 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialFlow-GRPO: Where Spatial Credit Drives Image Editing
Jun 25, 2026Recent online reinforcement learning has substantially improved image editing quality. However, existing Flow-GRPO-style methods usually rely on a single whole-image reward, which makes fine-grained editing optimization difficult. We observe that a key obstacle in image editing is this spatial uniformity assumption: a whole-image reward cannot distinguish how different spatial regions contribute to image quality. To address this issue, we propose SpatialFlow-GRPO, a training framework that introduces spatially fine-grained reward feedback. The framework converts region-aware rewards into semantic-region-level optimization signals and aligns region advantages with the corresponding latent positions during policy updates. We also train a region-aware reward model, SFReward, construct SFReward-14K with region-annotated editing samples, and introduce MultiEditBench to evaluate multi-region editing ability. On OmniGen2 and FLUX.2-klein-4B, SpatialFlow-GRPO outperforms Flow-GRPO on GEdit-Bench, ImgEdit-Bench, and MultiEditBench. The results show that SpatialFlow-GRPO converts local feedback into spatially aligned update signals and improves editing quality.
Learning Cross-View Object Correspondence via Cycle-Consistent Mask Prediction
Feb 22, 2026We study the task of establishing object-level visual correspondence across different viewpoints in videos, focusing on the challenging egocentric-to-exocentric and exocentric-to-egocentric scenarios. We propose a simple yet effective framework based on conditional binary segmentation, where an object query mask is encoded into a latent representation to guide the localization of the corresponding object in a target video. To encourage robust, view-invariant representations, we introduce a cycle-consistency training objective: the predicted mask in the target view is projected back to the source view to reconstruct the original query mask. This bidirectional constraint provides a strong self-supervisory signal without requiring ground-truth annotations and enables test-time training (TTT) at inference. Experiments on the Ego-Exo4D and HANDAL-X benchmarks demonstrate the effectiveness of our optimization objective and TTT strategy, achieving state-of-the-art performance. The code is available at https://github.com/shannany0606/CCMP.
UniRef-Image-Edit: Towards Scalable and Consistent Multi-Reference Image Editing
Feb 15, 2026We present UniRef-Image-Edit, a high-performance multi-modal generation system that unifies single-image editing and multi-image composition within a single framework. Existing diffusion-based editing methods often struggle to maintain consistency across multiple conditions due to limited interaction between reference inputs. To address this, we introduce Sequence-Extended Latent Fusion (SELF), a unified input representation that dynamically serializes multiple reference images into a coherent latent sequence. During a dedicated training stage, all reference images are jointly constrained to fit within a fixed-length sequence under a global pixel-budget constraint. Building upon SELF, we propose a two-stage training framework comprising supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we jointly train on single-image editing and multi-image composition tasks to establish a robust generative prior. We adopt a progressive sequence length training strategy, in which all input images are initially resized to a total pixel budget of $1024^2$, and are then gradually increased to $1536^2$ and $2048^2$ to improve visual fidelity and cross-reference consistency. This gradual relaxation of compression enables the model to incrementally capture finer visual details while maintaining stable alignment across references. For the RL stage, we introduce Multi-Source GRPO (MSGRPO), to our knowledge the first reinforcement learning framework tailored for multi-reference image generation. MSGRPO optimizes the model to reconcile conflicting visual constraints, significantly enhancing compositional consistency. We will open-source the code, models, training data, and reward data for community research purposes.
Spatial Chain-of-Thought: Bridging Understanding and Generation Models for Spatial Reasoning Generation
Feb 12, 2026While diffusion models have shown exceptional capabilities in aesthetic image synthesis, they often struggle with complex spatial understanding and reasoning. Existing approaches resort to Multimodal Large Language Models (MLLMs) to enhance this capability. However, they either incur high computational costs through joint training or suffer from spatial information loss when relying solely on textual prompts. To alleviate these limitations, we propose a Spatial Chain-of-Thought (SCoT) framework, a plug-and-play approach that effectively bridges the reasoning capabilities of MLLMs with the generative power of diffusion models. Specifically, we first enhance the diffusion model's layout awareness by training it on an interleaved text-coordinate instruction format. We then leverage state-of-the-art MLLMs as planners to generate comprehensive layout plans, transferring their spatial planning capabilities directly to the generation process. Extensive experiments demonstrate that our method achieves state-of-the-art performance on image generation benchmarks and significantly outperforms baselines on complex reasoning tasks, while also showing strong efficacy in image editing scenarios.
Joint Reward Modeling: Internalizing Chain-of-Thought for Efficient Visual Reward Models
Feb 07, 2026Reward models are critical for reinforcement learning from human feedback, as they determine the alignment quality and reliability of generative models. For complex tasks such as image editing, reward models are required to capture global semantic consistency and implicit logical constraints beyond local similarity. Existing reward modeling approaches have clear limitations. Discriminative reward models align well with human preferences but struggle with complex semantics due to limited reasoning supervision. Generative reward models offer stronger semantic understanding and reasoning, but they are costly at inference time and difficult to align directly with human preferences. To this end, we propose Joint Reward Modeling (JRM), which jointly optimizes preference learning and language modeling on a shared vision-language backbone. This approach internalizes the semantic and reasoning capabilities of generative models into efficient discriminative representations, enabling fast and accurate evaluation. JRM achieves state-of-the-art results on MMRB2 and EditReward-Bench, and significantly improves stability and performance in downstream online reinforcement learning. These results show that joint training effectively bridges efficiency and semantic understanding in reward modeling.
