 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
May 28, 2026Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffering from diminishing transfer ratio -- the fraction of FM improvement captured by the VM -- as a single scalar cannot convey the rich intermediate knowledge that larger FMs learn. To address this bottleneck, we propose LoopFM (Learning frOm HistOrical ReP*resentations of FM), a framework that opens a high-bandwidth transfer channel by structuring FM intermediate embeddings as input features (e.g., user history sequence) for downstream VMs, without requiring real-time FM inference at serving and architectural coupling between FM and VM. We provide a theoretical framework for LoopFM with a gain decomposition and transfer-ratio analysis. On three public benchmarks, LoopFM demonstrates strong AUC improvements (e.g., 6\%+ on TaobaoAd) and complementary knowledge transfer capability with KD. On industrial-scale systems (billions of examples, trillion-parameter FMs), LoopFM approximately doubles the knowledge transfer ratio on top of KD, delivering a +0.5\% conversion improvement in Y1H1, and a +1.03\% and +1.22\% conversion improvement from two individual launches respectively in Y1H2.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
InterFormer: Towards Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction
Nov 15, 2024
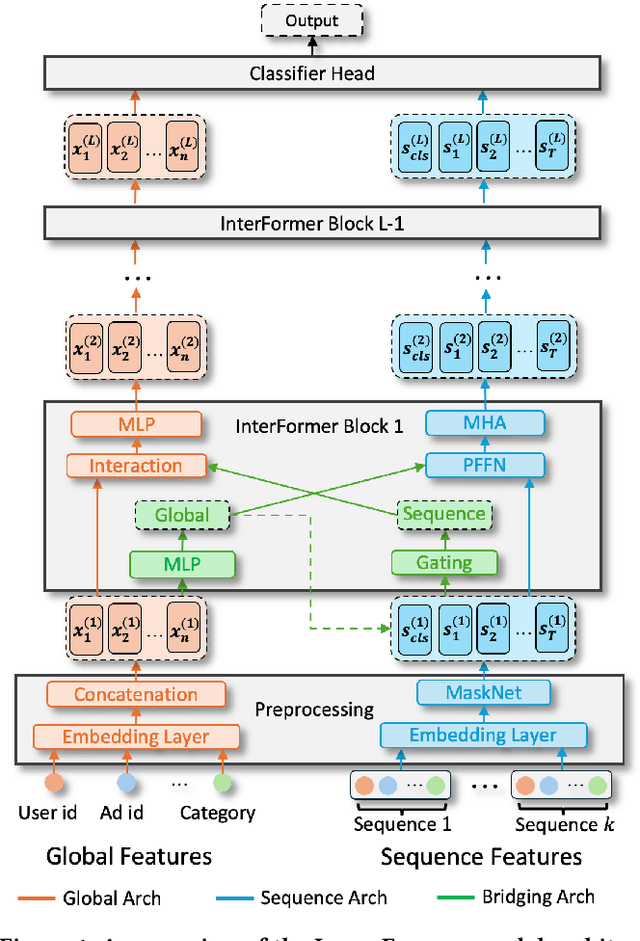
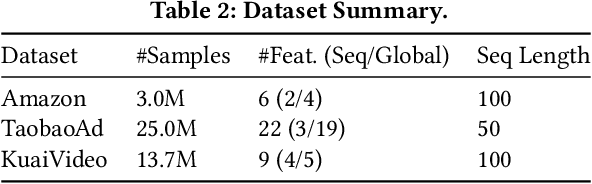
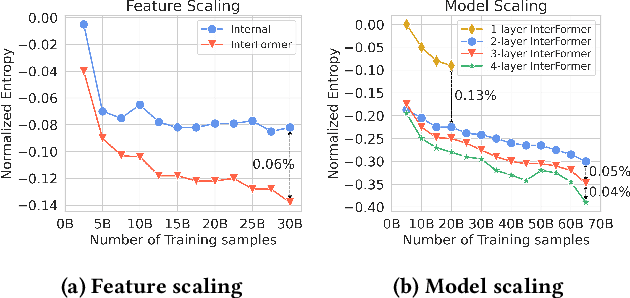
Click-through rate (CTR) prediction, which predicts the probability of a user clicking an ad, is a fundamental task in recommender systems. The emergence of heterogeneous information, such as user profile and behavior sequences, depicts user interests from different aspects. A mutually beneficial integration of heterogeneous information is the cornerstone towards the success of CTR prediction. However, most of the existing methods suffer from two fundamental limitations, including (1) insufficient inter-mode interaction due to the unidirectional information flow between modes, and (2) aggressive information aggregation caused by early summarization, resulting in excessive information loss. To address the above limitations, we propose a novel module named InterFormer to learn heterogeneous information interaction in an interleaving style. To achieve better interaction learning, InterFormer enables bidirectional information flow for mutually beneficial learning across different modes. To avoid aggressive information aggregation, we retain complete information in each data mode and use a separate bridging arch for effective information selection and summarization. Our proposed InterFormer achieves state-of-the-art performance on three public datasets and a large-scale industrial dataset.
