic Behavioral Analysis
Nov 01, 2023Recent advances in prompt engineering enable large language models (LLMs) to solve multi-hop logical reasoning problems with impressive accuracy. However, there is little existing work investigating the robustness of LLMs with few-shot prompting techniques. Therefore, we introduce a systematic approach to test the robustness of LLMs in multi-hop reasoning tasks via domain-agnostic perturbations. We include perturbations at multiple levels of abstractions (e.g. lexical perturbations such as typos, and semantic perturbations such as the inclusion of intermediate reasoning steps in the questions) to conduct behavioral analysis on the LLMs. Throughout our experiments, we find that models are more sensitive to certain perturbations such as replacing words with their synonyms. We also demonstrate that increasing the proportion of perturbed exemplars in the prompts improves the robustness of few-shot prompting methods.
Making the Most Out of the Limited Context Length: Predictive Power Varies with Clinical Note Type and Note Section
Jul 13, 2023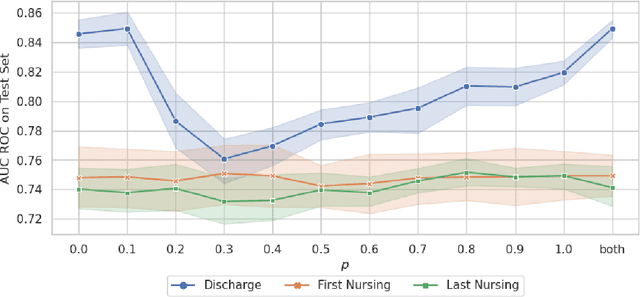
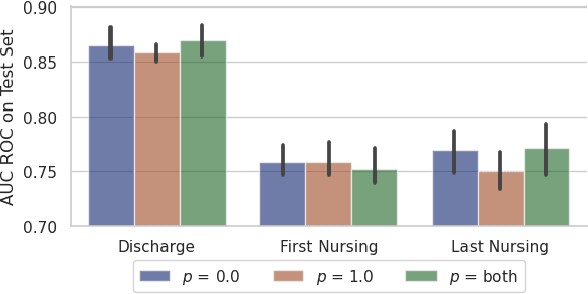
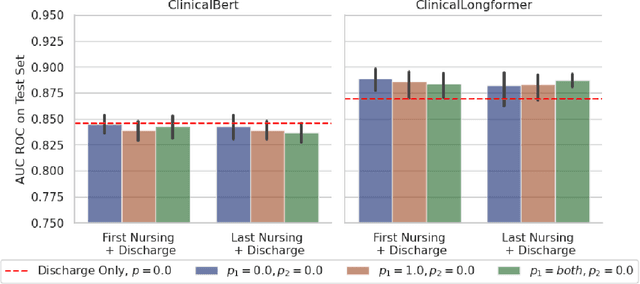
Recent advances in large language models have led to renewed interest in natural language processing in healthcare using the free text of clinical notes. One distinguishing characteristic of clinical notes is their long time span over multiple long documents. The unique structure of clinical notes creates a new design choice: when the context length for a language model predictor is limited, which part of clinical notes should we choose as the input? Existing studies either choose the inputs with domain knowledge or simply truncate them. We propose a framework to analyze the sections with high predictive power. Using MIMIC-III, we show that: 1) predictive power distribution is different between nursing notes and discharge notes and 2) combining different types of notes could improve performance when the context length is large. Our findings suggest that a carefully selected sampling function could enable more efficient information extraction from clinical notes.
