 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradTac: Spatio-Temporal Gradient Based Tactile Sensing
Mar 14, 2022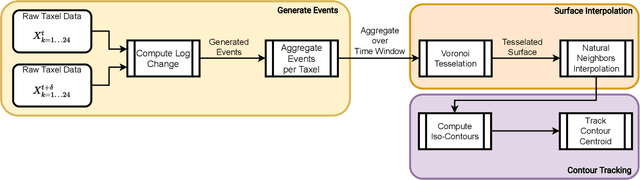
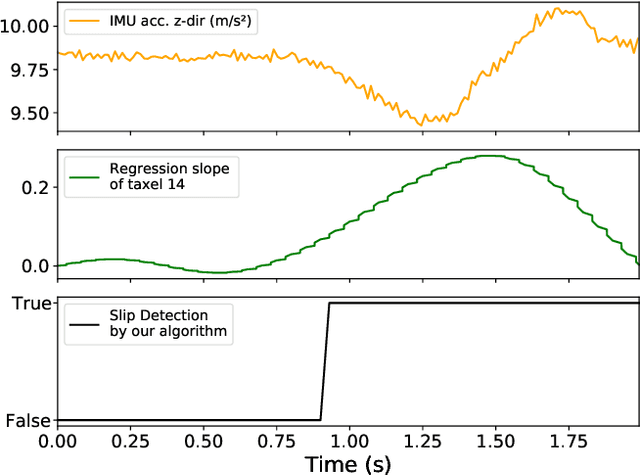

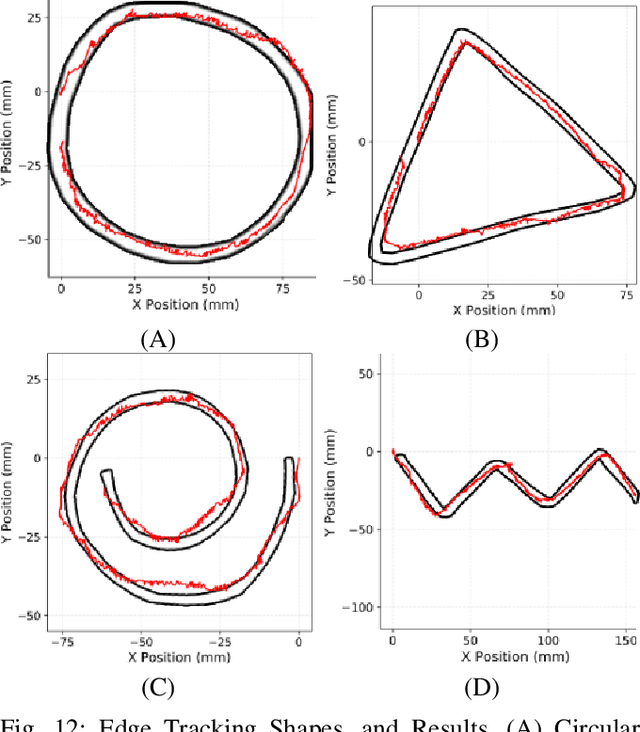
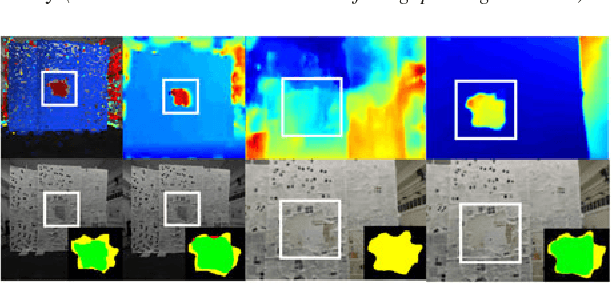
Tactile sensing for robotics is achieved through a variety of mechanisms, including magnetic, optical-tactile, and conductive fluid. Currently, the fluid-based sensors have struck the right balance of anthropomorphic sizes and shapes and accuracy of tactile response measurement. However, this design is plagued by a low Signal to Noise Ratio (SNR) due to the fluid based sensing mechanism "damping" the measurement values that are hard to model. To this end, we present a spatio-temporal gradient representation on the data obtained from fluid-based tactile sensors, which is inspired from neuromorphic principles of event based sensing. We present a novel algorithm (GradTac) that converts discrete data points from spatial tactile sensors into spatio-temporal surfaces and tracks tactile contours across these surfaces. Processing the tactile data using the proposed spatio-temporal domain is robust, makes it less susceptible to the inherent noise from the fluid based sensors, and allows accurate tracking of regions of touch as compared to using the raw data. We successfully evaluate and demonstrate the efficacy of GradTac on many real-world experiments performed using the Shadow Dexterous Hand, equipped with the BioTac SP sensors. Specifically, we use it for tracking tactile input across the sensor's surface, measuring relative forces, detecting linear and rotational slip, and for edge tracking. We also release an accompanying task-agnostic dataset for the BioTac SP, which we hope will provide a resource to compare and quantify various novel approaches, and motivate further research.