GENIUS: A Novel Solution for Subteam Replacement with Clustering-based Graph Neural Network
Nov 11, 2022



Subteam replacement is defined as finding the optimal candidate set of people who can best function as an unavailable subset of members (i.e., subteam) for certain reasons (e.g., conflicts of interests, employee churn), given a team of people embedded in a social network working on the same task. Prior investigations on this problem incorporate graph kernel as the optimal criteria for measuring the similarity between the new optimized team and the original team. However, the increasingly abundant social networks reveal fundamental limitations of existing methods, including (1) the graph kernel-based approaches are powerless to capture the key intrinsic correlations among node features, (2) they generally search over the entire network for every member to be replaced, making it extremely inefficient as the network grows, and (3) the requirement of equal-sized replacement for the unavailable subteam can be inapplicable due to limited hiring budget. In this work, we address the limitations in the state-of-the-art for subteam replacement by (1) proposing GENIUS, a novel clustering-based graph neural network (GNN) framework that can capture team network knowledge for flexible subteam replacement, and (2) equipping the proposed GENIUS with self-supervised positive team contrasting training scheme to improve the team-level representation learning and unsupervised node clusters to prune candidates for fast computation. Through extensive empirical evaluations, we demonstrate the efficacy of the proposed method (1) effectiveness: being able to select better candidate members that significantly increase the similarity between the optimized and original teams, and (2) efficiency: achieving more than 600 times speed-up in average running time.
JuryGCN: Quantifying Jackknife Uncertainty on Graph Convolutional Networks
Oct 12, 2022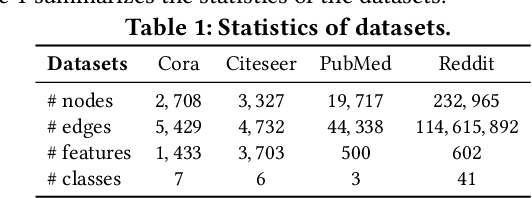
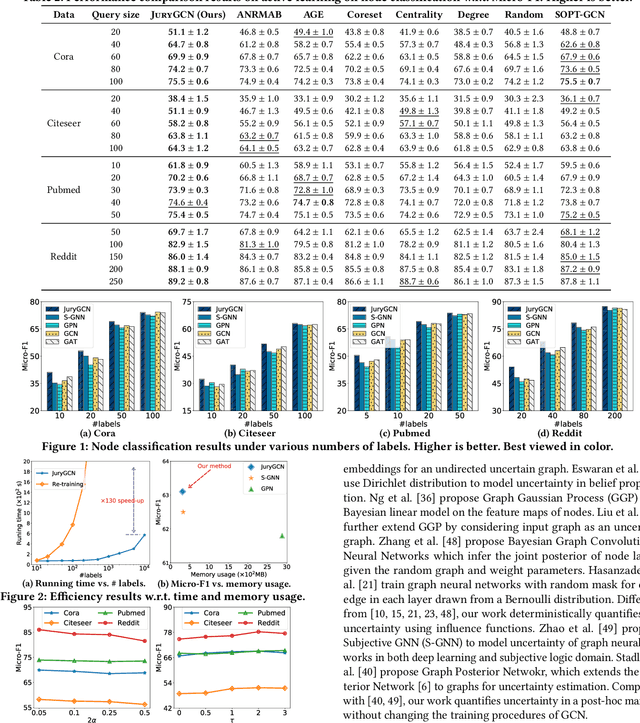
Graph Convolutional Network (GCN) has exhibited strong empirical performance in many real-world applications. The vast majority of existing works on GCN primarily focus on the accuracy while ignoring how confident or uncertain a GCN is with respect to its predictions. Despite being a cornerstone of trustworthy graph mining, uncertainty quantification on GCN has not been well studied and the scarce existing efforts either fail to provide deterministic quantification or have to change the training procedure of GCN by introducing additional parameters or architectures. In this paper, we propose the first frequentist-based approach named JuryGCN in quantifying the uncertainty of GCN, where the key idea is to quantify the uncertainty of a node as the width of confidence interval by a jackknife estimator. Moreover, we leverage the influence functions to estimate the change in GCN parameters without re-training to scale up the computation. The proposed JuryGCN is capable of quantifying uncertainty deterministically without modifying the GCN architecture or introducing additional parameters. We perform extensive experimental evaluation on real-world datasets in the tasks of both active learning and semi-supervised node classification, which demonstrate the efficacy of the proposed method.
