 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-based Vision for Early Prediction of Manipulation Actions
Jul 26, 2023



Neuromorphic visual sensors are artificial retinas that output sequences of asynchronous events when brightness changes occur in the scene. These sensors offer many advantages including very high temporal resolution, no motion blur and smart data compression ideal for real-time processing. In this study, we introduce an event-based dataset on fine-grained manipulation actions and perform an experimental study on the use of transformers for action prediction with events. There is enormous interest in the fields of cognitive robotics and human-robot interaction on understanding and predicting human actions as early as possible. Early prediction allows anticipating complex stages for planning, enabling effective and real-time interaction. Our Transformer network uses events to predict manipulation actions as they occur, using online inference. The model succeeds at predicting actions early on, building up confidence over time and achieving state-of-the-art classification. Moreover, the attention-based transformer architecture allows us to study the role of the spatio-temporal patterns selected by the model. Our experiments show that the Transformer network captures action dynamic features outperforming video-based approaches and succeeding with scenarios where the differences between actions lie in very subtle cues. Finally, we release the new event dataset, which is the first in the literature for manipulation action recognition. Code will be available at https://github.com/DaniDeniz/EventVisionTransformer.
Optical Flow estimation with Event-based Cameras and Spiking Neural Networks
Feb 13, 2023Event-based cameras are raising interest within the computer vision community. These sensors operate with asynchronous pixels, emitting events, or "spikes", when the luminance change at a given pixel since the last event surpasses a certain threshold. Thanks to their inherent qualities, such as their low power consumption, low latency and high dynamic range, they seem particularly tailored to applications with challenging temporal constraints and safety requirements. Event-based sensors are an excellent fit for Spiking Neural Networks (SNNs), since the coupling of an asynchronous sensor with neuromorphic hardware can yield real-time systems with minimal power requirements. In this work, we seek to develop one such system, using both event sensor data from the DSEC dataset and spiking neural networks to estimate optical flow for driving scenarios. We propose a U-Net-like SNN which, after supervised training, is able to make dense optical flow estimations. To do so, we encourage both minimal norm for the error vector and minimal angle between ground-truth and predicted flow, training our model with back-propagation using a surrogate gradient. In addition, the use of 3d convolutions allows us to capture the dynamic nature of the data by increasing the temporal receptive fields. Upsampling after each decoding stage ensures that each decoder's output contributes to the final estimation. Thanks to separable convolutions, we have been able to develop a light model (when compared to competitors) that can nonetheless yield reasonably accurate optical flow estimates.
