 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Robust Normal Estimation for Sparse LiDAR Scans
Apr 22, 2024Light Detection and Ranging (LiDAR) technology has proven to be an important part of many robotics systems. Surface normals estimated from LiDAR data are commonly used for a variety of tasks in such systems. As most of the today's mechanical LiDAR sensors produce sparse data, estimating normals from a single scan in a robust manner poses difficulties. In this paper, we address the problem of estimating normals for sparse LiDAR data avoiding the typical issues of smoothing out the normals in high curvature areas. Mechanical LiDARs rotate a set of rigidly mounted lasers. One firing of such a set of lasers produces an array of points where each point's neighbor is known due to the known firing pattern of the scanner. We use this knowledge to connect these points to their neighbors and label them using the angles of the lines connecting them. When estimating normals at these points, we only consider points with the same label as neighbors. This allows us to avoid estimating normals in high curvature areas. We evaluate our approach on various data, both self-recorded and publicly available, acquired using various sparse LiDAR sensors. We show that using our method for normal estimation leads to normals that are more robust in areas with high curvature which leads to maps of higher quality. We also show that our method only incurs a constant factor runtime overhead with respect to a lightweight baseline normal estimation procedure and is therefore suited for operation in computationally demanding environments.
Extracting Contact and Motion from Manipulation Videos
Feb 03, 2019



When we physically interact with our environment using our hands, we touch objects and force them to move: contact and motion are defining properties of manipulation. In this paper, we present an active, bottom-up method for the detection of actor-object contacts and the extraction of moved objects and their motions in RGBD videos of manipulation actions. At the core of our approach lies non-rigid registration: we continuously warp a point cloud model of the observed scene to the current video frame, generating a set of dense 3D point trajectories. Under loose assumptions, we employ simple point cloud segmentation techniques to extract the actor and subsequently detect actor-environment contacts based on the estimated trajectories. For each such interaction, using the detected contact as an attention mechanism, we obtain an initial motion segment for the manipulated object by clustering trajectories in the contact area vicinity and then we jointly refine the object segment and estimate its 6DOF pose in all observed frames. Because of its generality and the fundamental, yet highly informative, nature of its outputs, our approach is applicable to a wide range of perception and planning tasks. We qualitatively evaluate our method on a number of input sequences and present a comprehensive robot imitation learning example, in which we demonstrate the crucial role of our outputs in developing action representations/plans from observation.
Topology-Aware Non-Rigid Point Cloud Registration
Nov 23, 2018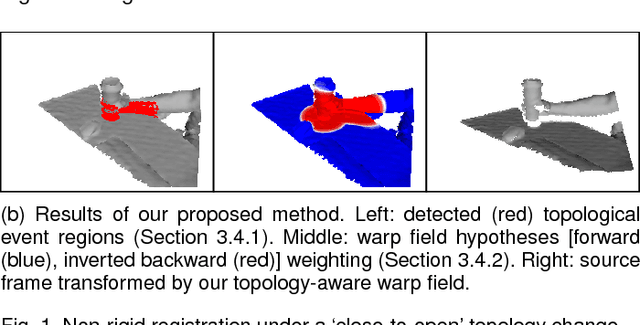
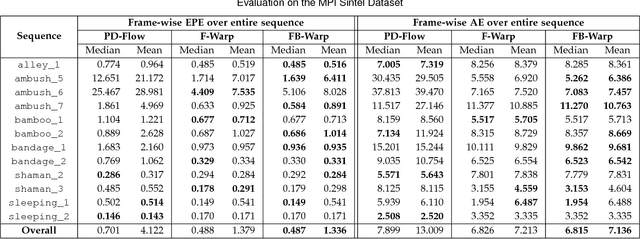
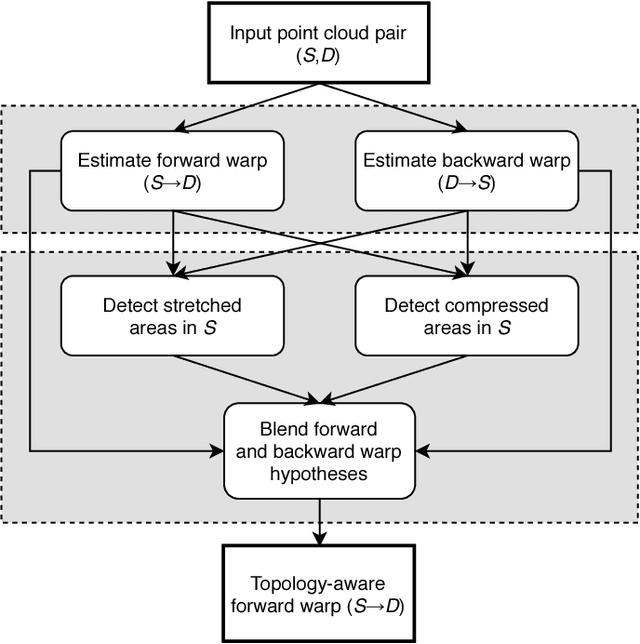

