 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Dec 11, 2025Generative world models are reshaping embodied AI, enabling agents to synthesize realistic 4D driving environments that look convincing but often fail physically or behaviorally. Despite rapid progress, the field still lacks a unified way to assess whether generated worlds preserve geometry, obey physics, or support reliable control. We introduce WorldLens, a full-spectrum benchmark evaluating how well a model builds, understands, and behaves within its generated world. It spans five aspects -- Generation, Reconstruction, Action-Following, Downstream Task, and Human Preference -- jointly covering visual realism, geometric consistency, physical plausibility, and functional reliability. Across these dimensions, no existing world model excels universally: those with strong textures often violate physics, while geometry-stable ones lack behavioral fidelity. To align objective metrics with human judgment, we further construct WorldLens-26K, a large-scale dataset of human-annotated videos with numerical scores and textual rationales, and develop WorldLens-Agent, an evaluation model distilled from these annotations to enable scalable, explainable scoring. Together, the benchmark, dataset, and agent form a unified ecosystem for measuring world fidelity -- standardizing how future models are judged not only by how real they look, but by how real they behave.
Learning to Remove Lens Flare in Event Camera
Dec 09, 2025Event cameras have the potential to revolutionize vision systems with their high temporal resolution and dynamic range, yet they remain susceptible to lens flare, a fundamental optical artifact that causes severe degradation. In event streams, this optical artifact forms a complex, spatio-temporal distortion that has been largely overlooked. We present E-Deflare, the first systematic framework for removing lens flare from event camera data. We first establish the theoretical foundation by deriving a physics-grounded forward model of the non-linear suppression mechanism. This insight enables the creation of the E-Deflare Benchmark, a comprehensive resource featuring a large-scale simulated training set, E-Flare-2.7K, and the first-ever paired real-world test set, E-Flare-R, captured by our novel optical system. Empowered by this benchmark, we design E-DeflareNet, which achieves state-of-the-art restoration performance. Extensive experiments validate our approach and demonstrate clear benefits for downstream tasks. Code and datasets are publicly available.
Visual Grounding from Event Cameras
Sep 11, 2025Event cameras capture changes in brightness with microsecond precision and remain reliable under motion blur and challenging illumination, offering clear advantages for modeling highly dynamic scenes. Yet, their integration with natural language understanding has received little attention, leaving a gap in multimodal perception. To address this, we introduce Talk2Event, the first large-scale benchmark for language-driven object grounding using event data. Built on real-world driving scenarios, Talk2Event comprises 5,567 scenes, 13,458 annotated objects, and more than 30,000 carefully validated referring expressions. Each expression is enriched with four structured attributes -- appearance, status, relation to the viewer, and relation to surrounding objects -- that explicitly capture spatial, temporal, and relational cues. This attribute-centric design supports interpretable and compositional grounding, enabling analysis that moves beyond simple object recognition to contextual reasoning in dynamic environments. We envision Talk2Event as a foundation for advancing multimodal and temporally-aware perception, with applications spanning robotics, human-AI interaction, and so on.
Talk2Event: Grounded Understanding of Dynamic Scenes from Event Cameras
Jul 23, 2025Event cameras offer microsecond-level latency and robustness to motion blur, making them ideal for understanding dynamic environments. Yet, connecting these asynchronous streams to human language remains an open challenge. We introduce Talk2Event, the first large-scale benchmark for language-driven object grounding in event-based perception. Built from real-world driving data, we provide over 30,000 validated referring expressions, each enriched with four grounding attributes -- appearance, status, relation to viewer, and relation to other objects -- bridging spatial, temporal, and relational reasoning. To fully exploit these cues, we propose EventRefer, an attribute-aware grounding framework that dynamically fuses multi-attribute representations through a Mixture of Event-Attribute Experts (MoEE). Our method adapts to different modalities and scene dynamics, achieving consistent gains over state-of-the-art baselines in event-only, frame-only, and event-frame fusion settings. We hope our dataset and approach will establish a foundation for advancing multimodal, temporally-aware, and language-driven perception in real-world robotics and autonomy.
