 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExternal Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
EGSRAL: An Enhanced 3D Gaussian Splatting based Renderer with Automated Labeling for Large-Scale Driving Scene
Dec 20, 2024



3D Gaussian Splatting (3D GS) has gained popularity due to its faster rendering speed and high-quality novel view synthesis. Some researchers have explored using 3D GS for reconstructing driving scenes. However, these methods often rely on various data types, such as depth maps, 3D boxes, and trajectories of moving objects. Additionally, the lack of annotations for synthesized images limits their direct application in downstream tasks. To address these issues, we propose EGSRAL, a 3D GS-based method that relies solely on training images without extra annotations. EGSRAL enhances 3D GS's capability to model both dynamic objects and static backgrounds and introduces a novel adaptor for auto labeling, generating corresponding annotations based on existing annotations. We also propose a grouping strategy for vanilla 3D GS to address perspective issues in rendering large-scale, complex scenes. Our method achieves state-of-the-art performance on multiple datasets without any extra annotation. For example, the PSNR metric reaches 29.04 on the nuScenes dataset. Moreover, our automated labeling can significantly improve the performance of 2D/3D detection tasks. Code is available at https://github.com/jiangxb98/EGSRAL.
Fast Occupancy Network
Dec 10, 2024Occupancy Network has recently attracted much attention in autonomous driving. Instead of monocular 3D detection and recent bird's eye view(BEV) models predicting 3D bounding box of obstacles, Occupancy Network predicts the category of voxel in specified 3D space around the ego vehicle via transforming 3D detection task into 3D voxel segmentation task, which has much superiority in tackling category outlier obstacles and providing fine-grained 3D representation. However, existing methods usually require huge computation resources than previous methods, which hinder the Occupancy Network solution applying in intelligent driving systems. To address this problem, we make an analysis of the bottleneck of Occupancy Network inference cost, and present a simple and fast Occupancy Network model, which adopts a deformable 2D convolutional layer to lift BEV feature to 3D voxel feature and presents an efficient voxel feature pyramid network (FPN) module to improve performance with few computational cost. Further, we present a cost-free 2D segmentation branch in perspective view after feature extractors for Occupancy Network during inference phase to improve accuracy. Experimental results demonstrate that our method consistently outperforms existing methods in both accuracy and inference speed, which surpasses recent state-of-the-art (SOTA) OCCNet by 1.7% with ResNet50 backbone with about 3X inference speedup. Furthermore, our method can be easily applied to existing BEV models to transform them into Occupancy Network models.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024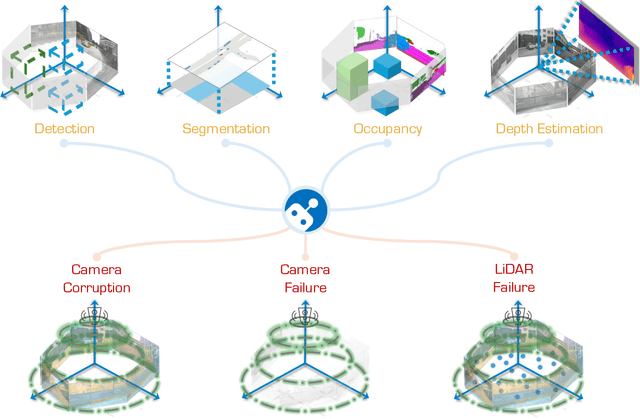


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
LIGHT: Joint Individual Building Extraction and Height Estimation from Satellite Images through a Unified Multitask Learning Network
Apr 03, 2023
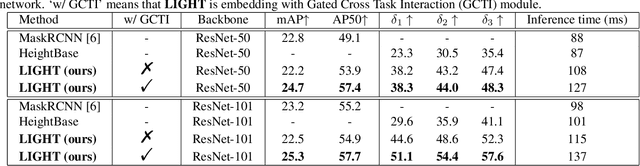


Building extraction and height estimation are two important basic tasks in remote sensing image interpretation, which are widely used in urban planning, real-world 3D construction, and other fields. Most of the existing research regards the two tasks as independent studies. Therefore the height information cannot be fully used to improve the accuracy of building extraction and vice versa. In this work, we combine the individuaL buIlding extraction and heiGHt estimation through a unified multiTask learning network (LIGHT) for the first time, which simultaneously outputs a height map, bounding boxes, and a segmentation mask map of buildings. Specifically, LIGHT consists of an instance segmentation branch and a height estimation branch. In particular, so as to effectively unify multi-scale feature branches and alleviate feature spans between branches, we propose a Gated Cross Task Interaction (GCTI) module that can efficiently perform feature interaction between branches. Experiments on the DFC2023 dataset show that our LIGHT can achieve superior performance, and our GCTI module with ResNet101 as the backbone can significantly improve the performance of multitask learning by 2.8% AP50 and 6.5% delta1, respectively.