Grasping in the Dark: Compliant Grasping using Shadow Dexterous Hand and BioTac Tactile Sensor
Nov 02, 2020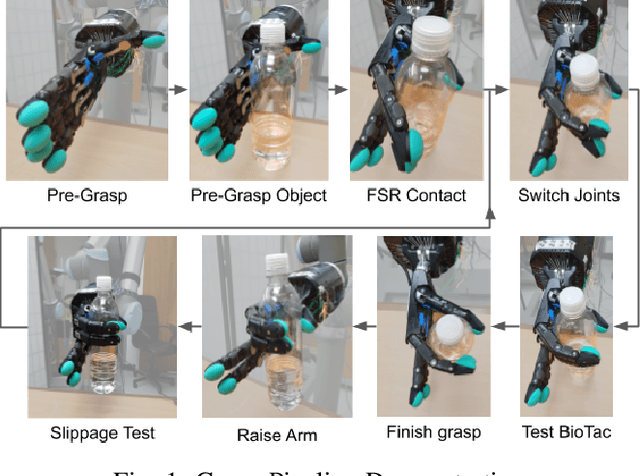
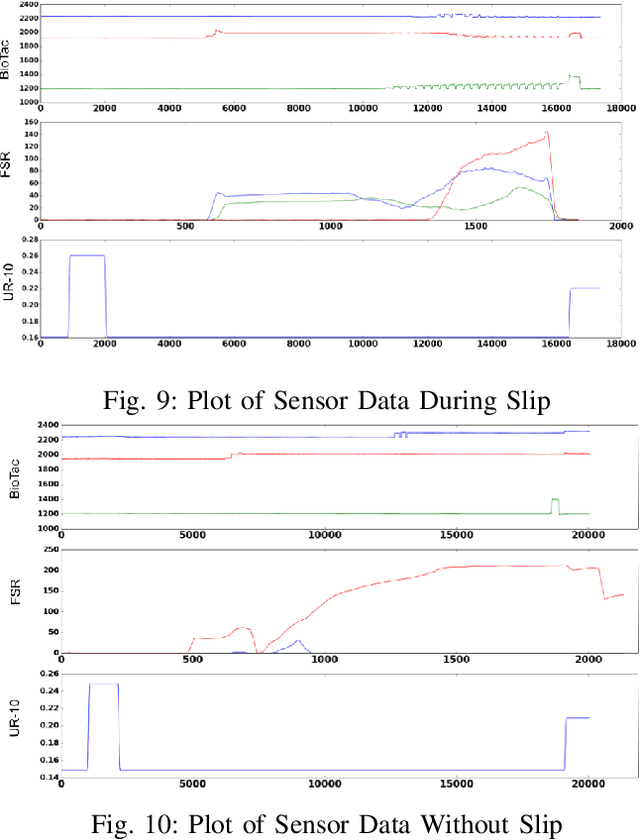

When it comes to grasping and manipulating objects, the human hand is the benchmark based on which we design and model grasping strategies and algorithms. The task of imitating human hand in robotic end-effectors, especially in scenarios where visual input is limited or absent, is an extremely challenging one. In this paper we present an adaptive, compliant grasping strategy using only tactile feedback. The proposed algorithm can grasp objects of varying shapes, sizes and weights without having a priori knowledge of the objects. The proof of concept algorithm presented here uses classical control formulations for closed-loop grasping. The algorithm has been experimentally validated using a Shadow Dexterous Hand equipped with BioTac tactile sensors. We demonstrate the success of our grasping policies on a variety of objects, such as bottles, boxes and balls.