SpatialReward: Bridging the Perception Gap in Online RL for Image Editing via Explicit Spatial Reasoning
Feb 07, 2026Online Reinforcement Learning (RL) offers a promising avenue for complex image editing but is currently constrained by the scarcity of reliable and fine-grained reward signals. Existing evaluators frequently struggle with a critical perception gap we term "Attention Collapse," where models neglect cross-image comparisons and fail to capture fine-grained details, resulting in inaccurate perception and miscalibrated scores. To address these limitations, we propose SpatialReward, a reward model that enforces precise verification via explicit spatial reasoning. By anchoring reasoning to predicted edit regions, SpatialReward grounds semantic judgments in pixel-level evidence, significantly enhancing evaluative accuracy. Trained on a curated 260k spatial-aware dataset, our model achieves state-of-the-art performance on MMRB2 and EditReward-Bench, and outperforms proprietary evaluators on our proposed MultiEditReward-Bench. Furthermore, SpatialReward serves as a robust signal in online RL, boosting OmniGen2 by +0.90 on GEdit-Bench--surpassing the leading discriminative model and doubling the gain of GPT-4.1 (+0.45). These results demonstrate that spatial reasoning is essential for unlocking effective alignment in image editing.
Generation Enhances Understanding in Unified Multimodal Models via Multi-Representation Generation
Jan 29, 2026Unified Multimodal Models (UMMs) integrate both visual understanding and generation within a single framework. Their ultimate aspiration is to create a cycle where understanding and generation mutually reinforce each other. While recent post-training methods have successfully leveraged understanding to enhance generation, the reverse direction of utilizing generation to improve understanding remains largely unexplored. In this work, we propose UniMRG (Unified Multi-Representation Generation), a simple yet effective architecture-agnostic post-training method. UniMRG enhances the understanding capabilities of UMMs by incorporating auxiliary generation tasks. Specifically, we train UMMs to generate multiple intrinsic representations of input images, namely pixel (reconstruction), depth (geometry), and segmentation (structure), alongside standard visual understanding objectives. By synthesizing these diverse representations, UMMs capture complementary information regarding appearance, spatial relations, and structural layout. Consequently, UMMs develop a deeper and more comprehensive understanding of visual inputs. Extensive experiments across diverse UMM architectures demonstrate that our method notably enhances fine-grained perception, reduces hallucinations, and improves spatial understanding, while simultaneously boosting generation capabilities.
Skywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
MICo-150K: A Comprehensive Dataset Advancing Multi-Image Composition
Dec 08, 2025



In controllable image generation, synthesizing coherent and consistent images from multiple reference inputs, i.e., Multi-Image Composition (MICo), remains a challenging problem, partly hindered by the lack of high-quality training data. To bridge this gap, we conduct a systematic study of MICo, categorizing it into 7 representative tasks and curate a large-scale collection of high-quality source images and construct diverse MICo prompts. Leveraging powerful proprietary models, we synthesize a rich amount of balanced composite images, followed by human-in-the-loop filtering and refinement, resulting in MICo-150K, a comprehensive dataset for MICo with identity consistency. We further build a Decomposition-and-Recomposition (De&Re) subset, where 11K real-world complex images are decomposed into components and recomposed, enabling both real and synthetic compositions. To enable comprehensive evaluation, we construct MICo-Bench with 100 cases per task and 300 challenging De&Re cases, and further introduce a new metric, Weighted-Ref-VIEScore, specifically tailored for MICo evaluation. Finally, we fine-tune multiple models on MICo-150K and evaluate them on MICo-Bench. The results show that MICo-150K effectively equips models without MICo capability and further enhances those with existing skills. Notably, our baseline model, Qwen-MICo, fine-tuned from Qwen-Image-Edit, matches Qwen-Image-2509 in 3-image composition while supporting arbitrary multi-image inputs beyond the latter's limitation. Our dataset, benchmark, and baseline collectively offer valuable resources for further research on Multi-Image Composition.
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

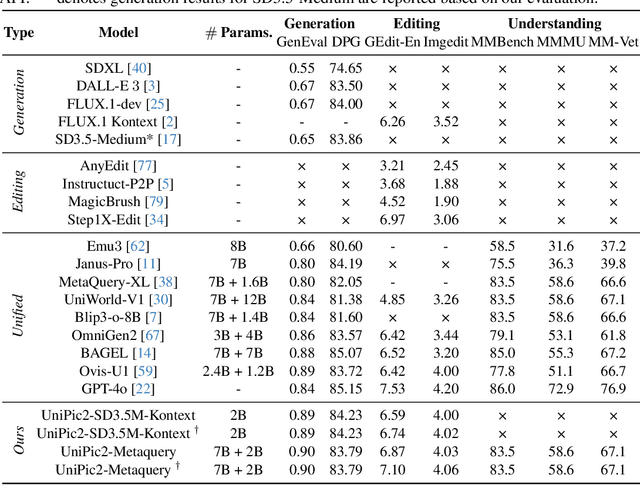
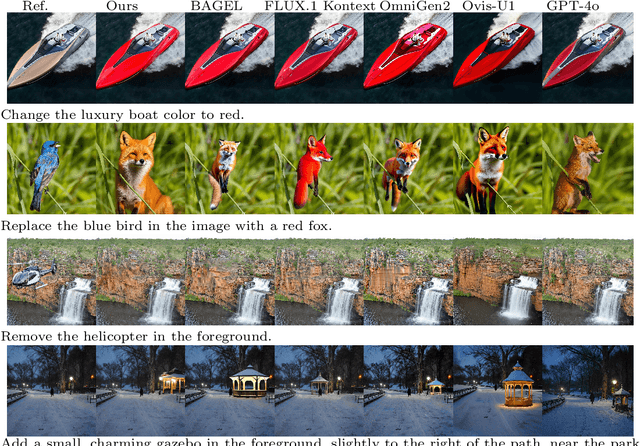
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.