 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond External Guidance: Unleashing the Semantic Richness Inside Diffusion Transformers for Improved Training
Jan 12, 2026Recent works such as REPA have shown that guiding diffusion models with external semantic features (e.g., DINO) can significantly accelerate the training of diffusion transformers (DiTs). However, this requires the use of pretrained external networks, introducing additional dependencies and reducing flexibility. In this work, we argue that DiTs actually have the power to guide the training of themselves, and propose \textbf{Self-Transcendence}, a simple yet effective method that achieves fast convergence using internal feature supervision only. It is found that the slow convergence in DiT training primarily stems from the difficulty of representation learning in shallow layers. To address this, we initially train the DiT model by aligning its shallow features with the latent representations from the pretrained VAE for a short phase (e.g., 40 epochs), then apply classifier-free guidance to the intermediate features, enhancing their discriminative capability and semantic expressiveness. These enriched internal features, learned entirely within the model, are used as supervision signals to guide a new DiT training. Compared to existing self-contained methods, our approach brings a significant performance boost. It can even surpass REPA in terms of generation quality and convergence speed, but without the need for any external pretrained models. Our method is not only more flexible for different backbones but also has the potential to be adopted for a wider range of diffusion-based generative tasks. The source code of our method can be found at https://github.com/csslc/Self-Transcendence.
NSARM: Next-Scale Autoregressive Modeling for Robust Real-World Image Super-Resolution
Oct 01, 2025



Most recent real-world image super-resolution (Real-ISR) methods employ pre-trained text-to-image (T2I) diffusion models to synthesize the high-quality image either from random Gaussian noise, which yields realistic results but is slow due to iterative denoising, or directly from the input low-quality image, which is efficient but at the price of lower output quality. These approaches train ControlNet or LoRA modules while keeping the pre-trained model fixed, which often introduces over-enhanced artifacts and hallucinations, suffering from the robustness to inputs of varying degradations. Recent visual autoregressive (AR) models, such as pre-trained Infinity, can provide strong T2I generation capabilities while offering superior efficiency by using the bitwise next-scale prediction strategy. Building upon next-scale prediction, we introduce a robust Real-ISR framework, namely Next-Scale Autoregressive Modeling (NSARM). Specifically, we train NSARM in two stages: a transformation network is first trained to map the input low-quality image to preliminary scales, followed by an end-to-end full-model fine-tuning. Such a comprehensive fine-tuning enhances the robustness of NSARM in Real-ISR tasks without compromising its generative capability. Extensive quantitative and qualitative evaluations demonstrate that as a pure AR model, NSARM achieves superior visual results over existing Real-ISR methods while maintaining a fast inference speed. Most importantly, it demonstrates much higher robustness to the quality of input images, showing stronger generalization performance. Project page: https://github.com/Xiangtaokong/NSARM
One-Step Diffusion for Detail-Rich and Temporally Consistent Video Super-Resolution
Jun 18, 2025