Deep Differentiable Grasp Planner for High-DOF Grippers
Feb 04, 2020
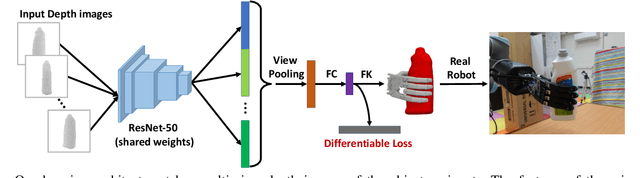
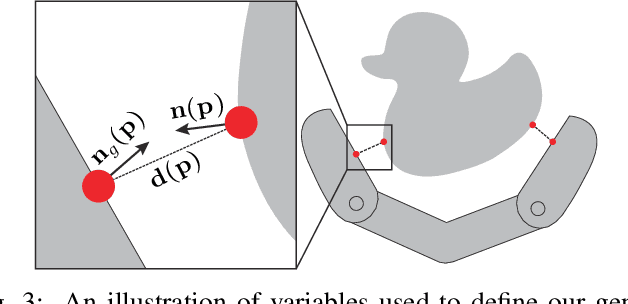
We present an end-to-end algorithm for training deep neural networks to grasp novel objects. Our algorithm builds all the essential components of a grasping system using a forward-backward automatic differentiation approach, including the forward kinematics of the gripper, the collision between the gripper and the target object, and the metric of grasp poses. In particular, we show that a generalized Q1 grasp metric is defined and differentiable for inexact grasps generated by a neural network, and the derivatives of our generalized Q1 metric can be computed from a sensitivity analysis of the induced optimization problem. We show that the derivatives of the (self-)collision terms can be efficiently computed from a watertight triangle mesh of low-quality. Put together, our algorithm allows the computation of grasp poses for high-DOF grippers in unsupervised mode with no ground truth data or improves the results in supervised mode using a small dataset. Our new learning algorithm significantly simplifies the data preparation for learning-based grasping systems and leads to higher qualities of learned grasps on common 3D shape datasets, achieving a 22% higher success rate on physical hardware and 0.12 higher value of the Q1 grasp quality metric.
Computational Tactile Flow for Anthropomorphic Grippers
Mar 19, 2019
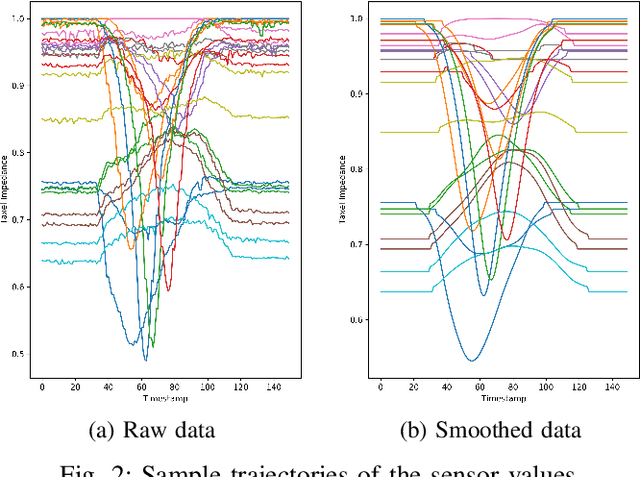
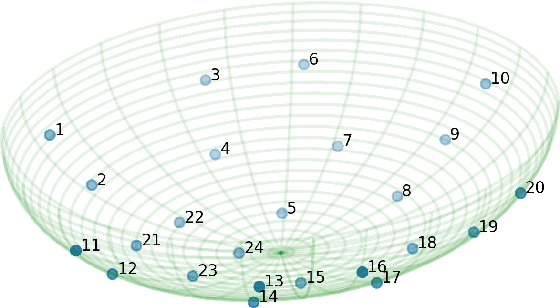
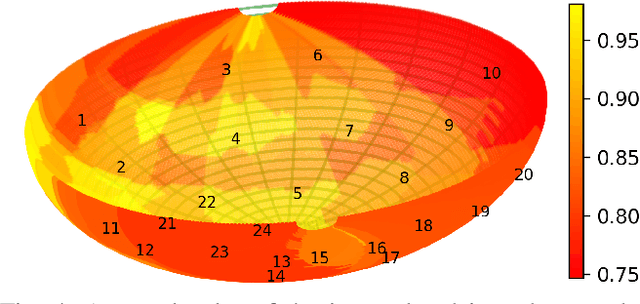
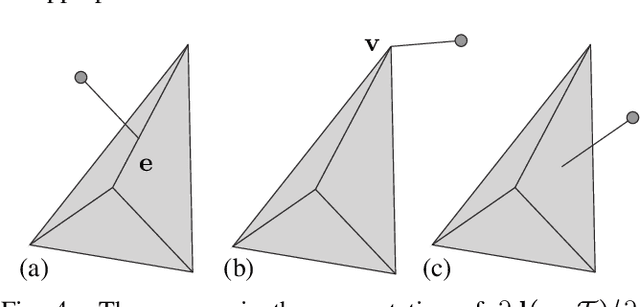
Grasping objects requires tight integration between visual and tactile feedback. However, there is an inherent difference in the scale at which both these input modalities operate. It is thus necessary to be able to analyze tactile feedback in isolation in order to gain information about the surface the end-effector is operating on, such that more fine-grained features may be extracted from the surroundings. For tactile perception of the robot, inspired by the concept of the tactile flow in humans, we present the computational tactile flow to improve the analysis of the tactile feedback in robots using a Shadow Dexterous Hand. In the computational tactile flow model, given a sequence of pressure values from the tactile sensors, we define a virtual surface for the pressure values and define the tactile flow as the optical flow of this surface. We provide case studies that demonstrate how the computational tactile flow maps reveal information on the direction of motion and 3D structure of the surface, and feedback regarding the action being performed by the robot.