* Our code is publicly available on GitHub (https://github.com/nyuolab/EfficientTransformer)
Predicting Blossom Date of Cherry Tree With Support Vector Machine and Recurrent Neural Network
Oct 10, 2022
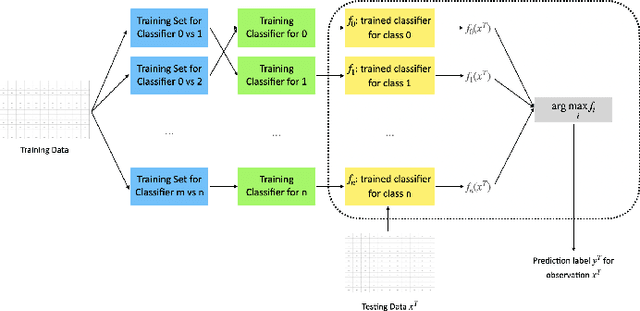
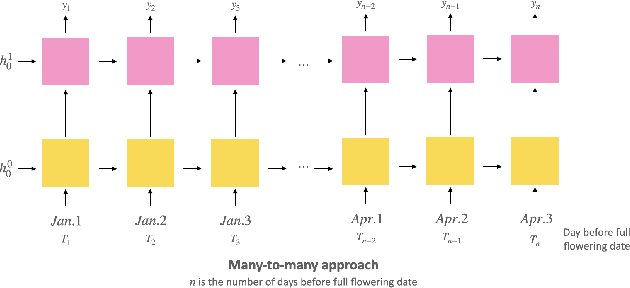
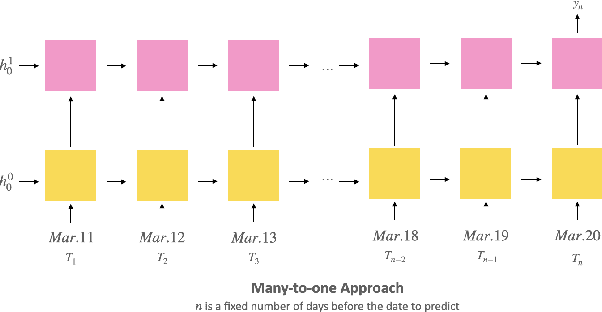
Our project probes the relationship between temperatures and the blossom date of cherry trees. Through modeling, future flowering will become predictive, helping the public plan travels and avoid pollen season. To predict the date when the cherry trees will blossom exactly could be viewed as a multiclass classification problem, so we applied the multi-class Support Vector Classifier (SVC) and Recurrent Neural Network (RNN), particularly Long Short-term Memory (LSTM), to formulate the problem. In the end, we evaluate and compare the performance of these approaches to find out which one might be more applicable in reality.
Unfolded Deep Kernel Estimation for Blind Image Super-resolution
Mar 10, 2022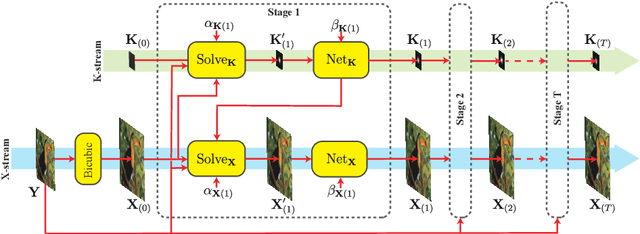
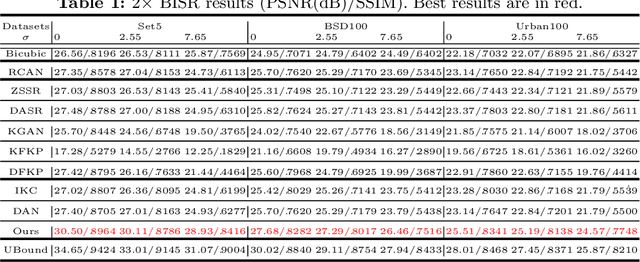

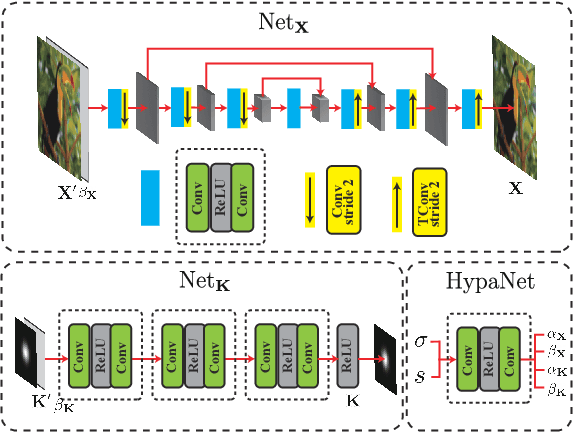
Blind image super-resolution (BISR) aims to reconstruct a high-resolution image from its low-resolution counterpart degraded by unknown blur kernel and noise. Many deep neural network based methods have been proposed to tackle this challenging problem without considering the image degradation model. However, they largely rely on the training sets and often fail to handle images with unseen blur kernels during inference. Deep unfolding methods have also been proposed to perform BISR by utilizing the degradation model. Nonetheless, the existing deep unfolding methods cannot explicitly solve the data term of the unfolding objective function, limiting their capability in blur kernel estimation. In this work, we propose a novel unfolded deep kernel estimation (UDKE) method, which, for the first time to our best knowledge, explicitly solves the data term with high efficiency. The UDKE based BISR method can jointly learn image and kernel priors in an end-to-end manner, and it can effectively exploit the information in both training data and image degradation model. Experiments on benchmark datasets and real-world data demonstrate that the proposed UDKE method could well predict complex unseen non-Gaussian blur kernels in inference, achieving significantly better BISR performance than state-of-the-art. The source code of UDKE is available at: https://github.com/natezhenghy/UDKE.