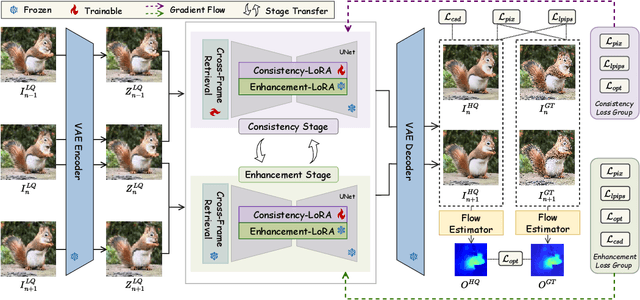

It is a challenging problem to reproduce rich spatial details while maintaining temporal consistency in real-world video super-resolution (Real-VSR), especially when we leverage pre-trained generative models such as stable diffusion (SD) for realistic details synthesis. Existing SD-based Real-VSR methods often compromise spatial details for temporal coherence, resulting in suboptimal visual quality. We argue that the key lies in how to effectively extract the degradation-robust temporal consistency priors from the low-quality (LQ) input video and enhance the video details while maintaining the extracted consistency priors. To achieve this, we propose a Dual LoRA Learning (DLoRAL) paradigm to train an effective SD-based one-step diffusion model, achieving realistic frame details and temporal consistency simultaneously. Specifically, we introduce a Cross-Frame Retrieval (CFR) module to aggregate complementary information across frames, and train a Consistency-LoRA (C-LoRA) to learn robust temporal representations from degraded inputs. After consistency learning, we fix the CFR and C-LoRA modules and train a Detail-LoRA (D-LoRA) to enhance spatial details while aligning with the temporal space defined by C-LoRA to keep temporal coherence. The two phases alternate iteratively for optimization, collaboratively delivering consistent and detail-rich outputs. During inference, the two LoRA branches are merged into the SD model, allowing efficient and high-quality video restoration in a single diffusion step. Experiments show that DLoRAL achieves strong performance in both accuracy and speed. Code and models are available at https://github.com/yjsunnn/DLoRAL.
InstructRestore: Region-Customized Image Restoration with Human Instructions
Mar 31, 2025



Despite the significant progress in diffusion prior-based image restoration, most existing methods apply uniform processing to the entire image, lacking the capability to perform region-customized image restoration according to user instructions. In this work, we propose a new framework, namely InstructRestore, to perform region-adjustable image restoration following human instructions. To achieve this, we first develop a data generation engine to produce training triplets, each consisting of a high-quality image, the target region description, and the corresponding region mask. With this engine and careful data screening, we construct a comprehensive dataset comprising 536,945 triplets to support the training and evaluation of this task. We then examine how to integrate the low-quality image features under the ControlNet architecture to adjust the degree of image details enhancement. Consequently, we develop a ControlNet-like model to identify the target region and allocate different integration scales to the target and surrounding regions, enabling region-customized image restoration that aligns with user instructions. Experimental results demonstrate that our proposed InstructRestore approach enables effective human-instructed image restoration, such as images with bokeh effects and user-instructed local enhancement. Our work advances the investigation of interactive image restoration and enhancement techniques. Data, code, and models will be found at https://github.com/shuaizhengliu/InstructRestore.git.
Perceive, Understand and Restore: Real-World Image Super-Resolution with Autoregressive Multimodal Generative Models
Mar 14, 2025



By leveraging the generative priors from pre-trained text-to-image diffusion models, significant progress has been made in real-world image super-resolution (Real-ISR). However, these methods tend to generate inaccurate and unnatural reconstructions in complex and/or heavily degraded scenes, primarily due to their limited perception and understanding capability of the input low-quality image. To address these limitations, we propose, for the first time to our knowledge, to adapt the pre-trained autoregressive multimodal model such as Lumina-mGPT into a robust Real-ISR model, namely PURE, which Perceives and Understands the input low-quality image, then REstores its high-quality counterpart. Specifically, we implement instruction tuning on Lumina-mGPT to perceive the image degradation level and the relationships between previously generated image tokens and the next token, understand the image content by generating image semantic descriptions, and consequently restore the image by generating high-quality image tokens autoregressively with the collected information. In addition, we reveal that the image token entropy reflects the image structure and present a entropy-based Top-k sampling strategy to optimize the local structure of the image during inference. Experimental results demonstrate that PURE preserves image content while generating realistic details, especially in complex scenes with multiple objects, showcasing the potential of autoregressive multimodal generative models for robust Real-ISR. The model and code will be available at https://github.com/nonwhy/PURE.
Pixel-level and Semantic-level Adjustable Super-resolution: A Dual-LoRA Approach
Dec 04, 2024