Generating Grasp Poses for a High-DOF Gripper Using Neural Networks
Mar 05, 2019
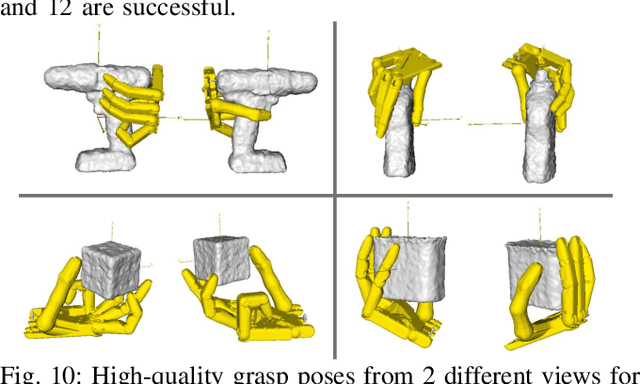
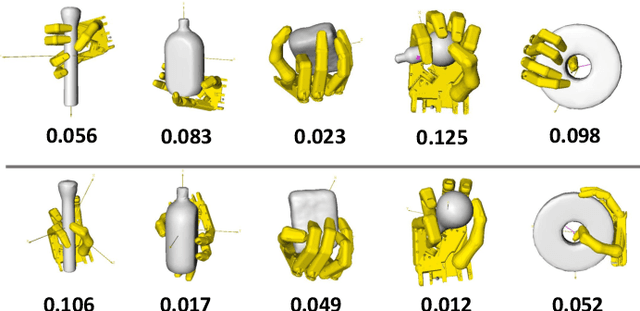
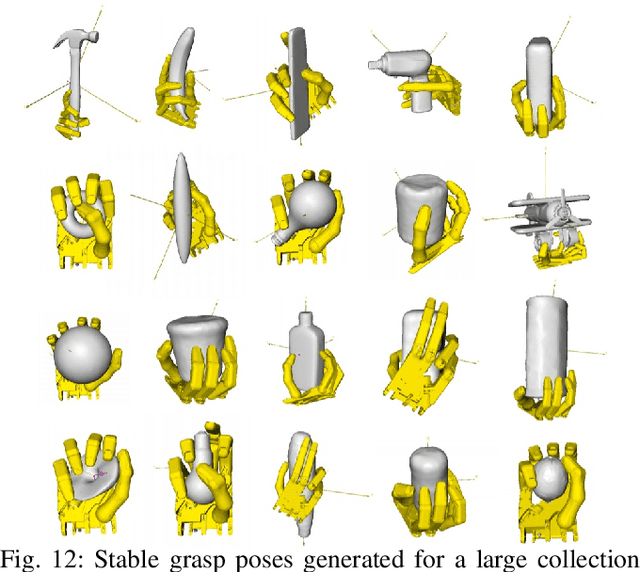
We present a learning-based method to represent grasp poses of a high-DOF hand using neural networks. Due to the redundancy in such high-DOF grippers, there exists a large number of equally effective grasp poses for a given target object, making it difficult for the neural network to find consistent grasp poses. We resolve this ambiguity by generating an augmented dataset that covers many possible grasps for each target object and train our neural networks using a consistency loss function to identify a one-to-one mapping from objects to grasp poses. We further enhance the quality of neuralnetwork-predicted grasp poses using a collision loss function to avoid penetrations. We use an object dataset combining the BigBIRD Database, the KIT Database, the YCB Database, and the Grasp Dataset, on which we show that our method can generate high-DOF grasp poses with higher accuracy than supervised learning baselines. The quality of grasp poses are on par with the groundtruth poses in the dataset. In addition, our method is robust and can handle noisy object models, such as those constructed from multi-view depth images, allowing our method to be implemented on a 25-DOF Shadow Hand hardware platform.
