 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Grasp Poses for a High-DOF Gripper Using Neural Networks
Paper and Code
Mar 05, 2019
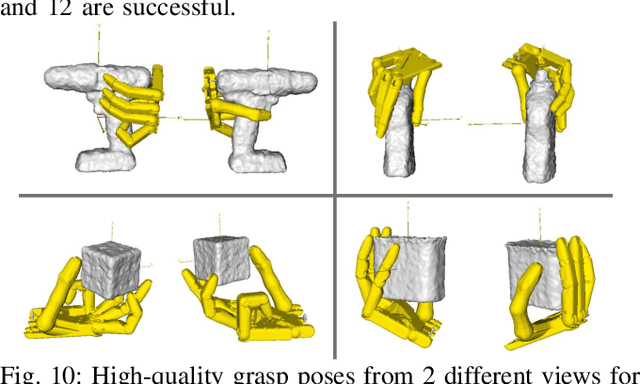
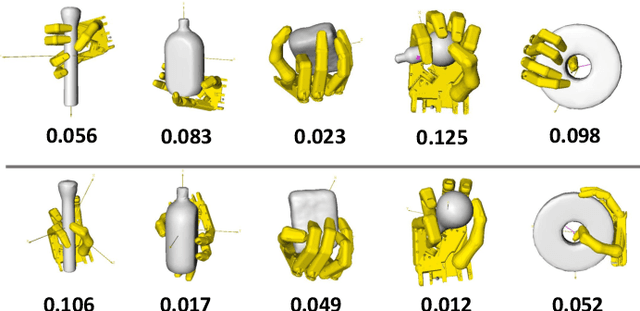
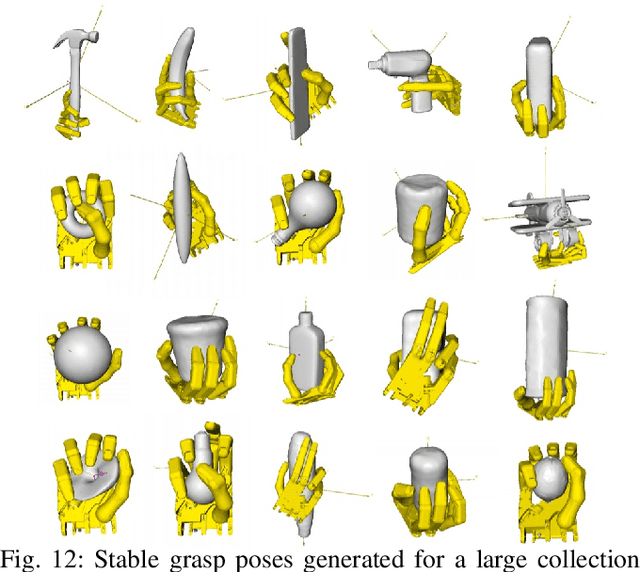
We present a learning-based method to represent grasp poses of a high-DOF hand using neural networks. Due to the redundancy in such high-DOF grippers, there exists a large number of equally effective grasp poses for a given target object, making it difficult for the neural network to find consistent grasp poses. We resolve this ambiguity by generating an augmented dataset that covers many possible grasps for each target object and train our neural networks using a consistency loss function to identify a one-to-one mapping from objects to grasp poses. We further enhance the quality of neuralnetwork-predicted grasp poses using a collision loss function to avoid penetrations. We use an object dataset combining the BigBIRD Database, the KIT Database, the YCB Database, and the Grasp Dataset, on which we show that our method can generate high-DOF grasp poses with higher accuracy than supervised learning baselines. The quality of grasp poses are on par with the groundtruth poses in the dataset. In addition, our method is robust and can handle noisy object models, such as those constructed from multi-view depth images, allowing our method to be implemented on a 25-DOF Shadow Hand hardware platform.