Diffusion prior-based methods have shown impressive results in real-world image super-resolution (SR). However, most existing methods entangle pixel-level and semantic-level SR objectives in the training process, struggling to balance pixel-wise fidelity and perceptual quality. Meanwhile, users have varying preferences on SR results, thus it is demanded to develop an adjustable SR model that can be tailored to different fidelity-perception preferences during inference without re-training. We present Pixel-level and Semantic-level Adjustable SR (PiSA-SR), which learns two LoRA modules upon the pre-trained stable-diffusion (SD) model to achieve improved and adjustable SR results. We first formulate the SD-based SR problem as learning the residual between the low-quality input and the high-quality output, then show that the learning objective can be decoupled into two distinct LoRA weight spaces: one is characterized by the $\ell_2$-loss for pixel-level regression, and another is characterized by the LPIPS and classifier score distillation losses to extract semantic information from pre-trained classification and SD models. In its default setting, PiSA-SR can be performed in a single diffusion step, achieving leading real-world SR results in both quality and efficiency. By introducing two adjustable guidance scales on the two LoRA modules to control the strengths of pixel-wise fidelity and semantic-level details during inference, PiSASR can offer flexible SR results according to user preference without re-training. Codes and models can be found at https://github.com/csslc/PiSA-SR.
NTIRE 2024 Restore Any Image Model in the Wild Challenge
May 16, 2024
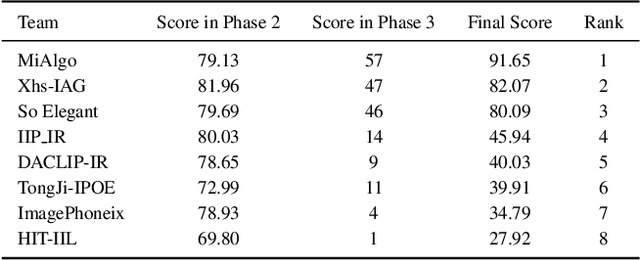

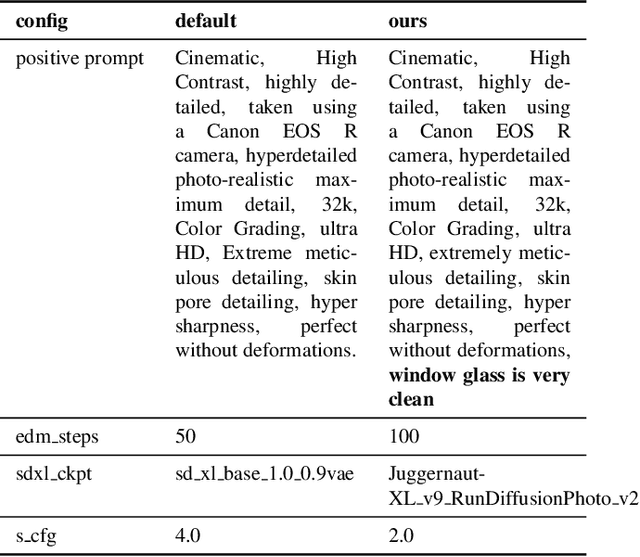
In this paper, we review the NTIRE 2024 challenge on Restore Any Image Model (RAIM) in the Wild. The RAIM challenge constructed a benchmark for image restoration in the wild, including real-world images with/without reference ground truth in various scenarios from real applications. The participants were required to restore the real-captured images from complex and unknown degradation, where generative perceptual quality and fidelity are desired in the restoration result. The challenge consisted of two tasks. Task one employed real referenced data pairs, where quantitative evaluation is available. Task two used unpaired images, and a comprehensive user study was conducted. The challenge attracted more than 200 registrations, where 39 of them submitted results with more than 400 submissions. Top-ranked methods improved the state-of-the-art restoration performance and obtained unanimous recognition from all 18 judges. The proposed datasets are available at https://drive.google.com/file/d/1DqbxUoiUqkAIkExu3jZAqoElr_nu1IXb/view?usp=sharing and the homepage of this challenge is at https://codalab.lisn.upsaclay.fr/competitions/17632.
Perception-Distortion Balanced Super-Resolution: A Multi-Objective Optimization Perspective
Dec 24, 2023High perceptual quality and low distortion degree are two important goals in image restoration tasks such as super-resolution (SR). Most of the existing SR methods aim to achieve these goals by minimizing the corresponding yet conflicting losses, such as the $\ell_1$ loss and the adversarial loss. Unfortunately, the commonly used gradient-based optimizers, such as Adam, are hard to balance these objectives due to the opposite gradient decent directions of the contradictory losses. In this paper, we formulate the perception-distortion trade-off in SR as a multi-objective optimization problem and develop a new optimizer by integrating the gradient-free evolutionary algorithm (EA) with gradient-based Adam, where EA and Adam focus on the divergence and convergence of the optimization directions respectively. As a result, a population of optimal models with different perception-distortion preferences is obtained. We then design a fusion network to merge these models into a single stronger one for an effective perception-distortion trade-off. Experiments demonstrate that with the same backbone network, the perception-distortion balanced SR model trained by our method can achieve better perceptual quality than its competitors while attaining better reconstruction fidelity. Codes and models can be found at https://github.com/csslc/EA-Adam.