Extracting Contact and Motion from Manipulation Videos
Feb 03, 2019



When we physically interact with our environment using our hands, we touch objects and force them to move: contact and motion are defining properties of manipulation. In this paper, we present an active, bottom-up method for the detection of actor-object contacts and the extraction of moved objects and their motions in RGBD videos of manipulation actions. At the core of our approach lies non-rigid registration: we continuously warp a point cloud model of the observed scene to the current video frame, generating a set of dense 3D point trajectories. Under loose assumptions, we employ simple point cloud segmentation techniques to extract the actor and subsequently detect actor-environment contacts based on the estimated trajectories. For each such interaction, using the detected contact as an attention mechanism, we obtain an initial motion segment for the manipulated object by clustering trajectories in the contact area vicinity and then we jointly refine the object segment and estimate its 6DOF pose in all observed frames. Because of its generality and the fundamental, yet highly informative, nature of its outputs, our approach is applicable to a wide range of perception and planning tasks. We qualitatively evaluate our method on a number of input sequences and present a comprehensive robot imitation learning example, in which we demonstrate the crucial role of our outputs in developing action representations/plans from observation.
GapFlyt: Active Vision Based Minimalist Structure-less Gap Detection For Quadrotor Flight
Jul 01, 2018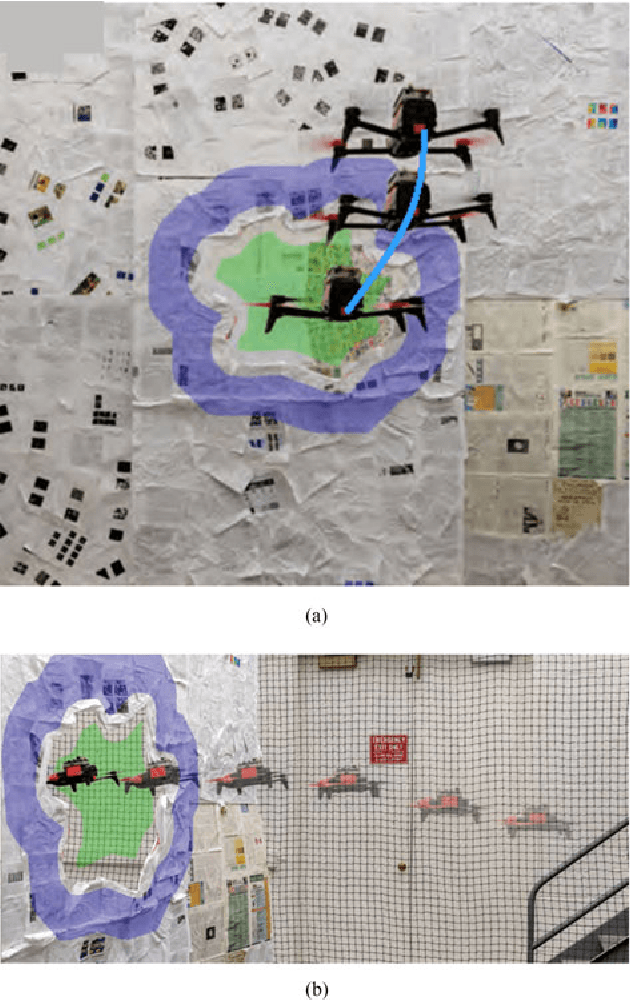


Although quadrotors, and aerial robots in general, are inherently active agents, their perceptual capabilities in literature so far have been mostly passive in nature. Researchers and practitioners today use traditional computer vision algorithms with the aim of building a representation of general applicability: a 3D reconstruction of the scene. Using this representation, planning tasks are constructed and accomplished to allow the quadrotor to demonstrate autonomous behavior. These methods are inefficient as they are not task driven and such methodologies are not utilized by flying insects and birds. Such agents have been solving the problem of navigation and complex control for ages without the need to build a 3D map and are highly task driven. In this paper, we propose this framework of bio-inspired perceptual design for quadrotors. We use this philosophy to design a minimalist sensori-motor framework for a quadrotor to fly though unknown gaps without a 3D reconstruction of the scene using only a monocular camera and onboard sensing. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with different settings and window shapes, achieving a success rate of 85% at 2.5ms$^{-1}$ even with a minimum tolerance of just 5cm. To our knowledge, this is the first paper which addresses the problem of gap detection of an unknown shape and location with a monocular camera and onboard sensing.