Reconfigurable Cyber-Physical System for Critical Infrastructure Protection in Smart Cities via Smart Video-Surveillance
Nov 29, 2020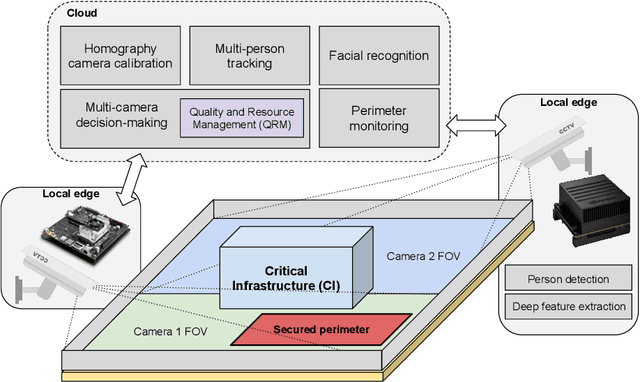

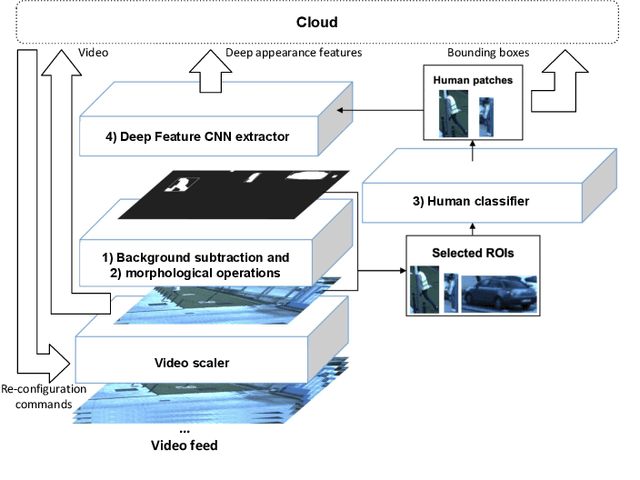

Automated surveillance is essential for the protection of Critical Infrastructures (CIs) in future Smart Cities. The dynamic environments and bandwidth requirements demand systems that adapt themselves to react when events of interest occur. We present a reconfigurable Cyber Physical System for the protection of CIs using distributed cloud-edge smart video surveillance. Our local edge nodes perform people detection via Deep Learning. Processing is embedded in high performance SoCs (System-on-Chip) achieving real-time performance ($\approx$ 100 fps - frames per second) which enables efficiently managing video streams of more cameras source at lower frame rate. Cloud server gathers results from nodes to carry out biometric facial identification, tracking, and perimeter monitoring. A Quality and Resource Management module monitors data bandwidth and triggers reconfiguration adapting the transmitted video resolution. This also enables a flexible use of the network by multiple cameras while maintaining the accuracy of biometric identification. A real-world example shows a reduction of $\approx$ 75\% bandwidth use with respect to the no-reconfiguration scenario.
* 13 pages, 8 figures and 5 tables
Reconfigurable Cyber-Physical System for Lifestyle Video-Monitoring via Deep Learning
Oct 07, 2020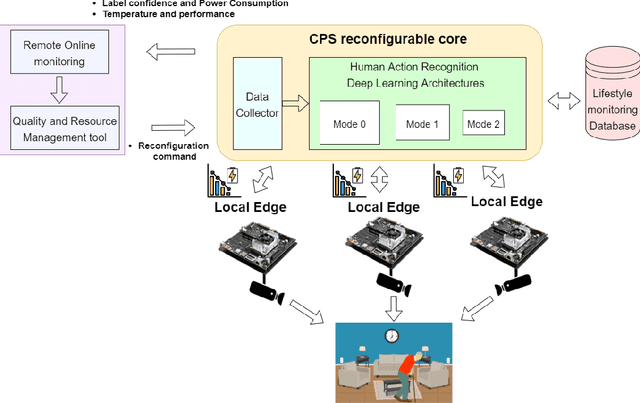

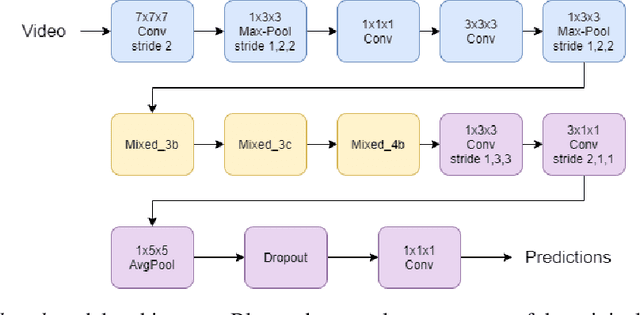
Indoor monitoring of people at their homes has become a popular application in Smart Health. With the advances in Machine Learning and hardware for embedded devices, new distributed approaches for Cyber-Physical Systems (CPSs) are enabled. Also, changing environments and need for cost reduction motivate novel reconfigurable CPS architectures. In this work, we propose an indoor monitoring reconfigurable CPS that uses embedded local nodes (Nvidia Jetson TX2). We embed Deep Learning architectures to address Human Action Recognition. Local processing at these nodes let us tackle some common issues: reduction of data bandwidth usage and preservation of privacy (no raw images are transmitted). Also real-time processing is facilitated since optimized nodes compute only its local video feed. Regarding the reconfiguration, a remote platform monitors CPS qualities and a Quality and Resource Management (QRM) tool sends commands to the CPS core to trigger its reconfiguration. Our proposal is an energy-aware system that triggers reconfiguration based on energy consumption for battery-powered nodes. Reconfiguration reduces up to 22% the local nodes energy consumption extending the device operating time, preserving similar accuracy with respect to the alternative with no reconfiguration.
