 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreaming up scale invariance via inverse renormalization group
Jun 04, 2025We explore how minimal neural networks can invert the renormalization group (RG) coarse-graining procedure in the two-dimensional Ising model, effectively "dreaming up" microscopic configurations from coarse-grained states. This task-formally impossible at the level of configurations-can be approached probabilistically, allowing machine learning models to reconstruct scale-invariant distributions without relying on microscopic input. We demonstrate that even neural networks with as few as three trainable parameters can learn to generate critical configurations, reproducing the scaling behavior of observables such as magnetic susceptibility, heat capacity, and Binder ratios. A real-space renormalization group analysis of the generated configurations confirms that the models capture not only scale invariance but also reproduce nontrivial eigenvalues of the RG transformation. Surprisingly, we find that increasing network complexity by introducing multiple layers offers no significant benefit. These findings suggest that simple local rules, akin to those generating fractal structures, are sufficient to encode the universality of critical phenomena, opening the door to efficient generative models of statistical ensembles in physics.
Optical Flow estimation with Event-based Cameras and Spiking Neural Networks
Feb 13, 2023Event-based cameras are raising interest within the computer vision community. These sensors operate with asynchronous pixels, emitting events, or "spikes", when the luminance change at a given pixel since the last event surpasses a certain threshold. Thanks to their inherent qualities, such as their low power consumption, low latency and high dynamic range, they seem particularly tailored to applications with challenging temporal constraints and safety requirements. Event-based sensors are an excellent fit for Spiking Neural Networks (SNNs), since the coupling of an asynchronous sensor with neuromorphic hardware can yield real-time systems with minimal power requirements. In this work, we seek to develop one such system, using both event sensor data from the DSEC dataset and spiking neural networks to estimate optical flow for driving scenarios. We propose a U-Net-like SNN which, after supervised training, is able to make dense optical flow estimations. To do so, we encourage both minimal norm for the error vector and minimal angle between ground-truth and predicted flow, training our model with back-propagation using a surrogate gradient. In addition, the use of 3d convolutions allows us to capture the dynamic nature of the data by increasing the temporal receptive fields. Upsampling after each decoding stage ensures that each decoder's output contributes to the final estimation. Thanks to separable convolutions, we have been able to develop a light model (when compared to competitors) that can nonetheless yield reasonably accurate optical flow estimates.
StereoSpike: Depth Learning with a Spiking Neural Network
Sep 28, 2021
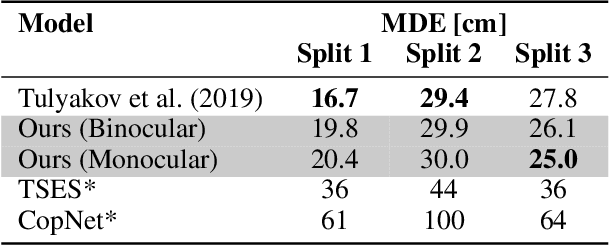

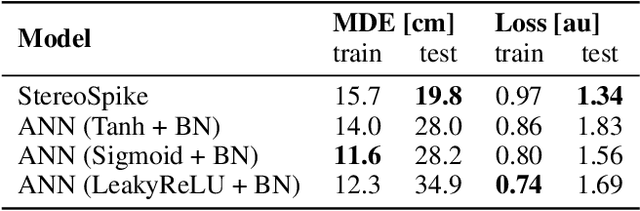
Depth estimation is an important computer vision task, useful in particular for navigation in autonomous vehicles, or for object manipulation in robotics. Here we solved it using an end-to-end neuromorphic approach, combining two event-based cameras and a Spiking Neural Network (SNN) with a slightly modified U-Net-like encoder-decoder architecture, that we named StereoSpike. More specifically, we used the Multi Vehicle Stereo Event Camera Dataset (MVSEC). It provides a depth ground-truth, which was used to train StereoSpike in a supervised manner, using surrogate gradient descent. We propose a novel readout paradigm to obtain a dense analog prediction -- the depth of each pixel -- from the spikes of the decoder. We demonstrate that this architecture generalizes very well, even better than its non-spiking counterparts, leading to state-of-the-art test accuracy. To the best of our knowledge, it is the first time that such a large-scale regression problem is solved by a fully spiking network. Finally, we show that low firing rates (<10%) can be obtained via regularization, with a minimal cost in accuracy. This means that StereoSpike could be efficiently implemented on neuromorphic chips, opening the door for low power and real time embedded systems.