Few-shot Network Anomaly Detection via Cross-network Meta-learning
Feb 22, 2021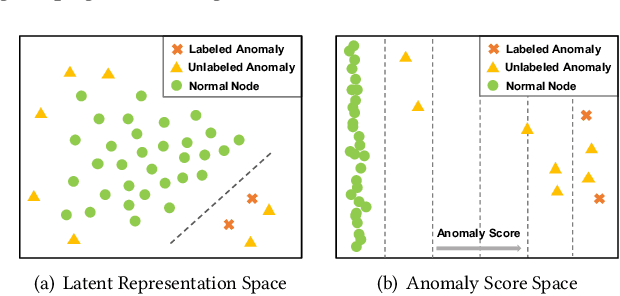
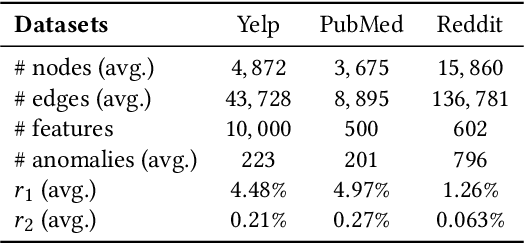
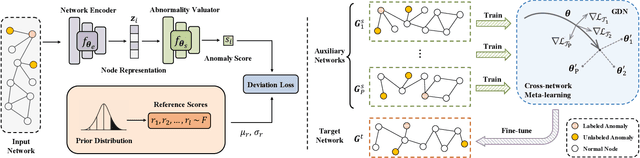
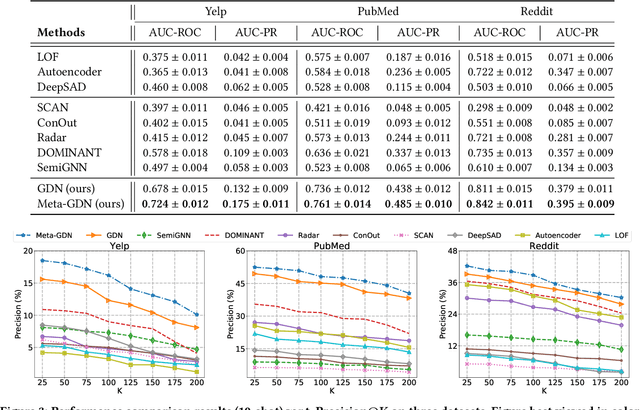
Network anomaly detection aims to find network elements (e.g., nodes, edges, subgraphs) with significantly different behaviors from the vast majority. It has a profound impact in a variety of applications ranging from finance, healthcare to social network analysis. Due to the unbearable labeling cost, existing methods are predominately developed in an unsupervised manner. Nonetheless, the anomalies they identify may turn out to be data noises or uninteresting data instances due to the lack of prior knowledge on the anomalies of interest. Hence, it is critical to investigate and develop few-shot learning for network anomaly detection. In real-world scenarios, few labeled anomalies are also easy to be accessed on similar networks from the same domain as of the target network, while most of the existing works omit to leverage them and merely focus on a single network. Taking advantage of this potential, in this work, we tackle the problem of few-shot network anomaly detection by (1) proposing a new family of graph neural networks -- Graph Deviation Networks (GDN) that can leverage a small number of labeled anomalies for enforcing statistically significant deviations between abnormal and normal nodes on a network; and (2) equipping the proposed GDN with a new cross-network meta-learning algorithm to realize few-shot network anomaly detection by transferring meta-knowledge from multiple auxiliary networks. Extensive evaluations demonstrate the efficacy of the proposed approach on few-shot or even one-shot network anomaly detection.