Real-time clustering and multi-target tracking using event-based sensors
Jul 08, 2018
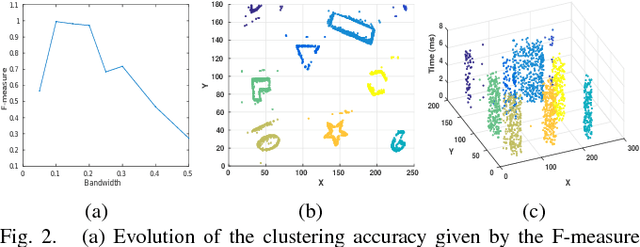
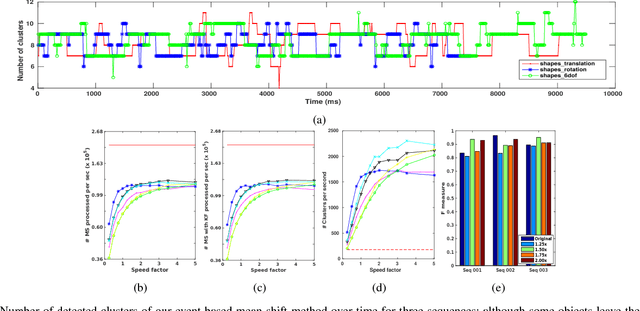
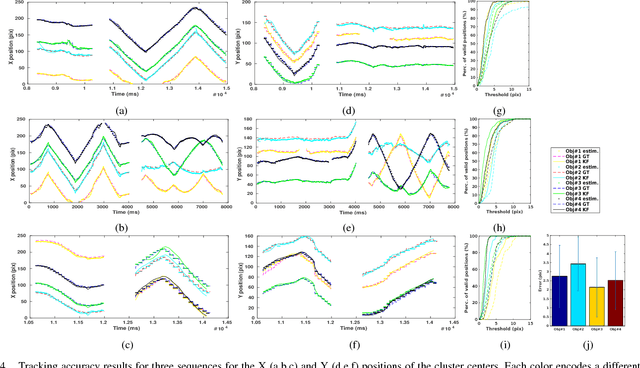
Clustering is crucial for many computer vision applications such as robust tracking, object detection and segmentation. This work presents a real-time clustering technique that takes advantage of the unique properties of event-based vision sensors. Since event-based sensors trigger events only when the intensity changes, the data is sparse, with low redundancy. Thus, our approach redefines the well-known mean-shift clustering method using asynchronous events instead of conventional frames. The potential of our approach is demonstrated in a multi-target tracking application using Kalman filters to smooth the trajectories. We evaluated our method on an existing dataset with patterns of different shapes and speeds, and a new dataset that we collected. The sensor was attached to the Baxter robot in an eye-in-hand setup monitoring real-world objects in an action manipulation task. Clustering accuracy achieved an F-measure of 0.95, reducing the computational cost by 88% compared to the frame-based method. The average error for tracking was 2.5 pixels and the clustering achieved a consistent number of clusters along time.