EventFly: Event Camera Perception from Ground to the Sky
Mar 25, 2025Cross-platform adaptation in event-based dense perception is crucial for deploying event cameras across diverse settings, such as vehicles, drones, and quadrupeds, each with unique motion dynamics, viewpoints, and class distributions. In this work, we introduce EventFly, a framework for robust cross-platform adaptation in event camera perception. Our approach comprises three key components: i) Event Activation Prior (EAP), which identifies high-activation regions in the target domain to minimize prediction entropy, fostering confident, domain-adaptive predictions; ii) EventBlend, a data-mixing strategy that integrates source and target event voxel grids based on EAP-driven similarity and density maps, enhancing feature alignment; and iii) EventMatch, a dual-discriminator technique that aligns features from source, target, and blended domains for better domain-invariant learning. To holistically assess cross-platform adaptation abilities, we introduce EXPo, a large-scale benchmark with diverse samples across vehicle, drone, and quadruped platforms. Extensive experiments validate our effectiveness, demonstrating substantial gains over popular adaptation methods. We hope this work can pave the way for more adaptive, high-performing event perception across diverse and complex environments.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024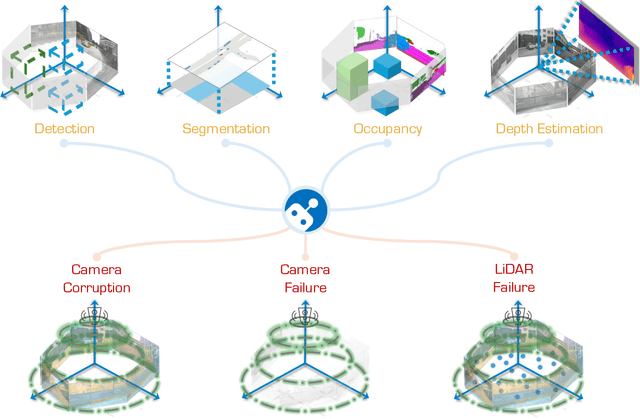


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
OpenESS: Event-based Semantic Scene Understanding with Open Vocabularies
May 08, 2024



Event-based semantic segmentation (ESS) is a fundamental yet challenging task for event camera sensing. The difficulties in interpreting and annotating event data limit its scalability. While domain adaptation from images to event data can help to mitigate this issue, there exist data representational differences that require additional effort to resolve. In this work, for the first time, we synergize information from image, text, and event-data domains and introduce OpenESS to enable scalable ESS in an open-world, annotation-efficient manner. We achieve this goal by transferring the semantically rich CLIP knowledge from image-text pairs to event streams. To pursue better cross-modality adaptation, we propose a frame-to-event contrastive distillation and a text-to-event semantic consistency regularization. Experimental results on popular ESS benchmarks showed our approach outperforms existing methods. Notably, we achieve 53.93% and 43.31% mIoU on DDD17 and DSEC-Semantic without using either event or frame labels.
RoboDepth: Robust Out-of-Distribution Depth Estimation under Corruptions
Oct 23, 2023Depth estimation from monocular images is pivotal for real-world visual perception systems. While current learning-based depth estimation models train and test on meticulously curated data, they often overlook out-of-distribution (OoD) situations. Yet, in practical settings -- especially safety-critical ones like autonomous driving -- common corruptions can arise. Addressing this oversight, we introduce a comprehensive robustness test suite, RoboDepth, encompassing 18 corruptions spanning three categories: i) weather and lighting conditions; ii) sensor failures and movement; and iii) data processing anomalies. We subsequently benchmark 42 depth estimation models across indoor and outdoor scenes to assess their resilience to these corruptions. Our findings underscore that, in the absence of a dedicated robustness evaluation framework, many leading depth estimation models may be susceptible to typical corruptions. We delve into design considerations for crafting more robust depth estimation models, touching upon pre-training, augmentation, modality, model capacity, and learning paradigms. We anticipate our benchmark will establish a foundational platform for advancing robust OoD depth estimation.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.