In this paper, we introduce a non-rigid registration pipeline for pairs of unorganized point clouds that may be topologically different. Standard warp field estimation algorithms, even under robust, discontinuity-preserving regularization, tend to produce erratic motion estimates on boundaries associated with `close-to-open' topology changes. We overcome this limitation by exploiting backward motion: in the opposite motion direction, a `close-to-open' event becomes `open-to-close', which is by default handled correctly. At the core of our approach lies a general, topology-agnostic warp field estimation algorithm, similar to those employed in recently introduced dynamic reconstruction systems from RGB-D input. We improve motion estimation on boundaries associated with topology changes in an efficient post-processing phase. Based on both forward and (inverted) backward warp hypotheses, we explicitly detect regions of the deformed geometry that undergo topological changes by means of local deformation criteria and broadly classify them as `contacts' or `separations'. Subsequently, the two motion hypotheses are seamlessly blended on a local basis, according to the type and proximity of detected events. Our method achieves state-of-the-art motion estimation accuracy on the MPI Sintel dataset. Experiments on a custom dataset with topological event annotations demonstrate the effectiveness of our pipeline in estimating motion on event boundaries, as well as promising performance in explicit topological event detection.
cilantro: A Lean, Versatile, and Efficient Library for Point Cloud Data Processing
Nov 16, 2018
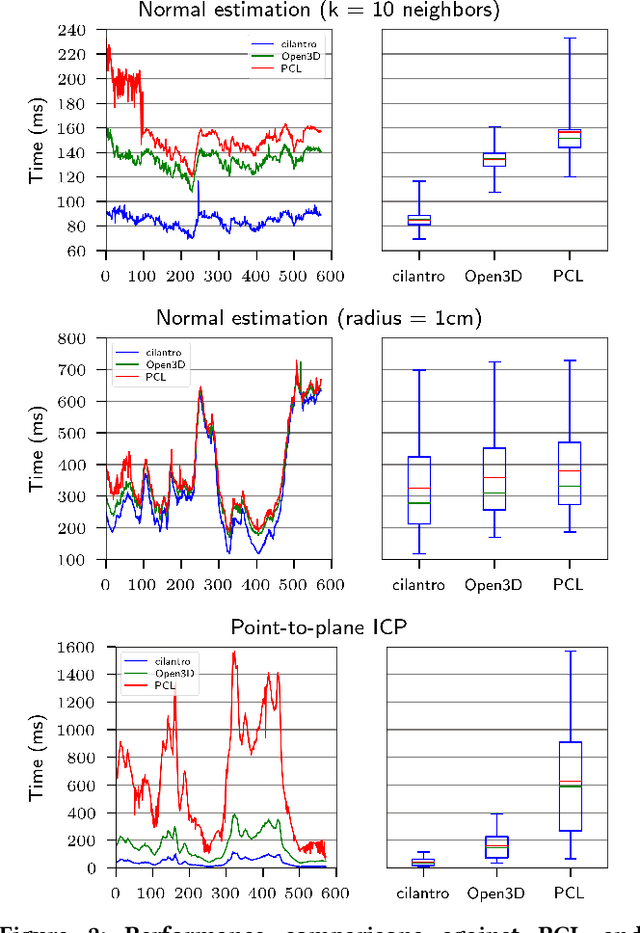
We introduce cilantro, an open-source C++ library for geometric and general-purpose point cloud data processing. The library provides functionality that covers low-level point cloud operations, spatial reasoning, various methods for point cloud segmentation and generic data clustering, flexible algorithms for robust or local geometric alignment, model fitting, as well as powerful visualization tools. To accommodate all kinds of workflows, cilantro is almost fully templated, and most of its generic algorithms operate in arbitrary data dimension. At the same time, the library is easy to use and highly expressive, promoting a clean and concise coding style. cilantro is highly optimized, has a minimal set of external dependencies, and supports rapid development of performant point cloud processing software in a wide variety of contexts.
Prediction of Manipulation Actions
Oct 03, 2016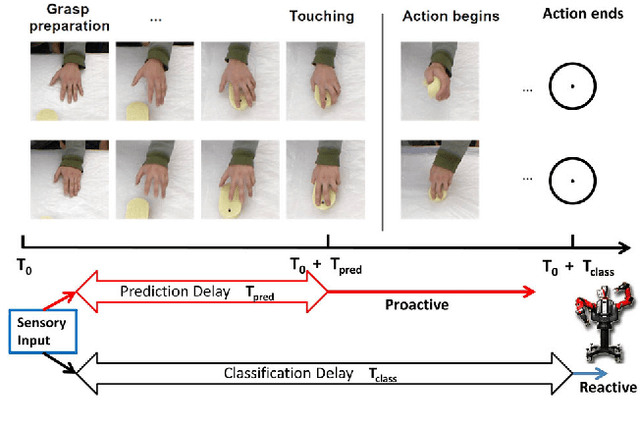



Looking at a person's hands one often can tell what the person is going to do next, how his/her hands are moving and where they will be, because an actor's intentions shape his/her movement kinematics during action execution. Similarly, active systems with real-time constraints must not simply rely on passive video-segment classification, but they have to continuously update their estimates and predict future actions. In this paper, we study the prediction of dexterous actions. We recorded from subjects performing different manipulation actions on the same object, such as "squeezing", "flipping", "washing", "wiping" and "scratching" with a sponge. In psychophysical experiments, we evaluated human observers' skills in predicting actions from video sequences of different length, depicting the hand movement in the preparation and execution of actions before and after contact with the object. We then developed a recurrent neural network based method for action prediction using as input patches around the hand. We also used the same formalism to predict the forces on the finger tips using for training synchronized video and force data streams. Evaluations on two new datasets showed that our system closely matches human performance in the recognition task, and demonstrate the ability of our algorithm to predict what and how a dexterous action is performed.