Joint direct estimation of 3D geometry and 3D motion using spatio temporal gradients
May 17, 2018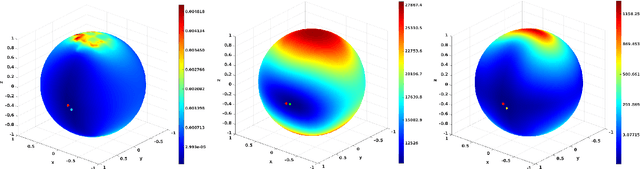
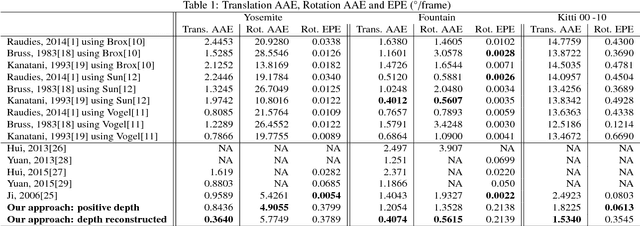
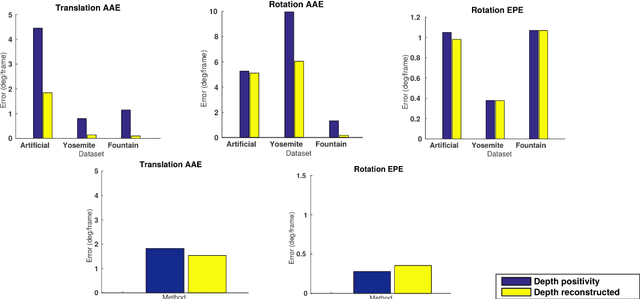

Conventional image motion based structure from motion methods first compute optical flow, then solve for the 3D motion parameters based on the epipolar constraint, and finally recover the 3D geometry of the scene. However, errors in optical flow due to regularization can lead to large errors in 3D motion and structure. This paper investigates whether performance and consistency can be improved by avoiding optical flow estimation in the early stages of the structure from motion pipeline, and it proposes a new direct method based on image gradients (normal flow) only. The main idea lies in a reformulation of the positive-depth constraint, which allows the use of well-known minimization techniques to solve for 3D motion. The 3D motion estimate is then refined and structure estimated adding a regularization based on depth. Experimental comparisons on standard synthetic datasets and the real-world driving benchmark dataset KITTI using three different optic flow algorithms show that the method achieves better accuracy in all but one case. Furthermore, it outperforms existing normal flow based 3D motion estimation techniques. Finally, the recovered 3D geometry is shown to be also very accurate.
Prediction of Manipulation Actions
Oct 03, 2016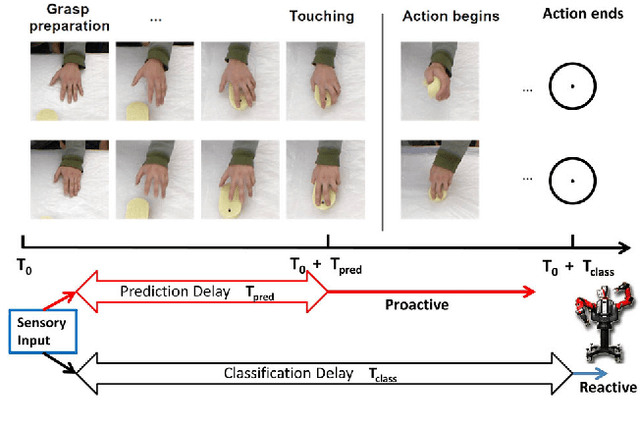



Looking at a person's hands one often can tell what the person is going to do next, how his/her hands are moving and where they will be, because an actor's intentions shape his/her movement kinematics during action execution. Similarly, active systems with real-time constraints must not simply rely on passive video-segment classification, but they have to continuously update their estimates and predict future actions. In this paper, we study the prediction of dexterous actions. We recorded from subjects performing different manipulation actions on the same object, such as "squeezing", "flipping", "washing", "wiping" and "scratching" with a sponge. In psychophysical experiments, we evaluated human observers' skills in predicting actions from video sequences of different length, depicting the hand movement in the preparation and execution of actions before and after contact with the object. We then developed a recurrent neural network based method for action prediction using as input patches around the hand. We also used the same formalism to predict the forces on the finger tips using for training synchronized video and force data streams. Evaluations on two new datasets showed that our system closely matches human performance in the recognition task, and demonstrate the ability of our algorithm to predict what and how a dexterous action is performed.